Shallow Embedding Models for Heterogeneous Graphs

In previous articles, I gave an introduction to graph representation learning and highlighted several shallow methods for learning homogeneous graph embeddings. This article focuses on shallow representation learning methods for heterogeneous graphs.
While homogeneous networks have only one type of nodes and edges, heterogeneous networks contain different types of nodes or edges. So, a homogeneous network can also be considered as a special case of a heterogeneous network. Heterogeneous networks, also called heterogeneous information networks (HIN), are ubiquitous in real-world scenarios. For example, social media websites, like Facebook, contain a set of node types, such as users, posts, groups and, tags. By learning heterogeneous graph embeddings, we learn low-dimensional representations of the graph while preserving the heterogeneous structures and semantics for the downstream tasks (such as node classification, link prediction, etc.).
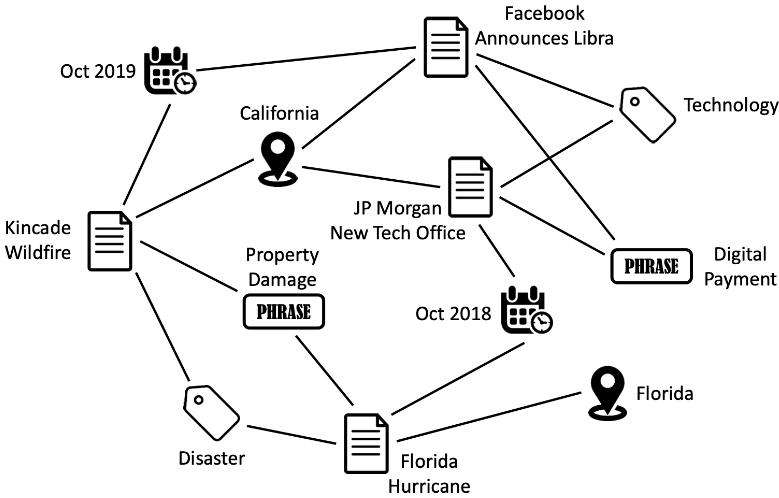
The above figure shows a toy example of a heterogeneous network built from NYTimes data. It has news articles, categories, phrases, locations, and datetimes as nodes1. These nodes are connected through specific types of edges, such as $article \xrightarrow{\mathnormal{\text{belongs to}}} category$, $article \xrightarrow{mentions} location$, $category \xrightarrow{includes} article$, etc.
Heterogeneous networks (HGs) can also be constructed by fusing information across multiple data sources. For example, Google may fuse user information from Google Search, Gmail, Maps, etc. to create a HIN with nodes such as users, keywords, locations, etc. Similarly, Meta may fuse partial views of user information across social network platforms like Facebook and Instagram into a single HIN.
Definitions
Information Network
An information network is an abstraction of the real world and is defined as a directed graph $G = (V,E)$ consisting of a set of nodes (or objects) and edges (or links/relations). Each node $v \in V$ belongs to one particular node type in the node type set $A: \varphi(v) \in A$, and each edge $e \in E$ belongs to a particular edge type in the edge type set $R: \psi(e) \in R$. Here $\varphi: V \rightarrow A$ is the node type mapping function and $\psi: E \rightarrow R$ is the edge type mapping function. If two edges have the same edge type, they share the connect the same type of nodes as well.
Heterogeneous graph
A heterogeneous graph (HG), also called heterogeneous information network (HIN), is defined as a network $H = [V,E,X,Y,\varphi,\psi]$ with multiple types of nodes and/or edges. Each node $v_i$ and each edge $e_{ij}$ is potentially associated with an attribute $X_i$ and $Y_{ij}$ respectively. Given $A$ and $R$ represent the node types and edge types respectively, in HIN: $A + R > 2$.
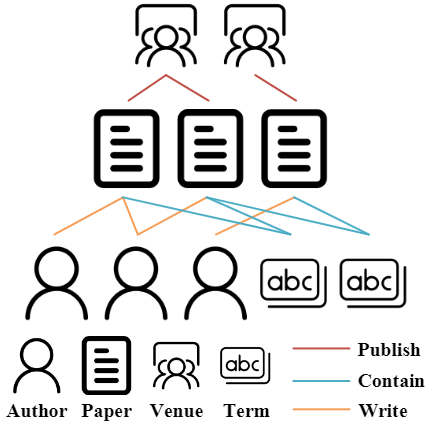
The figure above shows an example of a HIN with four node types (author, paper, venue, and term) and three edge types (author-write-paper, paper-contain-term, and conference-publish-paper)2.
Network Schema
The network schema for $G$ is defined as a meta template $S=(A,R)$ which can be considered as a directed graph defined over node types $A$ and with edges as relations from $R$. The network schema specifies type constraints on the set of nodes and edges, such that an information network can be considered as a network instance that follows the network schema. These constraints make a heterogeneous network semi-structured and guide the semantic exploration of the network3.
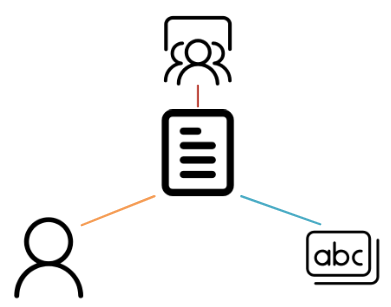
Meta-path
A meta-path is based on a network schema $S$ and is denoted as $m=A_1 \xrightarrow{R_1} A_2 \xrightarrow{R_2} … \xrightarrow{R_l}A_{l+1}$ with node types $A_1, A_2, …, A_{l+1} \in A$ and edge types $R_1, R_2, …, R_{l+1} \in R$.

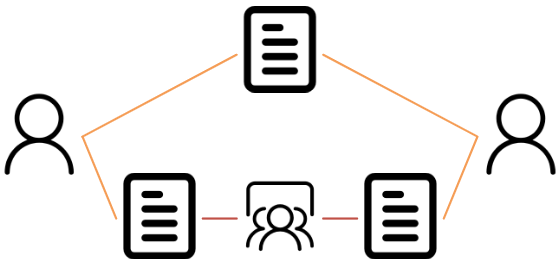
Each meta-path captures the proximity between the nodes on its two ends from a particular semantic perspective. For example, the two meta-paths shown in the above figure capture different semantics. The Author-Paper-Author (APA) meta-path indicates the co-author relationship, while Author-Paper-Conference-Paper-Author (APCPA) represents the co-conference relation.
Limitations of Meta-paths
As we will see later, a lot of HG representation learning algorithms model the different proximities indicated by meta-paths. However, there are also a few drawbacks to using meta-paths:
- Meta-paths have to be manually customized based on task and dataset, hence requiring domain knowledge.
- They fail to capture more complex relationships such as motifs, i.e. patterns of interconnections occurring in complex networks at numbers that are significantly higher than those in randomized networks4.
- The usage of meta-path is limited to the discrete space. So, if two vertices are not structurally connected in the graph, metapath-based methods cannot capture their relations.
Meta-graph
A meta-graph is a directed acyclic graph (DAG) composed of multiple meta-paths with common nodes. Metagraph-based methods can incorporate complex structures like motifs.
Heterogeneous graph embedding
Heterogeneous graph embedding, or heterogeneous node embedding (HNE), learns a function $\Phi: V \rightarrow \mathcal{R}^d$ that maps the nodes $v \in V$ in HG to a low-dimensional Euclidean space with $d \ll |V|$. These latent representations (i.e. embeddings) of each node preserve the network topological information.
Why can’t we just use homogeneous learning methods?
Previously, we discussed shallow methods for homogeneous graph representation learning. The techniques mentioned in that article preserve graph structures (such as first-order, second-order, higher-order, or community structures), but cannot be directly applied to HGs due to the heterogeneity and richer semantics of HG data.
Complex Structure
The local structure of one node in HG can change drastically depending on the type of selected relation which leads to different neighbors. So the structure in HG is highly semantic-dependent, such as a meta-path structure. Some research works utilize similarity measures that not only consider the structural similarity of two nodes but also consider the meta-path connecting the two nodes.
Heterogeneous Attributes
In HG, different types of nodes and edges have different attributes which are located in different feature spaces. To effectively fuse the attributes of neighbors HNE methods have to overcome this heterogeneity.
Application Dependent
Constructing an effective HG may require sufficient domain knowledge of the target application. Unlike, homogeneous networks, HGs do not have a well-defined structure, hence capturing structural properties through meta-paths requires careful designing.
Learning HG Embeddings
In the article, we will be focusing on the shallow methods for heterogeneous graph representation learning. These learning methods preserve the heterogeneous graph structure and semantics in lower-dimensional space and often output an embedding lookup table in a transductive fashion. These methods utilize the following three structures to capture semantic information from different perspectives: links, paths, and subgraphs.
Link-based HG Embedding
PME
Chen et al.5 proposed the Projected Metric Embedding (PME) method based on metric or distance learning to capture both first-order and second-order proximities in a unified way. They noted that some of the earlier methods for learning HNE were based on the dot-product proximity calculation between nodes in the low-dimensional space. As the dot-product does not meet the triangle inequality, these methods were limited to only preserving the first-order proximity. For example, if both the vertices a and b are close to c, these methods couldn’t capture the fact that a and b are also close to each other.
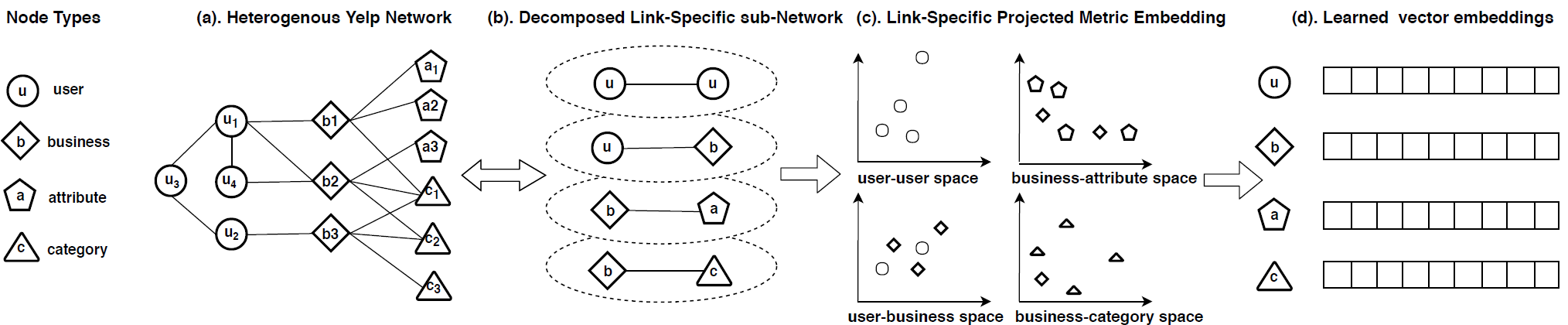
PME models objects and relationships in distinct spaces, i.e. one shared object space and multiple relation-specific object spaces, and performs Euclidian distance calculation in those spaces. In the example above, there are 4 types of nodes (user, business, attribute, and category), and 4 relations (user-user, user-business, business-attribute, and business-category). This network is then decomposed into 4 bipartite networks based on the 4 relations. Each bipartite network is projected to a relation-specific semantic space and then joint learning is applied to multiple semantic-specific Euclidean spaces. This captures heterogeneity by allowing some objects that are far away from each other in the object space to be close to each other in the relation-specific spaces. A margin-based triplet loss function is used to make the node pairs connected by a relation to be closer to each other than other node pairs without that specific relation.
$$ \mathcal{L} = \sum_{r \in R}\sum_{(v_i,v_j) \in E_r}\sum_{(V_i,v_k) \notin E_r} [\xi + S_r(v_i,v_j)^2 - S_r(v_i,v_k)^2] $$
Here $\xi$ denotes the margin, and $S$ is the distance function between the pairs. There are similar methods that exploit the relation-specific matrix to capture link heterogeneity. For example, the Embedding of Embedding (EOE) method for coupled HGs, and HeGAN that is based on GANs. Also, methods like Aspect Embedding (AspEM) and HIN Embedding via Edge Representations (HEER) drop the distance metric and instead maximize the probability of observed relations (links).
PTE
Tang et. al.6 proposed Predictive Text Embeddings (PTE) for learning low-dimensional word embeddings through a heterogeneous text network. The input HG contains words, documents, and labels as the nodes and connections between them as edges. The authors first project this HIN into several homogeneous/bipartite networks as shown below.
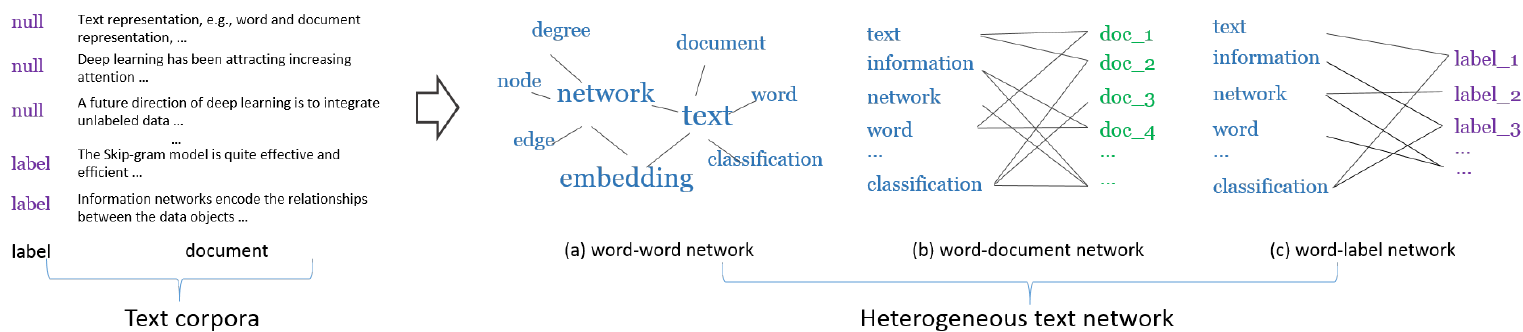
PTE then applies LINE (from the same authors), which preserves the first- and second-order structures, to jointly optimize the bipartite network embeddings to generate a single HNE. The loss function simply minimizes the negative log-likelihood of the different bipartite networks:
$$-\sum_{(i,j) \in E_{ww}} w_{ij} \log{p(v_i|v_j)} -\sum_{(i,j) \in E_{wd}} w_{ij} \log{p(v_i|d_j)} -\sum_{(i,j) \in E_{wl}} w_{ij} \log{p(v_i|l_j)}$$
MNE
Zhang et al.7 proposed Multiplex Network Embedding (MNE) method to represent information from multiple relations into a unified embedding space. Here multiplexity simply refers to multifaceted relationships between two nodes. For example, in a social network, two people may have different kinds of interactions with each other, such as sending messages, sharing content, and money transferring. For each node, the authors propose learning a high-dimensional embedding vector, which is shared across all layers of the multiplex network, and additional lower-dimensional embeddings corresponding to each type of relation. To align these different embeddings, they introduce a global transformation matrix for each layer of the network. Separate random walks (using skip-gram) are performed corresponding to each relation to learn the embeddings.
Methods like PME preserve the proximity of links, while those like MNE, preserve the proximity of nodes. Hence they are limited to only using first-order information, such as author-paper, paper-term, and paper-venue in the example HIN mentioned earlier.
Path-based HG Embedding
To capture higher-order relations, such as author-author, paper-paper, and author-conference in the earlier example HIN, path-based methods utilize more complex semantic information. An underlying theme among these methods is to reduce complexity by choosing higher-order relations with rich semantics, such as meta-paths.
Metapath2vec/ Metapath2vec++
Dong et al.8 proposed a meta-path-based random walk that can be applied to HGs and can capture both first-order and high-order proximities. As there can be a large number of high-order relations, the authors focus on the key idea which is to design specific meta-paths which restrict the transitions to only the specified types of nodes. These paths resulting from meta-path-guided random walks are fed to a skip-gram model (with negative sampling) for learning the representation of nodes by maximizing the probability of the context nodes, given the starting node.
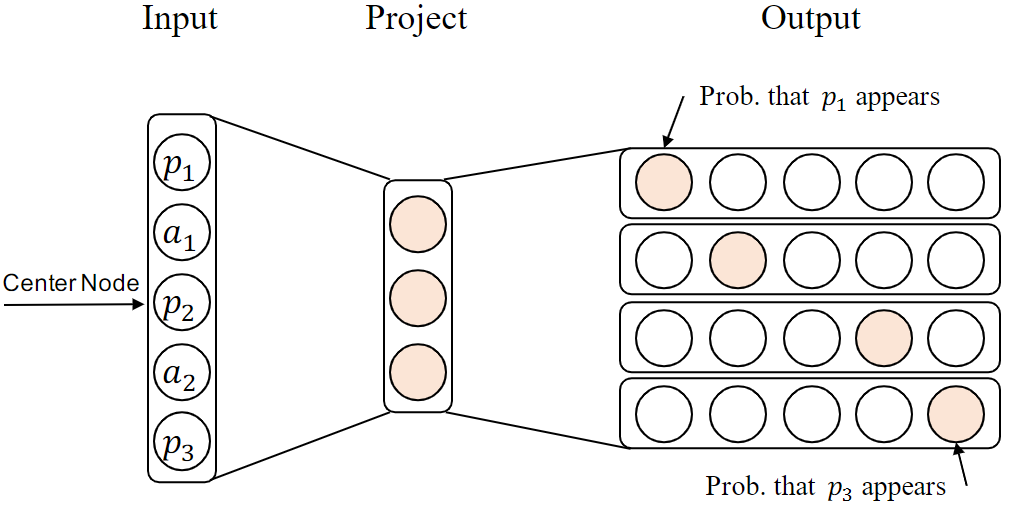
The objective function of heterogeneous skip-gram is stated as: $arg max_{\theta} \sum_{v \in V} \sum_{t \in T_V} \sum_{c_t \in N_{t(v)}} \log{P(c_t|v;\theta)}$, where $t$ denotes the node type, $c_t$ is the context, $N_{t(v)}$ denotes the neighborhood of node $v$, and $P(c_t|v;\theta)$ is a softmax function.
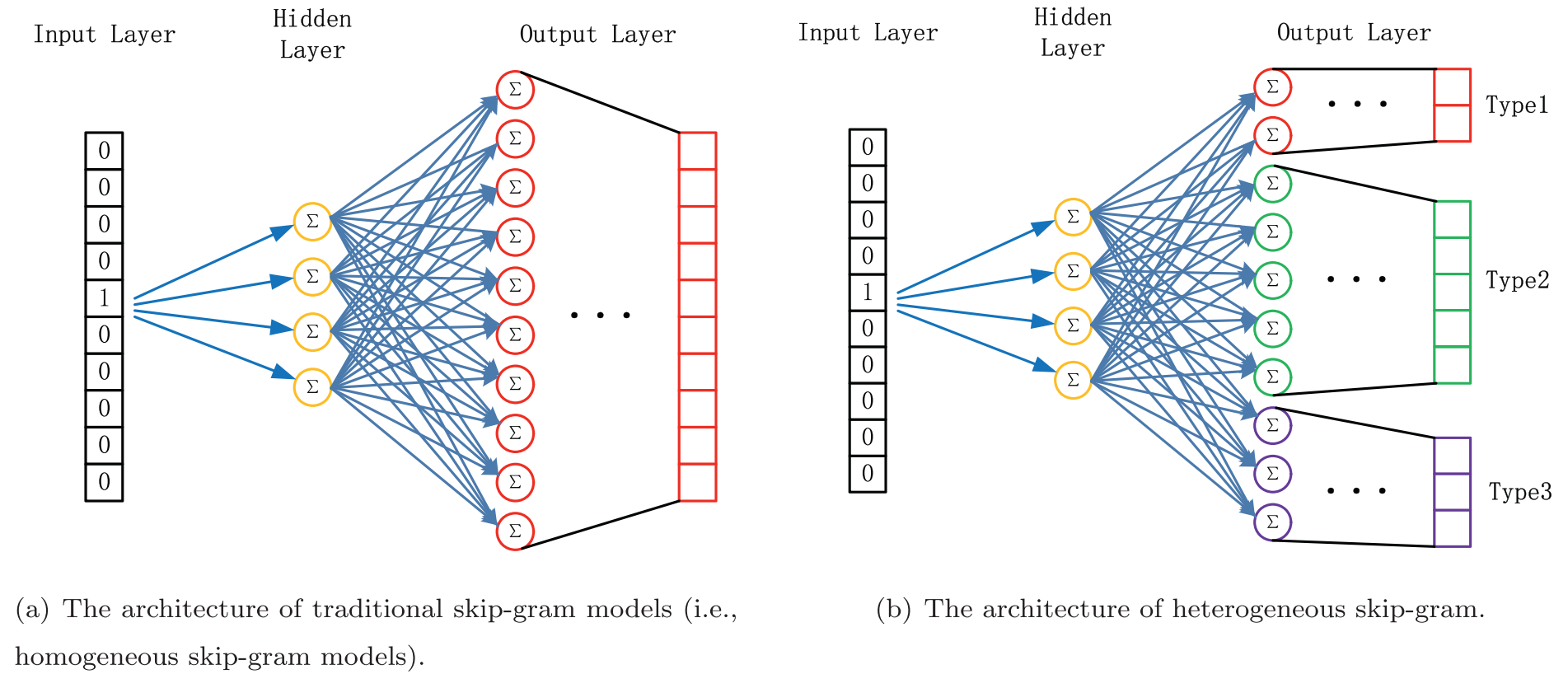
The authors also propose a metapath2vec++ algorithm that samples the negative nodes of the same type as the central node by maintaining separate multinomial distributions for each node type in the output layer of the skip-gram model. The official code and dataset for this method are available on GitHub.
One extension of this algorithm is the HeteSpaceyWalk method in which the authors replace the random walk with a heterogeneous personalized spacey random walk to make the process more scalable.
HIN2vec
In HIN2vec, Fu et al9 proposed a hybrid approach that combines first-order relation and high-order relation (i.e. meta-paths). As shown in the figure below, HIN2vec works in a multi-label classification style by predicting whether two given nodes are connected by a meta-path. It uses a neural network and binary cross-entropy loss to fuse the one-hot vector representations of the two nodes $i$ and $j$ and the relation $r$. The jointly learned parameter matrices $W_I$, $W_J$, and $W_R$ are the mapping matrices that output the latent vectors. Compared to random-walk-based methods, HIN2vec can simultaneously integrate multiple meta-paths.
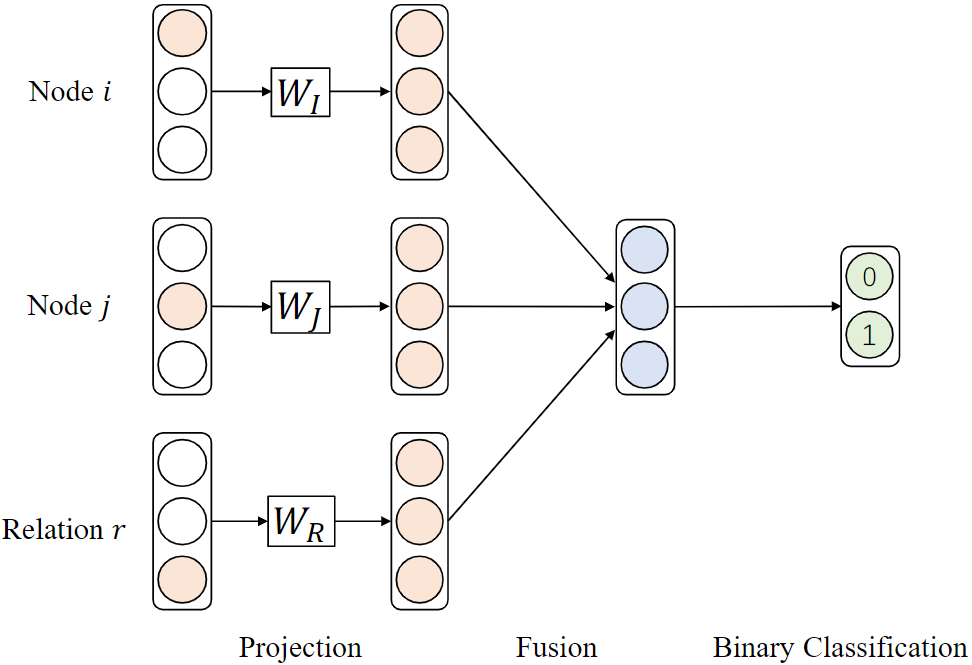
JUST
In Jump and Stay strategy (JUST) Hussein et al.10 proposed random walks that do not rely on predefined meta-paths. Meta-paths require prior knowledge from domain experts and often require additional computation to combine meta-paths shorter than the predefined length. A vanilla random walk on a heterogeneous network will be biased towards the highly visible node type. To overcome this, at each step JUST tries to probabilistically balance between jumping to the next node of a different type or staying in the domain of the same node type.
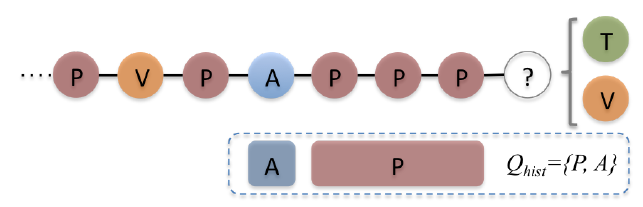
While jumping, their method tries to pick a domain different from the last m visited types. Configuring this value of m allows us to balance the node distribution over different types. The probability of staying is controlled using an exponential decay function which effectively balances the number of heterogeneous and homogeneous edges in a truncated random walk. Finally, a skip-gram model is used to generate the node embeddings.
In a similar fashion, a method called BHIN2vec balances the influence of different relations on the embedding of a node by adjusting the training ratio of different tasks.
Subgraph-based HG Embedding
Utilizing subgraphs in HNE can help in capturing complex structural and semantic relationships in an HG. The two widely used subgraphs in HG are: meta-graph to reflect the high-order similarity between nodes, and hyperedge to connect a series of closely related nodes. In this section, we take a look at prominent algorithms based on these two subgraph structures.
MetaGraph2Vec
In metagraph2vec, Zhang et al.11 proposed a way to generate heterogeneous node sequences using meta-graph-guided random walks. A meta-graph is a DAG defined on the given HIN schema which has only a single source node and a single target node. Real-world HINs often have to deal with sparse or missing connections. As the following example shows, meta-paths $\mathcal{P_1}$ and $\mathcal{P_2}$ will fail to capture path $a_1 \rightarrow a_4$ if the highlighted link is missing. However, the meta-graph $\mathcal{G}$ provides a richer structural context and is able to perform this random walk. This shows the meta-graph’s capability to match more paths in a sparse context.
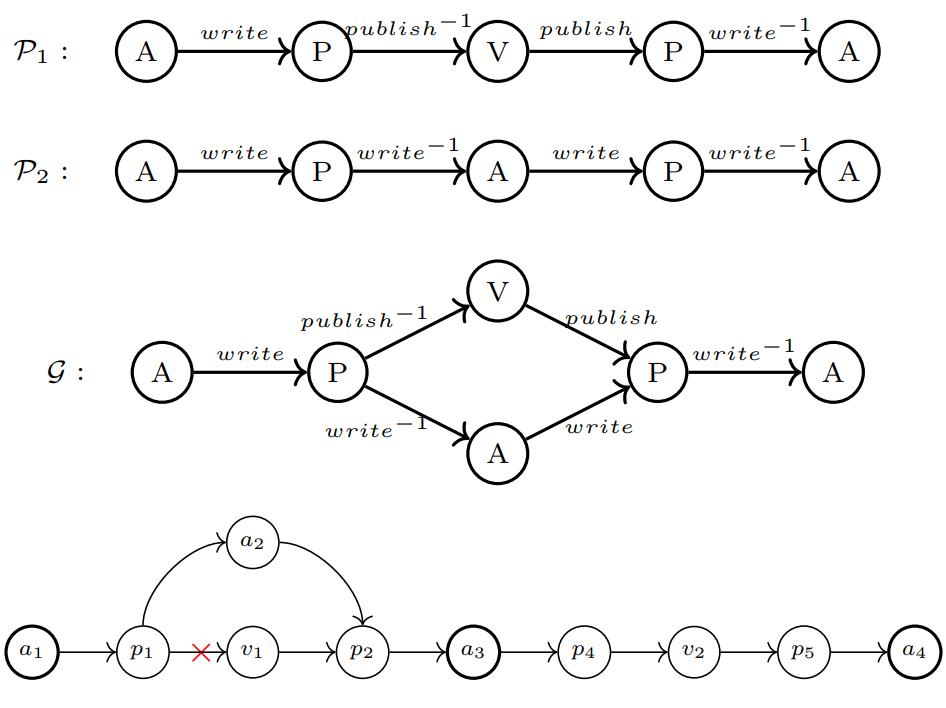
The node sequences generated from this meta-graph-guided random walk are used to learn HNE through a heterogeneous skip-gram model. The authors also utilize a heterogeneous negative sampling method similar to the metapath2vec++ method.
One extension of metagraph2vec is the mg2vec method that jointly learns embeddings for nodes and meta-graphs. In this method, meta-graphs assume a more active role in the learning process by mapping themselves to the same embedding space as the nodes.
DHNE
Tu et al.12 proposed Deep Hyper-Network Embedding (DHNE) model to embed hyper-networks with indecomposable hyperedges. In a hyper-network, the concept of edge goes beyond pairwise relationships to three or more objects being involved in each relationship. DHNE presents a deep model to produce a non-linear tuple-wise similarity function. The first layer in their architecture is an autoencoder that is designed to learn latent embeddings and preserve the second-order proximity. This is followed by a fully-connected layer that concatenates the learned embeddings and models a tuple-wise similarity function to preserve the first-order proximity.
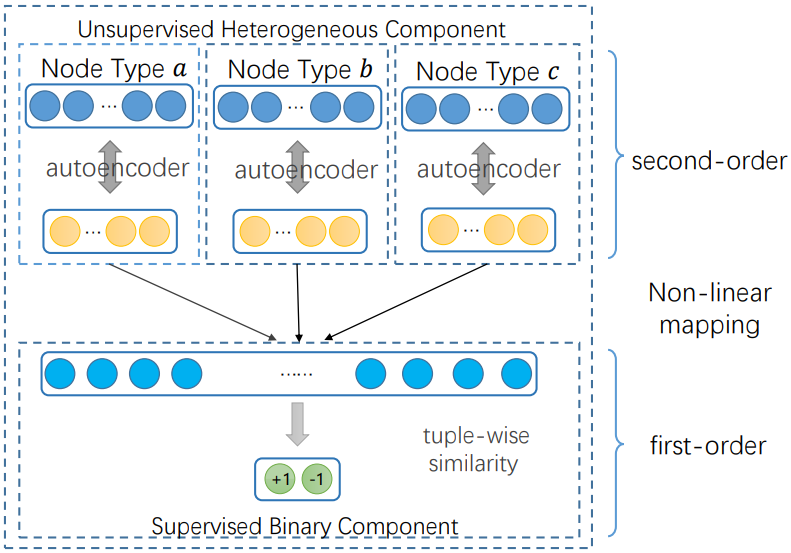
Example Applications
Rating Prediction with HERec
Shi et al.13 proposed a HIN embedding-based recommendation approach, called HERec. Earlier HIN-based recommenders mostly used path-based semantics (such as meta-path-based similarity) between users and items in HIN. These similarities mainly characterize HIN semantic relations, and may not be directly applicable to recommendations. To address this, HERec uses a meta-path-based random walk strategy to generate node sequences. As shown in the figure below, these node sequences are then filtered so each sequence only contains the nodes with the same type as the starting node.
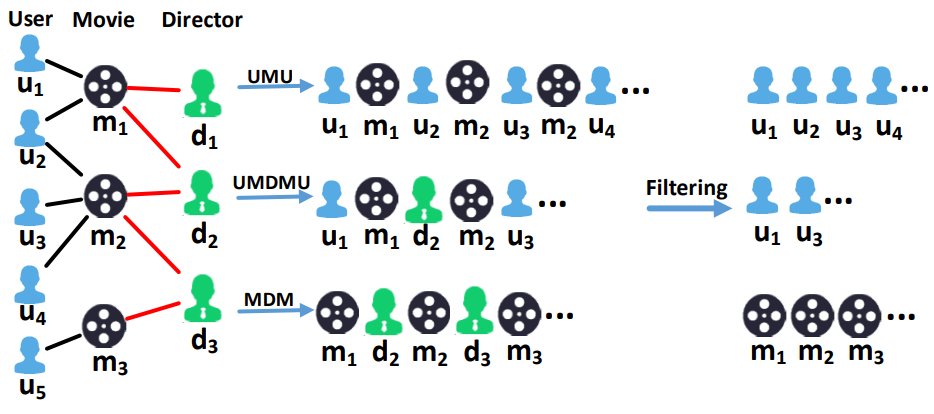
These node sequences are then used in a node2vec algorithm to learn node (user/item) embeddings. Embeddings learned through different meta-paths are fused together using three different fusion techniques (linear, personalized linear, and non-linear). Finally, the embeddings are fed into a matrix factorization algorithm, which is jointly trained with the fusion function for a rating prediction task.
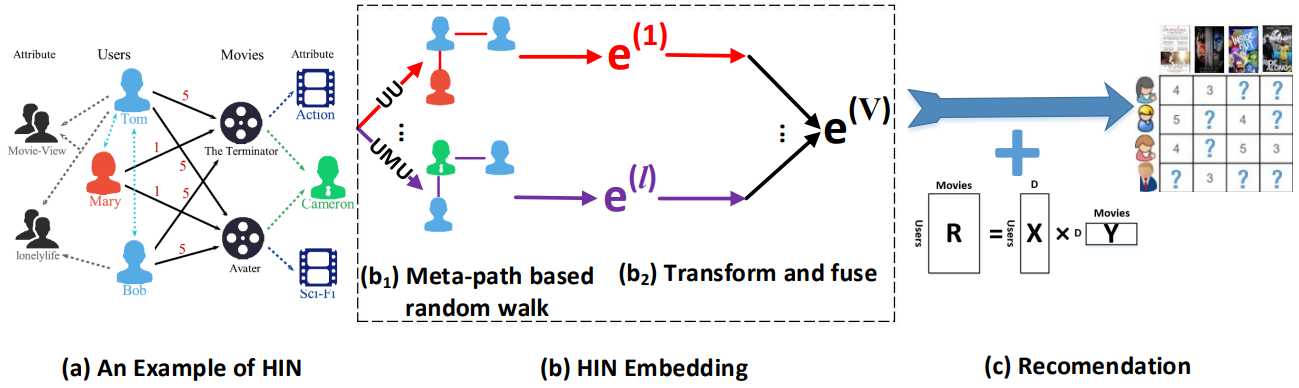
HIN-based unified embedding model for Recommendation (HueRec) is a related approach that unifies the interaction between different meta-path embeddings through an end-to-end learnable framework.
Malware Detection with HinDroid
Hou et al.14 proposed a HIN-based malware detection system for the Android OS. First, they created a HIN with apps and APIs invoked by these apps as nodes and the corresponding API calls as links between the nodes. To extract the API calls, each Android Application Package (APK) is unzipped to retrieve the corresponding dex (Dalivik executable) file. This dex file is converted to an intermediate code using a de-compiler. API calls are extracted from this intermediate code and relationships between APIs are defined based on the corresponding code blocks, packages, and the invoke methods.
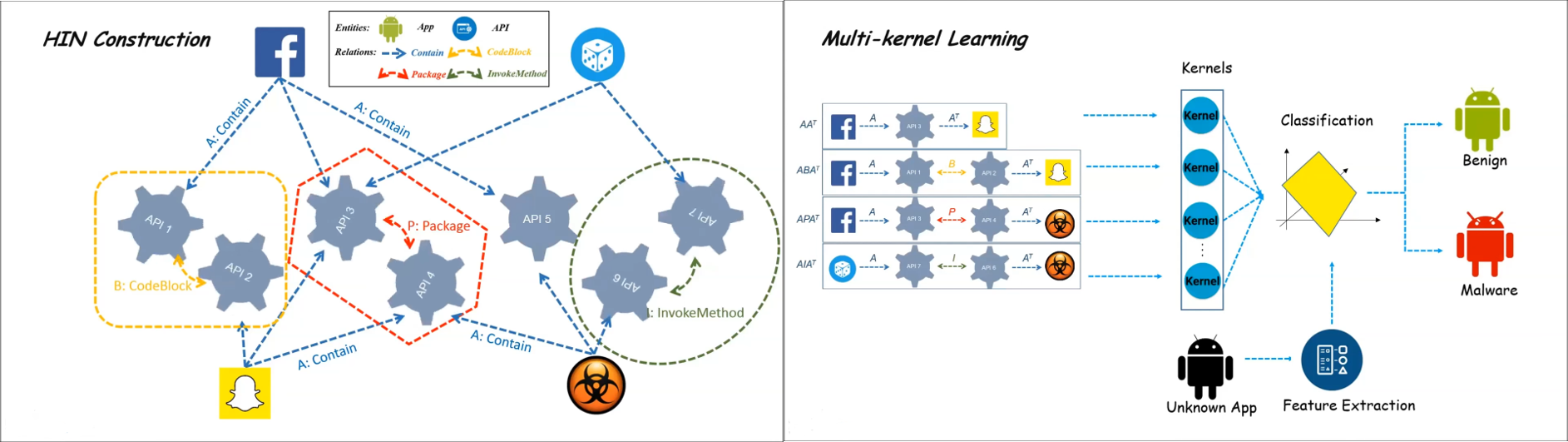
Next, the authors used a meta-path-based similarity approach to characterize the semantic relatedness of these nodes. These similarities between apps capture whether the apps are using the same APIs, and also whether the APIs have similar usage patterns. They defined a meta-path $App \xrightarrow{contains} API \xrightarrow{\text{same code block}} API \xrightarrow{contains^{-1}} App$ to compute the similarity between two apps based on API calls and types of API calls. Different similarities are then aggregated using multi-kernel (SVMs) learning, and then each meta-path is automatically weighted by the learning algorithm. Finally, these extracted features are fed to a binary classification model to label the app as either benign or malicious. HinDroid has been incorporated into the scanning tool of Comodo Mobile Security products.
Fraud Detection with HACUD
Hu et al.15 from Ant Financial Group proposed a fraud detection model in credit payment services, called the Hierarchical Attention mechanism based Cash-out User Detection model (HACUD). First, they model the payment service scenario as an attributed HIN by exploiting the interaction relations between users. Their HIN consists of three types of nodes: users (U), merchants (M), and devices (D). Along with attributes, HIN also contains rich interactions among nodes, represented as links. The fraudulent user not only has abnormal attributes but also abnormal behavior in interaction relations, such as simultaneous transactions or transactions with particular merchants (for example, pre-paid card sellers).
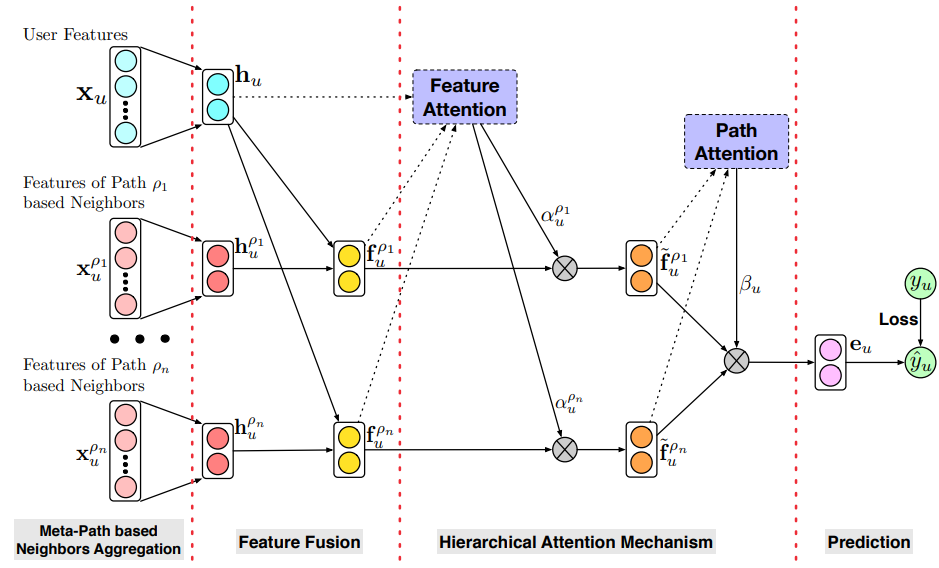
Next, meta-path (UMU and UU) based neighbors are used to exploit structure information and generate node sequences from neighbors. The authors hypothesize that node attributes and meta-paths have different importance, which can be learned through a hierarchical attention mechanism. The first layer of this mechanism models the contribution of attributes while the second layer does the same for the different meta-paths. Finally, a fraudulent user probability is calculated based on aggregated feature representations via an MLP layer. This classification model is trained with a maximum likelihood objective and SGD.
Toward Graph Neural Networks
The shallow methods, that we discussed in this article, are parallelizable and preserve the graph structures. These methods can further improve the training speed through negative sampling. But they also suffer from the problems like huge memory requirements for storing embeddings for individual nodes, and the inability to predict the embedding for a new node in an inductive setting. Also, one of the biggest motivations for representation learning is to avoid manual feature engineering efforts, but as we saw, a lot of these methods require manually customizing meta-paths or their variants (like meta-graphs) specific to tasks and datasets. These problems can be overcome by using graph neural networks (GNNs). In the future set of articles, I will go over GNNs and describe how they fully unleash the power of automatic representation learning while avoiding any manual meta-path design.
Summary
A lot of entity interactions in real-world systems can be conceptualized as heterogeneous networks. In this article, we learned several shallow methods for heterogeneous graph representation learning. We learned the relevant fundamental concepts in the HG domain and did a literature review on some of the most popular HNE methods. Finally, the article highlighted several real-world examples of applying these strategies to different industrial applications. In the next set of articles on graph representation learning, I will explain the concept of GNNs.
References
-
Yang, C., Xiao, Y., Zhang, Y., Sun, Y., & Han, J. (2020). Heterogeneous Network Representation Learning: A Unified Framework With Survey and Benchmark. IEEE Transactions on Knowledge and Data Engineering, 34, 4854-4873. ↩︎
-
Wang, X., Bo, D., Shi, C., Fan, S., Ye, Y., & Yu, P.S. (2020). A Survey on Heterogeneous Graph Embedding: Methods, Techniques, Applications and Sources. IEEE Transactions on Big Data, 9, 415-436. ↩︎
-
Shi, C., Li, Y., Zhang, J., Sun, Y., & Yu, P.S. (2015). A Survey of Heterogeneous Information Network Analysis. IEEE Transactions on Knowledge and Data Engineering, 29, 17-37. ↩︎
-
Milo, R., Shen-Orr, S.S., Itzkovitz, S., Kashtan, N., Chklovskii, D.B., & Alon, U. (2002). Network motifs: simple building blocks of complex networks. Science, 298 5594, 824-7 . ↩︎
-
Chen, H., Yin, H., Wang, W., Wang, H., Nguyen, Q.V., & Li, X. (2018). PME: Projected Metric Embedding on Heterogeneous Networks for Link Prediction. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ↩︎
-
Tang, J., Qu, M., & Mei, Q. (2015). PTE: Predictive Text Embedding through Large-scale Heterogeneous Text Networks. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ↩︎
-
Zhang, H., Qiu, L., Yi, L., & Song, Y. (2018). Scalable Multiplex Network Embedding. International Joint Conference on Artificial Intelligence. ↩︎
-
Dong, Y., Chawla, N., & Swami, A. (2017). metapath2vec: Scalable Representation Learning for Heterogeneous Networks. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ↩︎
-
Fu, T., Lee, W., & Lei, Z. (2017). HIN2Vec: Explore Meta-paths in Heterogeneous Information Networks for Representation Learning. Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. ↩︎
-
Hussein, R., Yang, D., & Cudré-Mauroux, P. (2018). Are Meta-Paths Necessary?: Revisiting Heterogeneous Graph Embeddings. Proceedings of the 27th ACM International Conference on Information and Knowledge Management. ↩︎
-
Zhang, D., Yin, J., Zhu, X., & Zhang, C. (2018). MetaGraph2Vec: Complex Semantic Path Augmented Heterogeneous Network Embedding. ArXiv, abs/1803.02533. ↩︎
-
Tu, K., Cui, P., Wang, X., Wang, F., & Zhu, W. (2017). Structural Deep Embedding for Hyper-Networks. ArXiv, abs/1711.10146. ↩︎
-
Shi, C., Hu, B., Zhao, W.X., & Yu, P.S. (2017). Heterogeneous Information Network Embedding for Recommendation. IEEE Transactions on Knowledge and Data Engineering, 31, 357-370. ↩︎
-
Hou, S., Ye, Y., Song, Y., & Abdulhayoglu, M. (2017). HinDroid: An Intelligent Android Malware Detection System Based on Structured Heterogeneous Information Network. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ↩︎
-
Hu, B., Zhang, Z., Shi, C., Zhou, J., Li, X., & Qi, Y. (2019). Cash-Out User Detection Based on Attributed Heterogeneous Information Network with a Hierarchical Attention Mechanism. AAAI Conference on Artificial Intelligence. ↩︎
Related Content





Did you find this article helpful?