Tuning Large Language Models for Recommendation Tasks

The state-of-the-art performance of Large Language Models (LLMs) has encouraged researchers to also adapt LLMs for recommendation tasks. In Zero and Few Shot Recommender Systems based on Large Language Models article, I gave an overview of the several ways researchers have proposed to adapt LLMs in the recommendations domain by formulating them as natural language expressions.
In the ChatGPT-based Recommender Systems article, I further highlighted several studies that specifically utilize ChatGPT. These early works show that LLMs exhibit promising performance on ranking tasks and explainability-oriented recommendations. However, well-tuned task-specific recommender algorithms still outperform LLMs for general recommendation tasks both under zero-shot and few-shot settings. This article gives an overview of the challenges faced by LLMs in the recommendations domain and describes several recent research proposals to overcome these obstacles.
Advantages and Disadvantages of Using LLMs for Recommendations
Advantages
There are several pros to using LLMs for recommendation tasks.
- LLMs’ zero-shot and few-shot capabilities are helpful in alleviating sparsity scenarios (such as cold start problems, and long-tailed items). Experiments have shown that LLMs with over 100B parameters provide reasonable recommendations, comparable to decent heuristic-based baselines, under cold-start scenarios 1.
- LLMs can adapt to new information without having to change the model architecture or retrain.
- LLMs can enable users to freely and precisely express their needs through a chat-based interface via natural language instructions. Whereas in traditional methods users are only passively involved (through implicit feedback) in improving the recommendations.
- Existing recommendation algorithms are task-specific and require specific user-item interaction data for training. This means that they lack the generalization ability to unseen settings. On the other hand, LLMs can use user interaction data represented as sequences to supplement their vast knowledge.
- Traditional approaches like collaborative filtering rely on a large volume of training data. Comparatively, LLMs demand considerably lesser data as they already maintain an extensive amount of world knowledge about items, such as tv shows or products.
- Current recommendation algorithms utilize complex feature processing methods like preprocessing strategies, embedding methods, custom architectures, etc. Prompts simplify these feature processing and modeling steps to a large extent.
- LLMs can generate explanations, as a byproduct of intermediate chain-of-thought reasoning, in natural language for justifying specific recommendations. This increases the transparency of the recommender system.
Limitations
As listed below, there are also several shortcomings in using LLMs.
-
Due to the stochastic nature of LLMs’ generative process, LLMs may recommend items that are not present in the candidate set. Some recent studies try to get around this issue by also feeding the candidate item set into prompt 2, but this approach also faces issues like position bias and limited context lengths.
-
LLMs can generate invalid or completely unexpected answers, even when prompts explicitly specify the set of possible answers under in-context (few-shot learning) settings 3.

Example taken from [^2] -
LLMs can be highly sensitive to the input prompts and may not fully follow the instruction prompt. For example, in a paper by the Google Brain team1, the researchers had to add additional sentences, such as “Give a single number as rating without explanation” and " Do not give reasoning", to input prompts to avoid LLM outputs other than the expected movie rating prediction.
-
Recommendations can be highly dataset dependent. For example, the same movie can have different ratings on different platforms. Evaluations under such scenarios might deem LLMs’ performance to be unacceptable for certain datasets.
-
Recent studies have shown that there can be a huge gap between the universal knowledge encoded in LLMs and the specificity of user behavioral patterns in private domain data 2. Hence, zero-shot and few-shot methods may be insufficient to deploy LLMs in private domain recommender systems. Additionally, data security concerns are significant issues in the recommendation field.
-
The pretraining objective of the currently popular LLMs does not include any recommendation objective. Hence these LLMs usually perform worse than existing task-specific models under zero-shot and few-shot settings for solving complex specialized tasks.
-
LLMs are large, complex, and costly to train. Besides, a lot of the popular LLMs (like ChatGPT) today are behind private APIs, and some LLMs (like PaLM and Chinchilla) do not provide access to their model parameters or APIs.
-
Limited context length in LLMs makes it hard to incorporate a substantial amount of user behavior sequences and/or candidate items into the prompt. Zhang et al.2 try to work around it by randomly dividing 100 candidates into 10 equal-sized groups and instructing the LLM model to select the most potential item from each group. The final ranking result is obtained by reranking the set of those 10 resulting items.
Shortcomings of In-context Learning Methods
In-context learning methods leverage LLMs’ rich knowledge and strong generalization capabilities by phrasing the recommendation task as prompts. However, several research works have shown that the LLMs based on few-shot learning improve zero-shot performance but still get outperformed by traditional recommender system baselines. Some of the probable causes for this suboptimal performance are listed in the previous section and also highlighted below.
- There exists a substantial disparity between the training task of LLMs and the recommendation tasks. The LLM pre-training also has inadequate recommendation data leading to this misalignment.
- A lot of recommenders are built on domain-specific and private data.
- Due to limited context length, prompts can’t always include all candidates and user behavior sequences. LLMs also suffer also position bias which further affects the recommendation performance.
- Prompt-tuned LLMs have been shown to exhibit unintended behavior such as making up facts, generating biased text, or not following specified instructions.
In the next section, we look at some of the recently proposed ways to bridge the gap between LLMs and recommendation tasks.
Instruction-Finetuned LLMs for Recommendations
Instruction Tuning refers to finetuning an LLM on a collection of tasks phrased as instructions. Through instruction finetuning on recommendation-oriented instruction data, LLMs can effectively integrate user behaviors in the private domain with universal knowledge. In the previous article, we learned about the P5 model, which formulates multiple recommendation tasks with instruction-based prompts. One disadvantage of P5 is that it still relies on traditional user/item IDs to represent users/items. The discrepancy between the semantics of these IDs and that of the pre-trained language models (PLMs), can severely impact the model performance. In this section, we take a look at some of the recent proposals that perform instruction tuning to achieve better performance on recommendation tasks with LLMs.
TALLRec
Bao et al.4 proposed a Tuning framework for Aligning LLMs with Recommendations (TALLRec) for tuning LLMs with recommendation data. Their framework combines instruction tuning with recommendation tuning to enhance the efficacy of the model. First, they construct a set of instructions in which each instruction consists of an Instruction Input and Instruction Output pair. Instruction Input defines the task and corresponding task input, and the Instruction Output defines the task output.
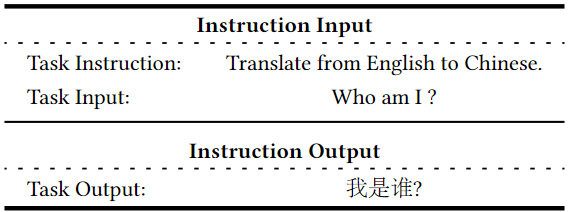
Next, they train the LLM in two tuning stages: instruction tuning (instruct-tuning) and recommendation tuning (rec-tuning). The instruction tuning stage is a standard training process of LLM that enhances the LLM’s generalization ability. The authors used the self-instruct data from Stanford Alpaca for this tuning. For Rec-tuning, they construct “Rec Instructions” by transforming a restricted amount of users’ historical interactions into instructions of the form: “User Preference: $item_1$, $item_4$, …, $item_n$. User Unpreferenced: $item_2$, $item_3$, …, $item_{n-1}$. Will the user enjoy the target movie/book: $item_{n+1}$. [yes/no]”. Here “unpreferenced” is referring to a set of items that the user didn’t like.
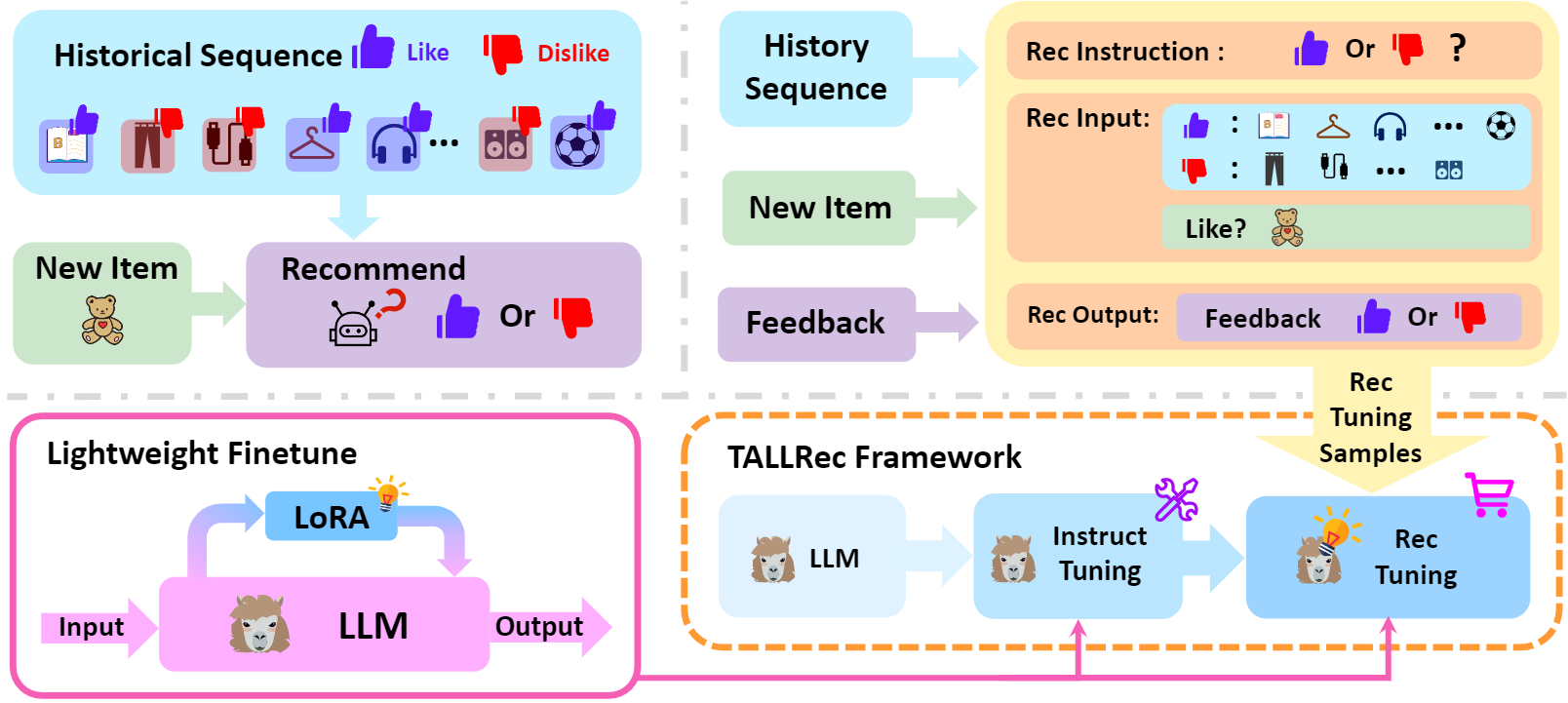
The authors employed LoRA to facilitate efficient lightweight fine-tuning which can be done with low GPU cost and few tuning samples (less than 100). They picked LLaMA LLM to conduct their experiments and showed that their trained model outperformed previous baselines in the few-shot setting. Their trained model also exhibited strong cross-domain transfer capabilities. The code and data for TALLRec are available on GitHub.
Flan-T5 Tuned for Recommendation
Google Brain team conducted a study5 to evaluate various LLMs, with sizes ranging from 250M to 540B parameters, on user rating prediction tasks in zero-shot, few-shot, and fine-tuning scenarios. For finetuning experiments, they used Flan-T5-Base (250M) and Flan-U-PaLM (540B), while for zero-shot and few-shot experiments, they used GPT-3 models from OpenAI and 540B Flan-U-PaLM.

Through experiments, the authors show that the zero-shot LLM performance lags far behind traditional recommender models. But fine-tuned LLM achieves comparable or even better performance while using only a small fraction of training data.
InstructRec by WeChat
Zhang et al2 from WeChat proposed an instruction tuning approach called InstructRec for LLM-based recommender systems. This research considers a recommendation task as instruction following/execution by LLMs. To express the users’ preferences, intentions as well as the task form and context they designed a general instruction format for tuning the LLMs.
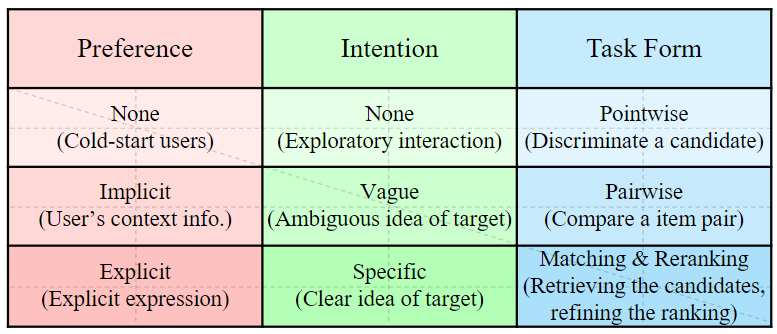
User preference refers to users’ personalized taste toward item attributes. User Intention refers to users’ more immediate demands for certain types of items, and Task form is the corresponding recommendation task. Additionally, contextual information like time and place are also utilized. The authors introduced 39 coarse-grained instruction templates to cover all interaction scenarios such as recommendation, retrieval, and personalized search.

Inspired by automatic prompting strategies, like self-instruct, the authors prompted a teacher-LLM (GPT-3.5) with users’ historical interactions and reviews to automatically generate 252K fine-grained instructions in the preference/intention/task format. To further increase the diversity of instructions, they propose manual strategies like flipping the input and output structure of the instructions, enforcing the relatedness between preference and intention, and adding Chain-of-through (CoT) like intermediate reasoning.
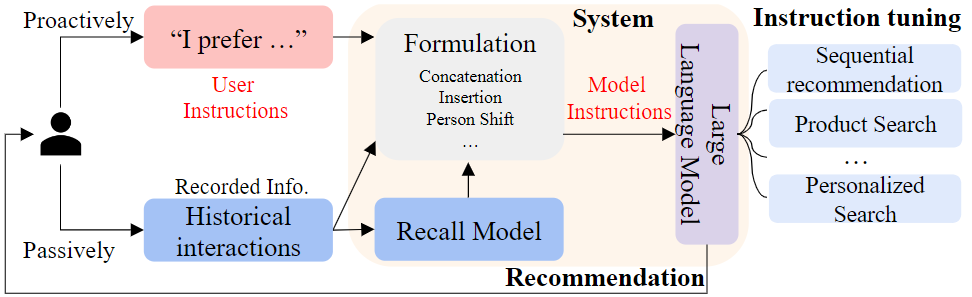
For Instruction tuning, the authors selected the 3B Flan-T5-XL model. Input lengths longer than the model’s 512 token length limit were truncated. For longer context lengths, the authors recommend experimenting with the LLaMA model. In accordance with the computational efficiency and model capacity, the LLM was used as a reranker. At inference time, an appropriate instruction template is selected to create an instruction by using operations like concatenation, insertion and, persona shift. This instruction is then supplemented with the candidate set of items and given to the LLM for ranking.
RecLLM by Google Research
Friedman et al.6 proposed a roadmap for building an end-to-end controllable, large-scale Conversational Recommender System (CRS) using LLMs. They propose several ways to integrate LLMs with external resources, such as a user profile database, recommendation engine, etc. to build a CRS system as shown below.
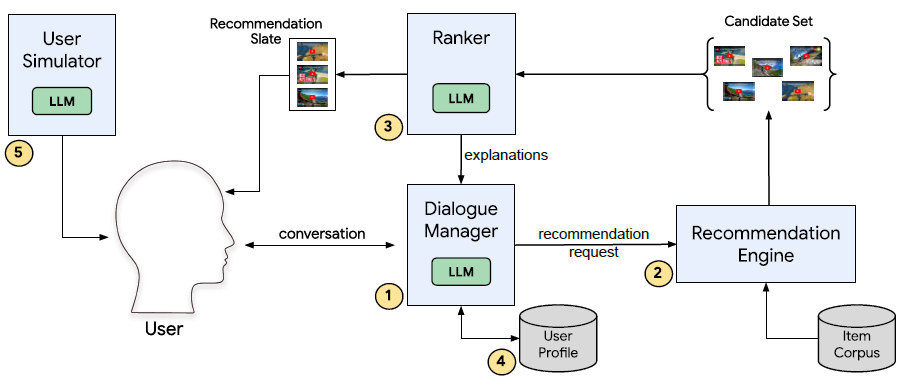
CRS gives users the flexibility to control their recommendations by engaging in a real-time multi-turn dialogue. The system learns to refine recommendations based on users’ direct feedback, and can also engage in tasks that are tangential to recommendations, such as undirected chitchat and question-answering. Due to the lack of existing conversational datasets, they used a controllable LLM-based user simulator to generate synthetic conversations. Instead of utilizing interaction history for user preference understanding, the authors use LLMs that consume user profiles as interpretable natural language and use them to personalize sessions.

In the paper, one of the recommended approaches for retrieval is to use a dual-encoder architecture where LLMs are used as context encoders. LLM used for ranking also performs intermediate reasoning to generate natural language explanations for why an item is being selected. The retrieval model, ranking model, as well as dialogue manager, are fine-tuned on recommendation data that includes generated synthetic sessions. As a proof-of-concept, the authors build a CRS (using LaMDA as the underlying LLM) that serves recommendations from the corpus of all public YouTube videos.
Future Directions to Explore
The idea of adapting LLMs for recommendation tasks is still in the nascent stage. There are several issues with LLMs, such as hallucinations and biases that are still an open problem. Some of the potential areas to explore in the future are listed below.
- Automated prompt design approaches could allow the system to design prompts more efficiently and effectively.
- A lot of the current LLM-based recommender systems rely on single-turn instruction following methods. Extending them to multi-turn conversation scenarios can improve the generalization ability of these recommendation models.
- As the research in LLMs continues to support increased context length, it will enable the modeling of long behavior sequences.
- LLMs could extend support for multimodal instructions and feedback to gain a richer understanding of user intent and preferences.
- AI-generated content (AIGC) could also supplement human-generated content to create more effective training and tuning strategies for LLMs.
Summary
Using LLMs for recommendation tasks is an exciting paradigm with a lot of promising opportunities. Initial experiments show that the zero-shot performance of LLMs in general-purpose ranking tasks is suboptimal. Although in-context learning provides a significant improvement, it still struggles from the fact that there exists a substantial disparity between training tasks for LLMs and recommendation tasks. Recently, researchers have started to experiment with more effective methods that instruction-tune LLMs to adapt them to recommendation tasks. Some of this work is done with private data and open-source LLMs and claims significant improvements. This article highlighted some of the recent proposals on this exciting new theme.
Related Content

Zero and Few Shot Recommender Systems based on Large Language Models
Introduction to using Large Language Models for recommendation tasks.
Read more...
ChatGPT-based Recommender Systems
Delve into the recent efforts to harness the power of ChatGPT for recommendation tasks!
Read more...References
-
Kang, W., Ni, J., Mehta, N., Sathiamoorthy, M., Hong, L., Chi, E.H., & Cheng, D.Z. (2023). Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. ↩︎ ↩︎
-
Zhang, J., Xie, R., Hou, Y., Zhao, W.X., Lin, L., & Wen, J. (2023). Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach. ↩︎ ↩︎ ↩︎ ↩︎
-
Dai, S., Shao, N., Zhao, H., Yu, W., Si, Z., Xu, C., Sun, Z., Zhang, X., & Xu, J. (2023). Uncovering ChatGPT’s Capabilities in Recommender Systems. ArXiv, abs/2305.02182. ↩︎
-
Bao, K., Zhang, J., Zhang, Y., Wang, W., Feng, F., & He, X. (2023). TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. ArXiv, abs/2305.00447. ↩︎
-
Kang, W., Ni, J., Mehta, N., Sathiamoorthy, M., Hong, L., Chi, E.H., & Cheng, D.Z. (2023). Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. ↩︎
-
Friedman, L., Ahuja, S., Allen, D., Tan, T., Sidahmed, H., Long, C., Xie, J., Schubiner, G., Patel, A., Lara, H., Chu, B., Chen, Z., & Tiwari, M. (2023). Leveraging Large Language Models in Conversational Recommender Systems. ↩︎
Did you find this article helpful?