Shallow Embedding Models for Homogeneous Graphs

The previous article “A Guide to Graph Representation Learning” provided a comprehensive introduction to the state of graph representation learning, along with a review of the basic terminologies, techniques, and applications. If you are new to the graph learning domain, I’d highly recommend you read the previous article first. This article takes a closer look at different types of shallow graph embedding models of homogeneous graphs. It also highlights a few real-world applications that build upon some of these ideas.
Categorization
Graph representation learning methods can be categorized based on the type of underlying network as shown below.
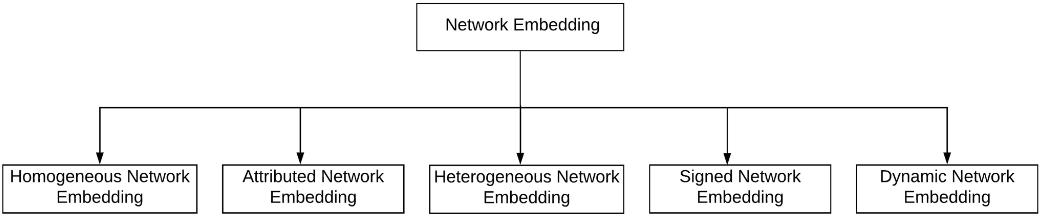
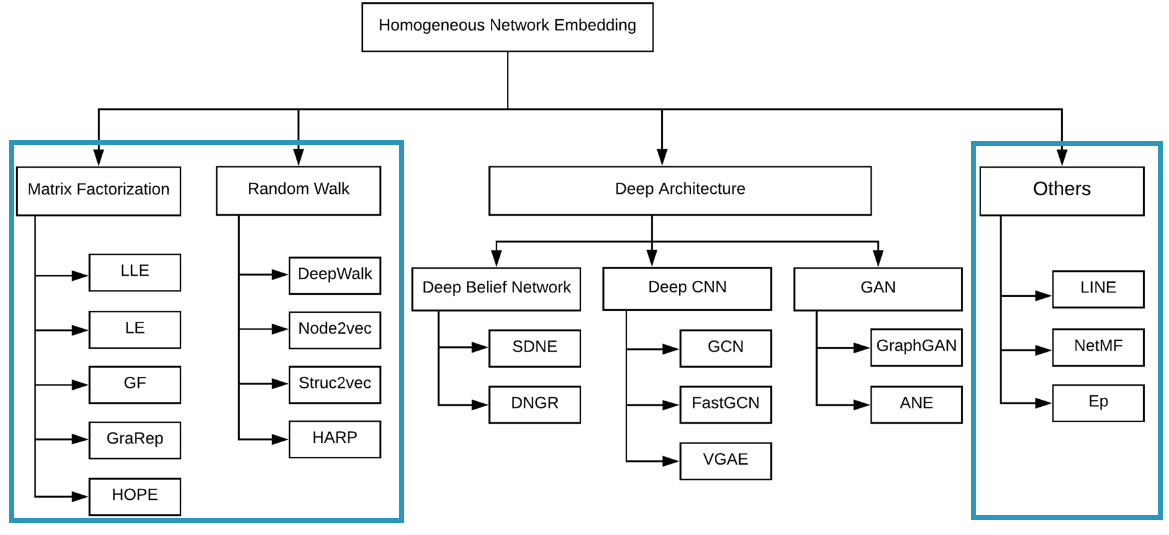
A vast majority of research work in this domain focuses on non-attributed, static, unsinged homogeneous networks. This article will focus on the shallow learning methods for homogeneous graph embeddings. These shallow methods include classical non-neural methods like matrix-factorization as well as approaches that utilize shallow neural networks. Mohan et. al 1 proposed the following taxonomy for grouping the most popular methods for homogeneous graphs. We will roughly follow this categorization but focus only on the shallow methods as highlighted below.
Factorization-based methods
Some of the earliest methods in graph representation learning were based on using factorization to learn a low-dimensional approximation of a node-node similarity matrix. These matrices represent connections between network nodes and can be formed in different ways, such as adjacency matrix, Laplacian matrix, node transition probability matrix, etc. These high-dimensional matrices are factorized to structure-preserving low-dimensional space.
Generally, these methods follow a 2-step approach. First, they construct a proximity-based matrix for the graph where each element $P_{ij}$ of the matrix represents a proximity measure between nodes $i$ and $j$. In the second step, they apply a dimensionality reduction technique to generate node embeddings.
Locally Linear Embedding (LLE)
Roweis et. al 2 proposed a nonlinear dimensionality reduction technique to preserve the local structure of high-dimensional data. They use a simple linear-algebra-based method based on the constraint that the weighted sum of distances between each data point and its k-nearest neighbors in high-dimensional space must be preserved in the lower-dimensional space. These weights are used to minimize the reconstruction error in this unsupervised approach. The performance of LLE is sensitive to the choice of the number of neighbors (k) and doesn’t capture the global structure of the graph.
Laplacian Eigenmap (LE)
Belkin et. al 3 proposed an approach to capture both the local and global structure of the graph data in low-dimensional space. First, they construct a normalized Laplacian matrix based on the k nearest neighbors of each node with weights signifying the distance between the nodes. Then the matrix is decomposed into lower-dimensional space by using the eigenvectors of the Laplacian matrix. LE makes a limiting assumption that the data lies on a smooth, nonlinear manifold, and is also computationally expensive for large datasets because the distance metric needs to be calculated in high-dimensional space.
Graph Factorization (GF)
Ahmed et. al 4 proposed Graph Factorization (GF) method that assumes that the similarity between two nodes is proportional to the dot product of their low-dimensional representations. GF uses an adjacency matrix for representing the graph input and optimizes the following function:
$$ min_{z_i,z_j} \sum_{v_i,v_j \in V} |z_i^T z_j - a_{ij}| $$
Here $z_i$, and $z_j$ are representation vectors for nodes $v_i$ and $v_j$, and $a_{ij}$ is the corresponding item in the adjacency matrix.
GraRep
Cao et al. 5 proposed GraRep for learning global structure information of weighted graphs. GraRep captures relational information between nodes that are k-steps away through different global transition matrices for different values of k (using different loss functions). Global representations for each node are constructed by concatenating different k-step representations. For a given k, GraRep applies matrix factorization on the adjacency matrix $Y$ to factorize it into matrices $W$ and $C$. Each row of W and C contains representation vectors for paths starting with node $w$ and ending at node $c$.
$$ Y_{i,j}^k = W_i^k \cdot C_j^k = \log{\frac{A_{i,j}^k}{\sum_{t} A_{t,j}^k} - \log{\beta}} $$
While GraRep generalizes well to incorporate neighborhoods beyond 2-hops, it doesn’t scale to large networks.
High-Order Proximity preserved Embedding (HOPE)
Ou et. al 6 proposed an embedding algorithm that works similarly to GF and GraRep, such that the goal is to learn embeddings for each node through factorization such that the inner product between the learned embedding vectors approximates some deterministic measure of node similarity. However, HOPE supports more general neighborhood overlap measures for node similarity such as Katz Index, Rooted PageRank, Common Neighbors, Adamic-Adar, etc.
Optimization strategies
Matrix-factorization-based graph representation learning methods have been used in various domains like image recognition, text mining, and bioinformatics. However, scaling these methods to large-scale graphs is a bottleneck because their time complexity is usually quadratic to the number of nodes. Factorizing matrices with millions or even billions of rows and columns is memory intensive and often infeasible. Some researchers have proposed methods to accelerate matrix factorization. For example, frPCA and frPCAt algorithms can accelerate PCA-based factorization, Zhang et. al 7 proposed using the r-tSVD algorithm to accelerate SVD-based factorization in their ProNE model.
Random Walk based methods
Factorization-based representation methods employ deterministic measures of node similarity. Random walk-based methods extend this to stochastic measures of neighborhood overlap, such that if two nodes tend to co-occur on short random walks over the graph, they are optimized to have similar embeddings. A standard random walk is a sequence of nodes such that the next node in sequence at eat step is selected based on a probabilistic distribution.
DeepWalk
Inspired by the advances in NLP, Perozzi et. al 8 proposed an unsupervised method to produce high-quality node embeddings. DeepWalk performs short truncated random walks of fixed length over the input graph and treats these walks as the equivalent of sentences in a special language. Then it uses the Skip-Gram language modeling paradigm to learn a mapping function that given a node (analogous to a word) can predict its context (i.e. the nodes occurring before and after in the corresponding random walk). Given a window of length $w$, our optimization problem is to maximize the co-occurrence probability among the words that appear within w.
$$ minimize_\Phi - \log{Pr({v_{i-w}, … v_{i-1}, v_{i+1}, …, v_{i+w} } | \Phi{(v_i)})} $$
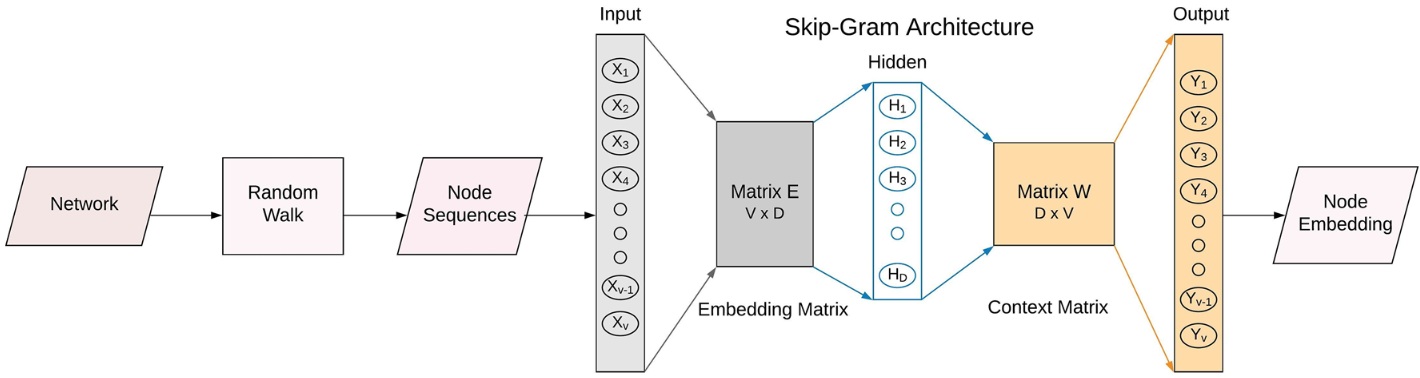
In the original implementation, the authors made several passes over the data and generated a random ordering of nodes to sample one walk per node during each pass. The length of different walks doesn’t necessarily have to be the same. The vocabulary size $|V|$ can be very large, so instead of directly calculating probabilities over every word, DeepWalk used the Hierarchical Softmax loss function to make the model more scalable. The DeepWalk algorithm is trivially parallelizable and can be implemented in an online fashion. Practically, DeepWalk only applies to unweighted networks.
Node2Vec
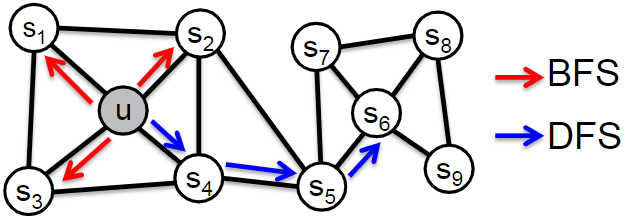
In Node2Vec, Grover et. al 9 extended the DeepWalk algorithm with a more flexible definition of random walks. While DeepWalk simply uses uniform random walks, Node2Vec proposed a hyperparameter that allows the random walk probabilities to smoothly interpolate between walks that resemble either the breadth-first search or the depth-first search. This biased random walk gives a more flexible definition of node neighborhoods and can be represented as:
$$ \alpha_{pq}(t,x) = \begin{cases} \frac{1}{p} & \text{if} d_{tx}=0 \ 1 & \text{if} d_{tx}=1 \ \frac{1}{q} & \text{if} d_{tx}=2 \end{cases} $$
where $\alpha$ is the search bias, $d_{tx}$ is the shortest distance between nodes $t$ and $x$, $p$ is the return parameter that controls the likelihood of immediately revisiting a node, and $q$ is the in-out parameter that controls whether the walk is inclined to visit nodes that are further away (DFS), or closer (BFS). Effectively parameters $p$ and $q$ control how fast the walk explores and leaves the neighborhood of the starting node. Note that the sampling strategy in DeepWalk can be thought of as a special case of Node2Vec with $p=1$ and $q=1$.
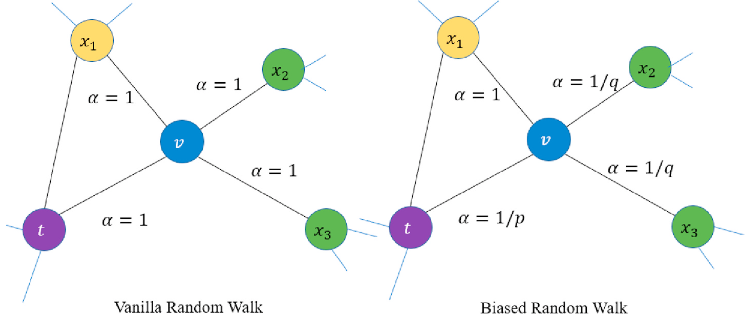
The sampling strategy of Node2Vec allows the model to leverage vastly different structures beyond just immediate neighbors. The authors argue that DFS and BFS represent two extremes in the sampling paradigm. BFS is suited for structural equivalence because it explores local neighborhood structure and DFS is more suited for homophily as it freely explores neighborhoods. Real-world networks exhibit a mixture of both of these notions of node similarity so an ideal solution should accommodate for both BFS and DFS. Node2Vec also uses negative sampling for optimizing the Skip-gram model.
Struc2Vec
In Struc2Vec, Ribeiro et. al 10 proposed a hierarchical approach to measure node similarity at different scales. DeepWalk and Node2Vec used a Skip-Gram window to define the notion of a neighborhood in which proximity is computed. However, it is possible that two nodes that are very far apart could be structurally similar, but the window size might not be enough to capture the two nodes in the same context.

To solve this, Struc2Vec induces a hierarchy by determining structural similarity between each node for different neighborhood sizes. It generates a weighted multilayer graph where all the nodes are present at every layer and each layer corresponds to a level of the hierarchy. It performs biased random walks on the multilayer graph for each node starting from layer 0. Finally, it generates node embeddings by using the Skip-Gram method with hierarchical softmax loss. This method is also computationally expensive and its worst-case complexity makes it infeasible for large graphs.
Hierarchical Representation Learning for Networks (HARP)
Chen et. al 11 proposed an approach where the input graph is recursively compressed for learning embeddings. At each step of this coarsening, it finds a smaller graph that approximates the global structure of the bigger graph by applying edge-collapsing and star-collapsing methods. Then it embeds the hierarchy of all graphs from the coarsest one to the original graph. This process makes learning embeddings more effective because it is easier to get high-quality representations from a smaller graph. The HARP framework can also be applied to any existing representation model.

Other Methods
Large-scale Information Network Embedding (LINE)
In LINE, Tang et. al 12 defined a loss function that explicitly preserves both local and global structures through first-order and second-order proximities. This method uses a BFS approach to sample nodes and optimizes the likelihood of 1-hop and 2-hop neighbors. The objective function is simply:
$$ - \sum_{(i,j) \in E} w_{i,j} \log{p_1(v_i,v_j)} - \sum_{(i,j) \in E} w_{i,j} \log{p_2(v_i,v_j)} $$
This objective is made tractable by using negative sampling. Note that the first-order proximity is not applicable to directed graphs, and the second-order proximity suffers when the network is extremely sparse.
The authors further argue that real-world weighted networks often have large variances in edge weights, which can cause gradient explosion when using stochastic gradient descent methods. To fix this, they also propose an edge sampling technique where edges are sampled with probabilities proportional to their weights. Their paper also proposes using PageRank-based node prestige in second-order proximity calculation, however, a lot of implementations simplify it to using node degree. While the LINE approach is applicable to arbitrary networks, like directed, undirected, and/or weighted, it is not flexible to explore higher-order neighbors at depths more than two.
NetMF
In NetMF, Qiu et. al 13 provided a theoretical analysis to prove that the methods like DeepWalk, LINE, and Node2Vec implicitly perform matrix factorization. They derived the closed form of the matrix for each model and also propose an algorithm called NetMF to explicitly factorize the closed form of DeepWalk’s implicit matrix.
Embedding Propagation (EP)
Durán et. al 14 proposed a novel unsupervised framework for graph representation learning. In this method, neighboring nodes send forward and backward messages to each other. In forward messages, nodes share representations for their attributes (which can also be randomly initialized or learned through another model). Each node aggregates these forwarded messages and applies a reconstruction loss. The corresponding gradients are sent as backward messages for nodes to update their attribute representations. This process is repeated until a convergence threshold is reached. Finally, these attribute representations are used as node embeddings.
Real-world Applications
Alibaba’s Billion-scale Commodity Embeddings
Huang et. al 15 described how Alibaba’s Taobao platform used DeepWalk to generate embeddings for two billion items. First, they collect session-based user behavior sequences from logs. They empirically picked a time window of last one hour to collect these logs to save computational costs and also to accommodate the fact that the users’ interests tend to drift with time. These behaviors are further filtered to remove spam users (more than 1000 items purchased or clicked more than 3500 items in less than three months), and the click events where the user stayed for less than one second.
An item graph is created from these collected behaviors, such that two items are connected by a direct edge if they occur consecutively. The weight of each edge is set to the total number of occurrences of the two connected items in all users’ behaviors.
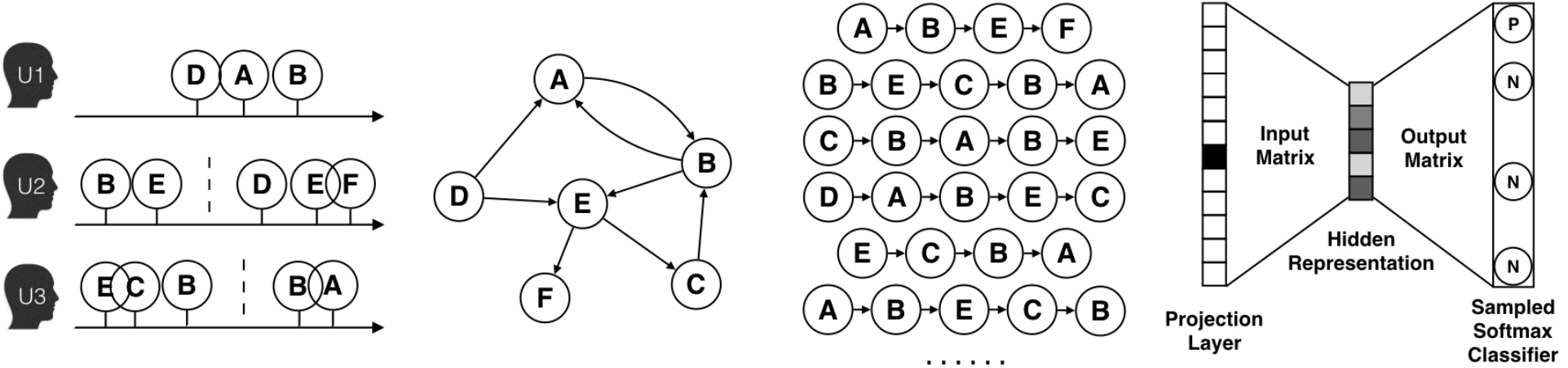
Next, they apply the DeepWalk method (Skip-Gram with Negative Sampling) to learn the embeddings for each node in the item graph.
LinkedIn’s Talent Search and Recommendation System
Ramanath et. al 16 shared their experience of applying neural networks and representation learning methods to improve talent search systems at LinkedIn. The goal of this system is to connect job providers (recruiters) and job seekers (candidates). The hiring needs of a recruiter are expressed in terms of a search query or a job posting, while the LinkedIn profile page serves as a record of qualifications and achievements for each candidate.
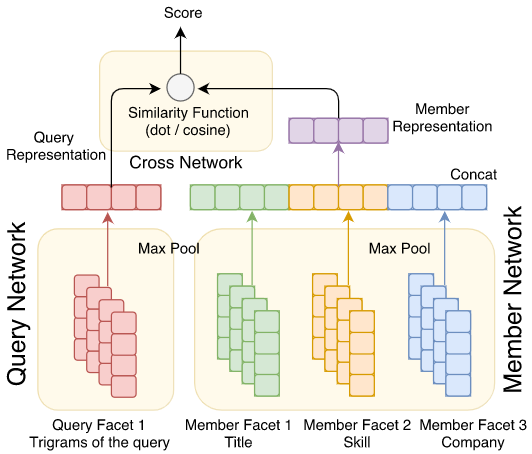
LinkedIn has a graph structure called LinkedIn Economic Graph that stores data about members, institutions, skills, jobs, and relationships among these entities. Instead of considering each member as a node and their interactions as edges, they choose an alternate approach to generate a much smaller and denser graph. They considered attributes for candidates, such as the institutions they worked for, their skills, and titles as the entities, and use the members sharing the same entity as the edge weights. For example, an edge weight between Amazon and Microsoft would indicate the number of members that have worked for both of the companies.
Next, they used the LINE method to learn first-order and second-order embeddings from this graph. Each entity can now be represented as the concatenation of the two embeddings. Queries and members can be represented as the result of a simple pooling operation (like max pooling) applied to these final embeddings. Member embeddings are computed offline and query embeddings are computed at runtime. A simple dot product between the two provides a feature score for their Gradient Boosted Decision Tree (GBDT) ranker.
Airbnb’s Listing Search and Recommendation System
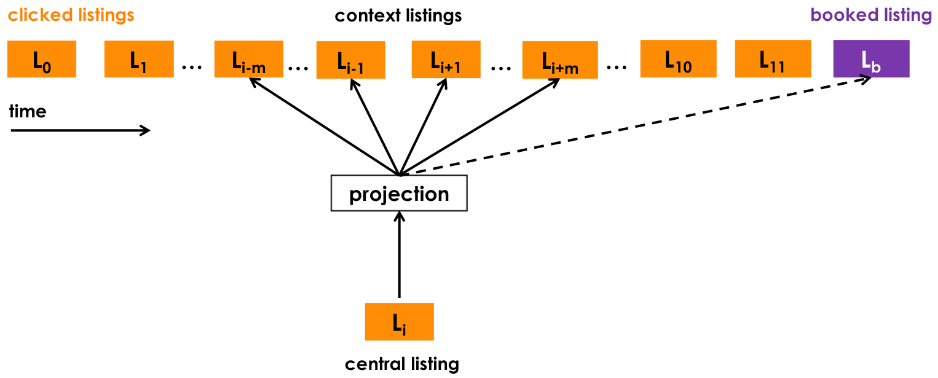
Grbovic et. al 17 shared their experience of building search ranking and recommendation systems for listings at Airbnb. Given an input search query with location and trip dates, their system ranks listings that are most relevant to the guest and are a good match for the host as well. Instead of sampling from a graph structure, their method uses the sequence of items that the user most recently interacted with to provide real-time personalization. These sequences of clicked listings are extracted from user sessions, and a Skip-Gram model with Negative Sampling (SGNS) is used to learn short-term interest representations of listings. The objective of the representation learning model is to maximize the likelihood of observing listings in the context $c$ for a given clicked listing $l$:
$$ argmax_{\theta} \sum_{(l,c) \in D_p} \log{\frac{1}{1 + e^{-v_c^{’}v_l}}} + \sum_{(l,c) \in D_n} \log{\frac{1}{1 + e^{-v_c^{’}v_l}}} $$
where $D_p$ and $D_n$ are sets of positive and negative $(l,c)$ pairs respectively. This objective function is used to optimize for exploratory user sessions, and for sessions that ended with user bookings, they extended the objective function by adding an additional term for booked listing $v_{l_b}$ as well. For booked sessions, they ensured that the booked listing will always be predicted even if it is not within the current context window.
$$ argmax_{\theta} \sum_{(l,c) \in D_p} \log{\frac{1}{1 + e^{-v_c^{’}v_l}}} + \sum_{(l,c) \in D_n} \log{\frac{1}{1 + e^{-v_c^{’}v_l}}} + \log{\frac{1}{1 + e^{-v_{l_b}^{’}v_l}}} $$
The paper also goes over further improvements for adapting to congregated searches, and also learning separate embeddings at the level of user type and embeddings type to capture the long-term interest. These types are defined based on custom rule-based mappings. Learned embeddings are used in their Lambda Rank ranking model.
Summary
Information in many real-world systems can be naturally structured as graphs. By representing these high-dimensional graph structures in a compact low-dimensional space, various graph analytical methods can enable useful practical applications like user search, targeted advertising, and recommendations. This article listed various shallow ways in which node embeddings can be learned from static, homogeneous graphs. The article also highlighted several examples of large-scale industrial applications that utilize these methods.
References
-
Mohan, A., & Pramod, K.V. (2019). Network representation learning: models, methods and applications. SN Applied Sciences, 1. ↩︎
-
Roweis, S.T., & Saul, L.K. (2000). Nonlinear dimensionality reduction by locally linear embedding. Science, 290 5500, 2323-6 . ↩︎
-
Belkin, M., & Niyogi, P. (2003). Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural Computation, 15, 1373-1396. ↩︎
-
Ahmed, A., Shervashidze, N., Narayanamurthy, S.M., Josifovski, V., & Smola, A. (2013). Distributed large-scale natural graph factorization. Proceedings of the 22nd international conference on World Wide Web. ↩︎
-
Cao, S., Lu, W., & Xu, Q. (2015). GraRep: Learning Graph Representations with Global Structural Information. Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. ↩︎
-
Ou, M., Cui, P., Pei, J., Zhang, Z., & Zhu, W. (2016). Asymmetric Transitivity Preserving Graph Embedding. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ↩︎
-
Zhang, J., Dong, Y., Wang, Y., Tang, J., & Ding, M. (2019). ProNE: Fast and Scalable Network Representation Learning. International Joint Conference on Artificial Intelligence. ↩︎
-
Perozzi, B., Al-Rfou, R., & Skiena, S. (2014). DeepWalk: online learning of social representations. Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ↩︎
-
Grover, A., & Leskovec, J. (2016). node2vec: Scalable Feature Learning for Networks. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ↩︎
-
Ribeiro, L., Saverese, P.H., & Figueiredo, D.R. (2017). struc2vec: Learning Node Representations from Structural Identity. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ↩︎
-
Chen, H., Perozzi, B., Hu, Y., & Skiena, S. (2017). HARP: Hierarchical Representation Learning for Networks. ArXiv, abs/1706.07845. ↩︎
-
Tang, J., Qu, M., Wang, M., Zhang, M., Yan, J., & Mei, Q. (2015). LINE: Large-scale Information Network Embedding. Proceedings of the 24th International Conference on World Wide Web. ↩︎
-
Qiu, J., Dong, Y., Ma, H., Li, J., Wang, K., & Tang, J. (2017). Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec. Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. ↩︎
-
García-Durán, A., & Niepert, M. (2017). Learning Graph Representations with Embedding Propagation. NIPS. ↩︎
-
Wang, J., Huang, P., Zhao, H., Zhang, Z., Zhao, B., & Lee (2018). Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ↩︎
-
Ramanath, R., Inan, H., Polatkan, G., Hu, B., Guo, Q., Ozcaglar, C., Wu, X., Kenthapadi, K., & Geyik, S.C. (2018). Towards Deep and Representation Learning for Talent Search at LinkedIn. Proceedings of the 27th ACM International Conference on Information and Knowledge Management. ↩︎
-
Grbovic, M., & Cheng, H. (2018). Real-time Personalization using Embeddings for Search Ranking at Airbnb. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ↩︎
Related Content





Did you find this article helpful?