Representing Users and Items in Large Language Models based Recommender Systems

Introduction
Recommendation systems play a vital role in several online platforms like search engines, e-commerce websites, content streaming, targeted advertising, etc. These systems use information about the users, items and their past interactions to make personalized recommendations.
Recently, there has been a growing interest in research community to utilize large language models (LLMs) for building recommender systems. LLMs rely on instruction data in natural language for their pre-training, prompting and fine-turning. Hence they require recommendation tasks to be rephrased as language generation task, and the user, item and interaction data to be transformed into natural language corpora.
However, effectively representing users, items and their interactions into natural language can be challenging. This article explains such representation methods along with some recent research work that aim to create LLM-compatible representations.
Should You Use ID Features or Not?
Traditionally, users and items in recommender systems are represented with ID tags, such as user ID, movie ID, that inherently do not contain any semantic information. These unique IDs represent distinct users and items and have been a critical component of state-of-the-art recommendation solutions. For example, factorization-based methods use user IDs to build user-item associations and item-based collaborative filtering methods use item IDs to calculate similarities between items from user-item behavior data. Deep Learning based recommender systems subsequently convert these IDs into learned embedding vectors.
Although these ID features are ubiquitous in recommender systems, they also have several shortcomings. For example, these ID features fail to provide enough information for cold-start items, do not leverage technical advances in other communities like NLP and Computer Vision, and lack interpretability 1. These IDs are also non-transferable across different domains, so they hinder cross-domain recommendation capabilities.
Some prior research has indicated that LLM-based recommenders can get better at in-domain recommendations by using ID features. However, a desirable goal for training these large language models is to be able to have a foundational model that can be directly used for various downstream recommendation tasks. And, by using ID features these models sacrifice some of the cross-domain generalization ability. So whether to use the ID features or not remains an open question 2.
Natural Language Representations
Approaches based in ID-free paradigm usually leverage the generality of natural language text for representing users and items. For a user, this textual representation could be formed using personalized prompt templates with data such as user demographic, user reviews and/or a sequence of items from their interaction history. The following example shows one such representation used by Alibaba3.

For an item, we could utilize one (for example, movie title) or more of its attributes, such as title, description, category, etc. Following example is taken from a method published by Amazon, that shows key-value attributes pairs flattened to represent an item4.
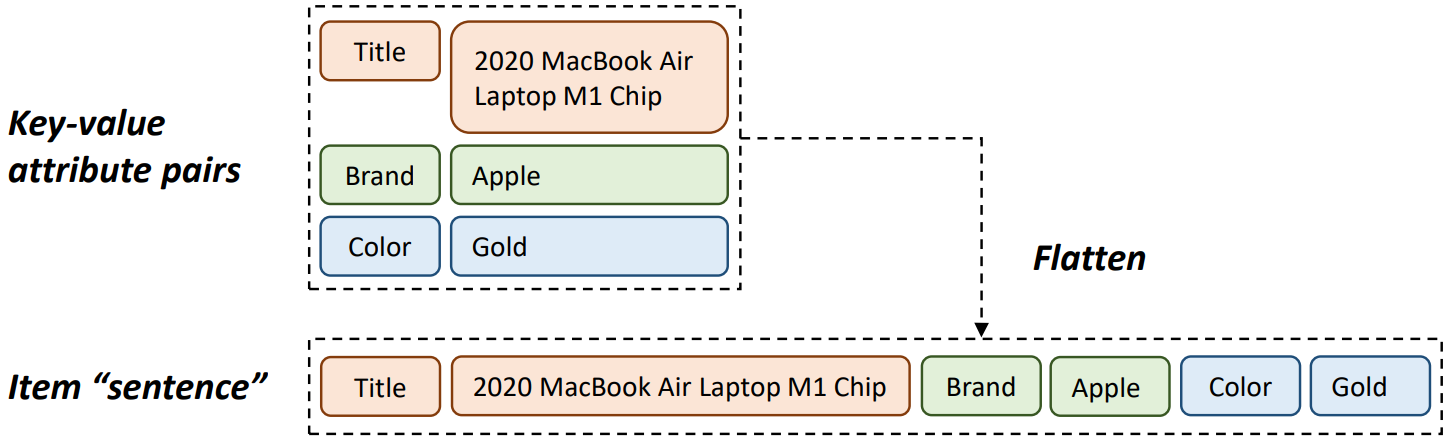
Using such metadata-based representations can lead to cross-domain recommendation capabilities. But there are also several downsides of using these natural language representations. For example, excessively long item titles can lead LLMs to hallucinate when generating title for the recommended item. Also, some title overlaps could be misleading from semantic perspective, for example, The Ring and The Lord of the Rings are very different movies despite some token overlap in their titles.
ID-Based Representations
The following discussion assumes that the user is being represented using the sequence of items from their historical interactions. Hence, the focus of this section is mainly on different ways to represent items in an textual ID like format.
Rule-based Representations
Random Numbers
We can assign a randomly generated unique number as ID for each item in the corpus. For example, in the P5 paper5 the authors represent users and items as random IDs in input prompts as shown below.

However, this approach leads to a lot of overlaps between unrelated items after tokenization. In the above example a SentencePiece tokenizer will split item_3148 into tokens items, _, 31, 48 and item_3179 into item, _, 31, 79. The two items will share a common sub-token 31 even when the two items may be completely unrelated. This unintended overlap can bias LLMs to learn arbitrary relationships.
Independent Tokens
The P5 paper also points out that we can represent users and items by single and independent extra tokens, such as <item_3148> and <item_3179>. The P5 model architecture has a whole-word embedding input layer that assigns the same whole-word embedding for tokens from the same ID. The whole word embedding can also be added to the token embeddings.
This strategy does not make any prior assumption about the items, and suffers from the fact that all items are considered independent from each other for assigning IDs. Also, these extra tokens can significantly increase the size of vocabulary in large datasets leading to additional training time and suboptimal performance.
Sequential Indexing
Hua et al.6 proposed an approach where items in users’ interaction history data are assigned consecutive numerical indices starting from the first user and all the way to the last one.

After tokenization is applied, the consecutive items from a user interaction history will still token-based similarity, such as items 1006 and 1007 will share the sub-token 100 thereby reflecting their co-occurrence.
This approach also suffers from several shortcomings. Not all sequentially indexed items are interacted by the same user. In the above example, 1014 and 1015 did not co-occur, but they share sub-tokens. Different user ordering may lead to different results, so the data has to be chronologically ordered (for example, by interaction time or by number of interactions from each user). Also, this method does not capture the frequency of co-occurrences among different items.
Semantic (Content-based) Indexing
For the ID-based methods mentioned above, tokenization is not meaningful to the LLM. Alternatively, the category metadata of an item can be organized in a hierarchical structure to generate item IDs. As shown below, the non-leaf nodes are simply assigned the category token and the non-leaf nodes are assigned a unique sequence number under its parent category. The ID for an item is simply the concatenation of the path followed from root to the corresponding leaf node.
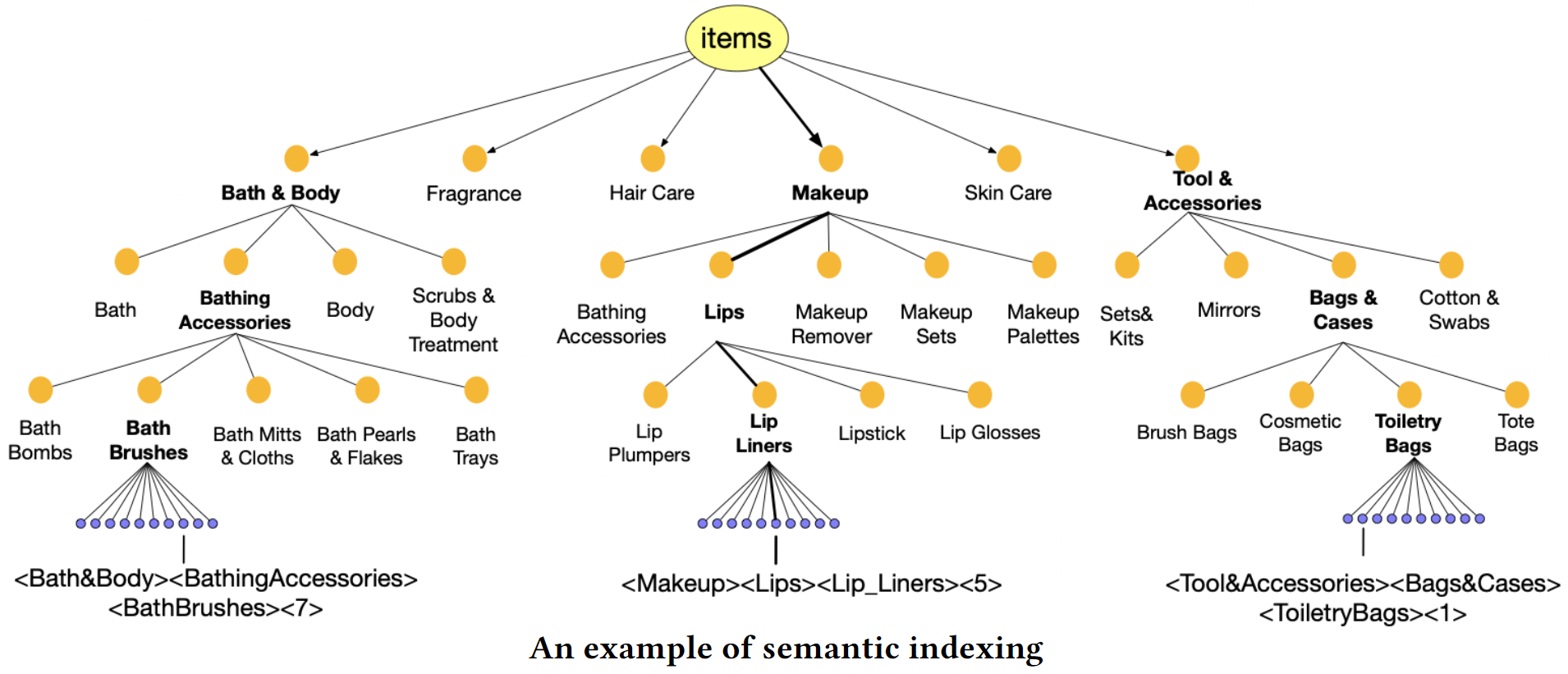
The model leads to a better performance is the item categories naturally lead to a hierarchical structure.
Learned Representations
We can also learn ID representations for items through model-based methods. Similar to the Sequential Indexing method, the main motivation behind these strategies is to ensure that similar items share more tokens and dissimilar items share a minimal amount of tokens.
Applying Quantization to Embeddings
This line of work focuses on assigning an ID to each entity by applying a vector quantization scheme over its dense embeddings. The quantization process converts the embedding vectors into a small set of semantic tokens or (integer) codewords.
RQ-VAE based Method
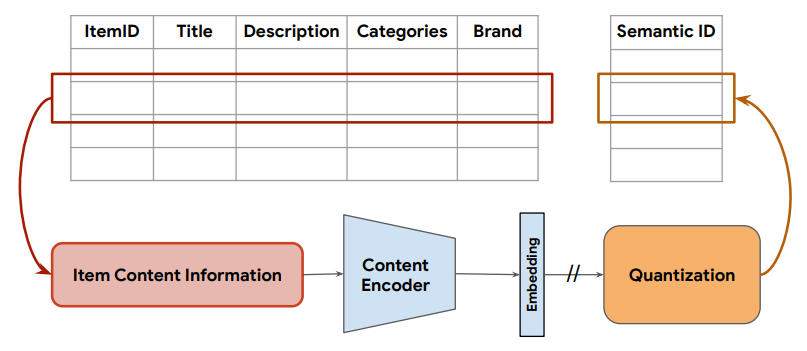
Rajput et al.7 proposed a method TIGER (Transformer Index for GEnerative Recommenders) that represents items using unique ‘Semantic IDs’. These IDs are semantically meaningful tuples of codewords that serve as unique identifiers for respective items. To create these IDs, first, the associated content information (such as titles, descriptions, etc.) is used to generate item embeddings via a pretrained content encoder, such as the Sentence-T5 model. These semantic IDs are then quantized to generate a semantic ID for each item.
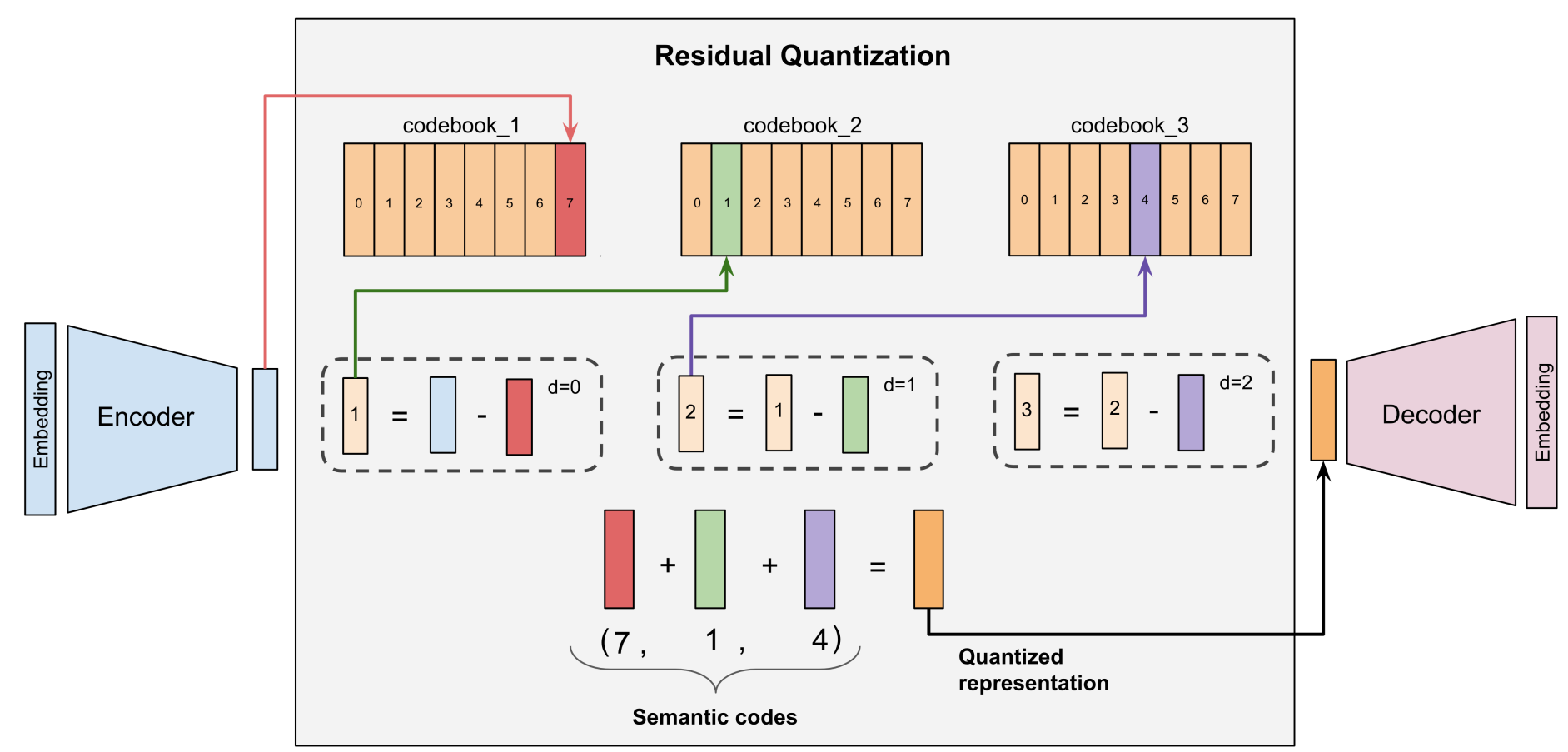
The quantization scheme is implemented through a Residual-Quantized Variational AutoEncoder (RQ-VAE) model. First, the encoder encodes the input embedding x into a latent representation which is then passed to a quantizer. The quantizer learns m number of codebooks to iteratively generate a semantic ID. At each step of the quantizer, the input is mapped to the nearest vector in the codebook, and the corresponding index of the codebook is used to create the next codeword in the semantic ID. The residual of the two vectors is then passed to the next iteration. Finally, a decoder uses the quantized vector to recreate the input x. The three RQ-VAE components are jointly trained, and the authors show that the learned IDs approximate the input from a coarse-to-fine granularity in a hierarchical fashion.
SVD based Method
Petrov et al.8 proposed GPTRec, a generative sequential recommendation model (based on GPT-2) which also applies a quantization scheme, but unlike TIGER doesn’t rely on any side information about the items. Their algorithm takes a user-item interaction matrix and performs a truncated SVD decomposition of it. The resulting item embeddings are normalized to [0, 1] interval, and a small amount of Gaussian noise is added to it. Next, the algorithm quantizes each dimension of the item embeddings into v values. Finally, every $i$th dimension of the quantized embeddings is offset by $v * (i-1)$
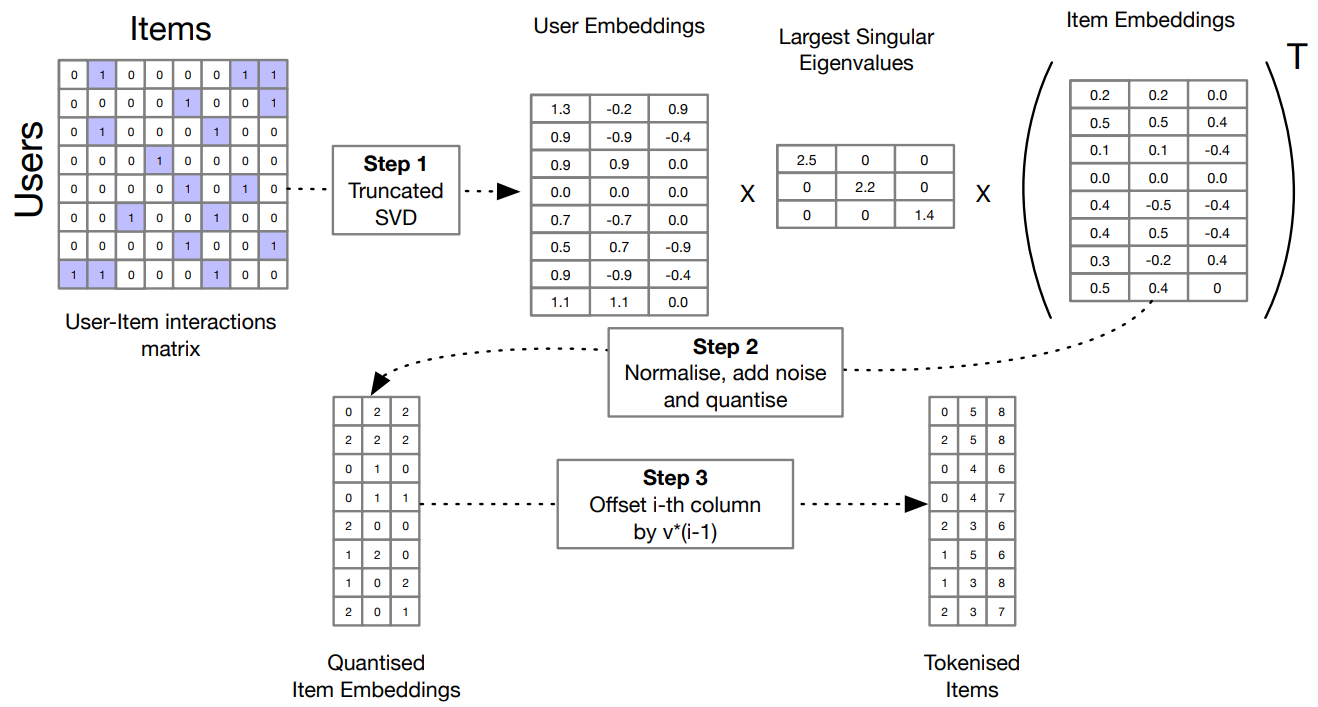
Collaborative Indexing
Hua et al.6 proposed a method which captures the collaborative signals more effectively by assigning more overlapping tokens to items with more frequent co-occurrences. First, a co-occurrence graph of items is created with edge weights indicating the frequency of co-occurrence. The Laplacian matrix of this graph is then used to group nodes into clusters through the spectral clustering method.
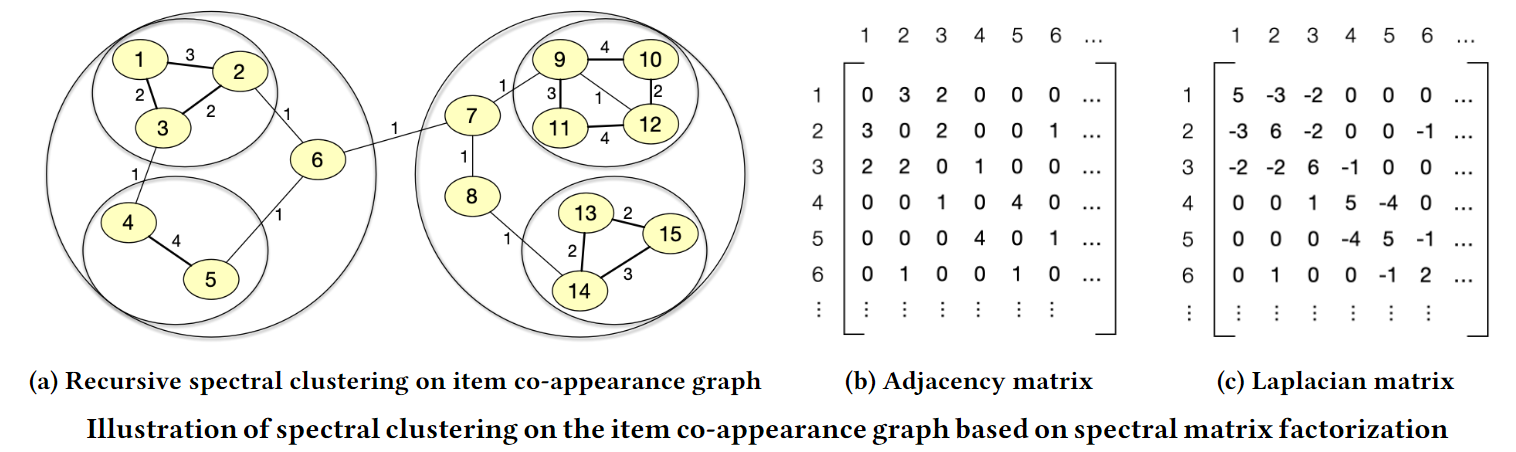
This clustering result can be formulated into a hierarchical tree structure where the non-leaf nodes represent clusters and leaf nodes represent items in a cluster. The number of clusters ($N$) and the maximum number of items in each cluster ($k$) are tunable hyperparameters. As shown below, clusters are enumerated level by level across the whole tree by repeating the range $0$ to $k-1$. Leaf nodes can contain a maximum of $k$ nodes, and are enumerated accordingly. Finally, the ID of an item is simply the concatenation of the cluster path from root and its own leaf token.
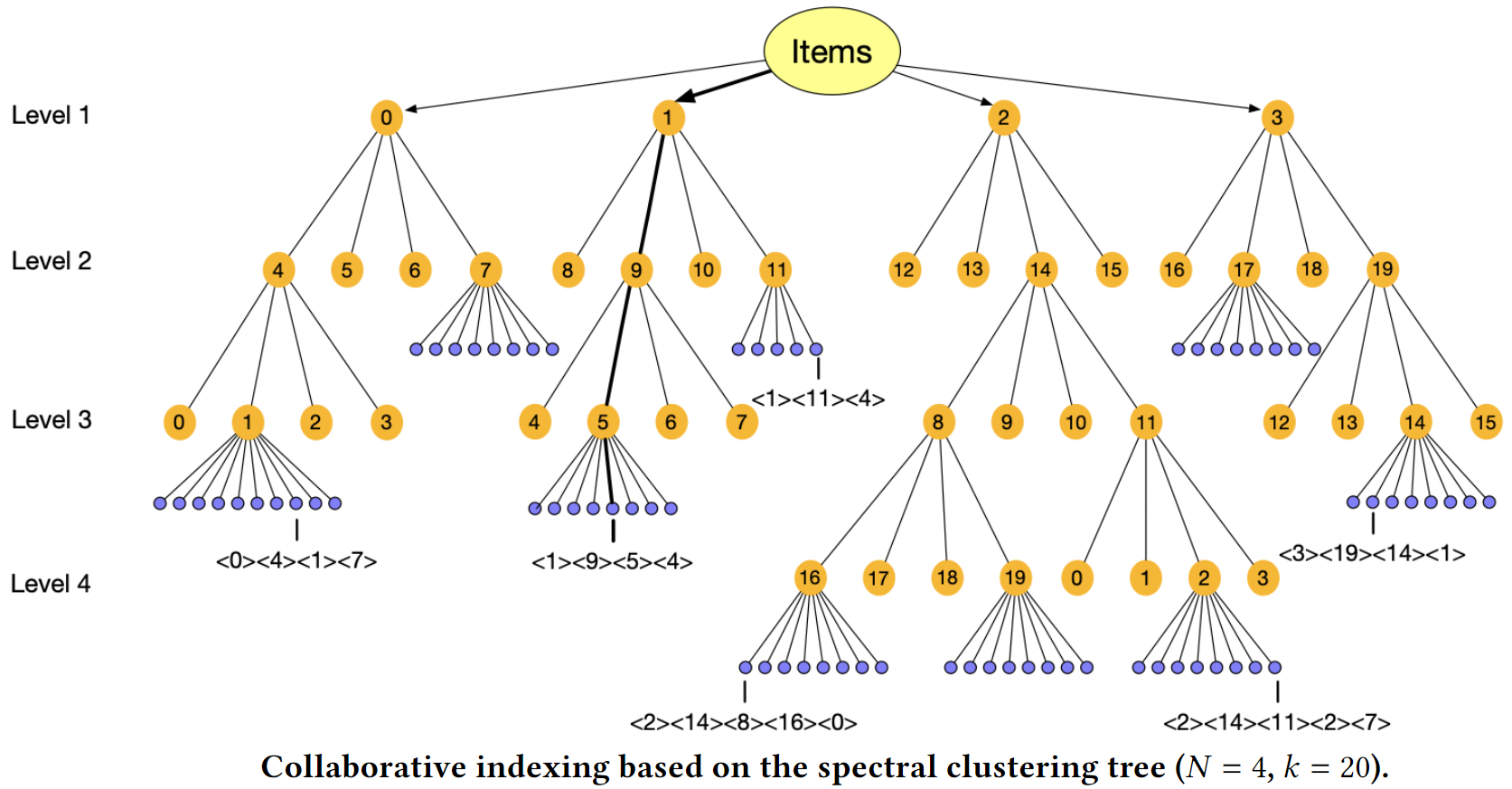
Based on hyperparameter tuning experiments, the authors recommended using values of $N$ and $k$ that lead to an average ID length between 3 and 4.
Hybrid Indexing
A lot of the approaches described above can be combined to create a hybrid indexing strategy to increase the expressiveness of the representations. Through experimentation, Hua et al.6 recommend combining Collaborative Indexing or Semantic Indexing with Independent Tokens (by appending an independent extra token at the end of the collaborative or semantic ID).
Summary
LLMs have emerged as powerful tools for recommendation tasks due to their vast amount of encoded external knowledge and high-quality textural feature representations. These LLMs are given textual instructions for pretraining, prompt tuning and fine tuning. This article highlighted different techniques for representing users and items into personalized prompt templates for generating those instructions.
Related Content

Tuning Large Language Models for Recommendation Tasks
Instruction-tuning Large Language Models (LLMs) usage for building highly effective recommender systems on private data.
Read more...
Zero and Few Shot Recommender Systems based on Large Language Models
Introduction to using Large Language Models for recommendation tasks.
Read more...References
-
Yuan, Z., Yuan, F., Song, Y., Li, Y., Fu, J., Yang, F., Pan, Y., & Ni, Y. (2023). Where to Go Next for Recommender Systems? ID- vs. Modality-based recommender models revisited. ArXiv, abs/2303.13835. ↩︎
-
Lin, J., Dai, X., Xi, Y., Liu, W., Chen, B., Li, X., Zhu, C., Guo, H., Yu, Y., Tang, R., & Zhang, W. (2023). How Can Recommender Systems Benefit from Large Language Models: A Survey. ArXiv, abs/2306.05817. ↩︎
-
Cui, Z., Ma, J., Zhou, C., Zhou, J., & Yang, H. (2022). M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems. ArXiv, abs/2205.08084. ↩︎
-
Li, J., Wang, M., Li, J., Fu, J., Shen, X., Shang, J., & McAuley, J. (2023). Text Is All You Need: Learning Language Representations for Sequential Recommendation. ArXiv, abs/2305.13731. ↩︎
-
Geng, S., Liu, S., Fu, Z., Ge, Y., & Zhang, Y. (2022). Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5). ArXiv. /abs/2203.13366 ↩︎
-
Hua, W., Xu, S., Ge, Y., & Zhang, Y. (2023). How to Index Item IDs for Recommendation Foundation Models. ArXiv, abs/2305.06569. ↩︎ ↩︎ ↩︎
-
Rajput, S., Mehta, N., Singh, A., Keshavan, R.H., Vu, T.H., Heldt, L., Hong, L., Tay, Y., Tran, V.Q., Samost, J., Kula, M., Chi, E.H., & Sathiamoorthy, M. (2023). Recommender Systems with Generative Retrieval. ArXiv, abs/2305.05065. ↩︎
-
Petrov, A., & Macdonald, C. (2023). Generative Sequential Recommendation with GPTRec. ArXiv, abs/2306.11114. ↩︎
Did you find this article helpful?