Generative Retrieval for End-to-End Search Systems

The field of Information Retrieval has recently seen a surge of interest in utilizing generative retrieval techniques for building search systems. These methods employ autoregressive Seq2Seq models to directly map each query to the relevant document. Hence, these models are also end-to-end differentiable and eliminate the need for traditional search indexes. Accordingly, the corresponding systems have also been called Autoregressive Search Engines or Model-based Retrieval Frameworks. This article provides a gentle introduction and a literature review of the current state of progress of this new paradigm.
Towards Index-free and Model-based Generative Retrieval
Text Retrieval
Text Retrieval is a fundamental task in the Information Retrieval (IR) domain that, given a query, finds relevant textual information from a massive document corpus. It represents a crucial component of various language-based systems, such as search ranking and question answering. This task usually entails retrieving a single most relevant paragraph or document to the given query (i.e., no-hop retrieval), or multiple documents that together provide the information required to answer the query (i.e., multi-hop retrieval). Next, we review some of the most commonly adopted strategies for text retrieval.
Traditional IR Framework
Most of the existing IR systems follow a three-step paradigm, i.e. “index-retrieve-then-rank”. Document representations are learned during indexing, the relevant document corresponding to a given query is found during retrieval and the documents are sorted in the order of relevance during ranking. For the indexing and retrieval stage, the existing approaches can be divided into the following two categories with respect to the type of representation and mode of indexing.
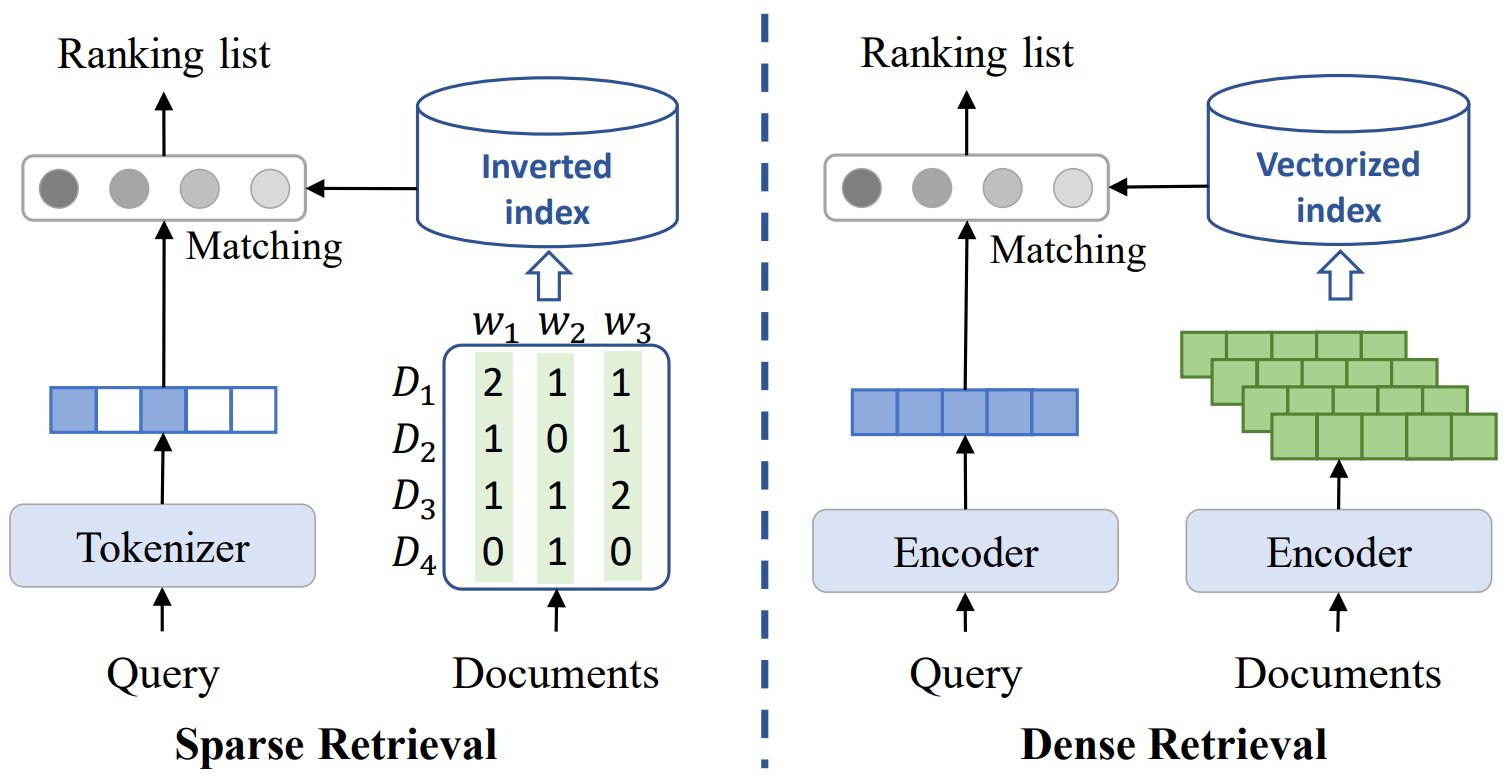
Sparse Retrieval with Inverted Indexes
This traditional retrieval and indexing method provides a great trade-off between accuracy and efficiency. First, an inverted index is built based on all of the documents in the corpus. This index encodes term-based features like term frequencies, term positions, document structure information, and document length. For retrieval, this method fetches documents based on matching between query terms and document terms. To measure this term relevance and weights for different terms, it uses classical techniques like TF-IDF, BM25, and some graph-based approaches that employ term frequencies and precise word matching.
There have also been works that utilize neural networks to enhance the performance of sparse retrieval from a semantic aspect. For example, word embedding techniques like word2vec are used to get a better measure of semantic similarity between query and document terms, pre-trained models like BERT and DeepCT are used to predict term weights (“importance”) instead of traditional term frequency, and term expansion methods are used to improve recall.
Dense Retrieval with Vectorized Indexes
In Dense Retrieval, each of the documents in the corpus is encoded into a dense vector through a neural network. These low-dimensional dense representations are used to build a vectorized index. During retrieval, it embeds the input query into the same latent space and calculates embedding similarities between the query and documents, through methods like inner product, cosine similarity, and efficient K-nearest neighbor search. These similarity scores are utilized as estimated relevance scores for effective retrieval. Techniques like Approximate Nearest Neighbor Search (ANNS) and Product Quantization (PQ) can be used to improve the retrieval efficiency.
Dense retrieval models have been further enhanced with optimizations such as negative sampling strategies such as in-batch negatives and hard negative mining, lightweight interaction layers, knowledge distillation, pre-training on pseudo-query and document pairs, fine-tuning with large-scale pre-trained language models, etc. resulting in state-of-the-art performance and an industry-wide adoption of dense retrieval. The most common dense retrieval methods use bi-encoders (also called, dual encoders) which are often based on a pretrained language model such as BERT. These bi-encoders encode queries and documents into low-dimensional dense representations instead of the high-dimensional sparse representations found in techniques like BM25. These bi-encoders perform some of the heavy computations like extracting the dense embeddings of items in the corps in an offline fashion, which combined with low latency inference using ANNS or maximum inner product search (MIPS) has made them the current de facto implementation of document retrieval.
Ranking
The goal of the ranking model is to determine the relevance degree of each candidate document given a query. There has been a wide variety of ranking algorithms proposed over the years, such as vector space models, probabilistic models, learning-to-rank models, and neural ranking models. Additionally, several pre-training tasks, such as the Inverse Cloze Task (ICT) and Representative Words Prediction (ROP), have been proposed to enhance the performance of downstream ranking tasks.
Shortcomings of the Traditional Paradigm
Sparse retrieval techniques are known for their simplicity and effectiveness, but they often fail to capture rich semantic connections between queries and documents. Methods like BM25 rely on lexical overlap, term frequency heuristics, and inverse document frequency, thereby failing to match documents that have minor word overlap but are semantically related. On the other hand, dense retrieval goes beyond lexical overlap and captures rich semantic and contextual information as a way to alleviate the vocabulary mismatch problem. But it can also suffer from low precision as the precise match between tokens is ignored.
Despite their wide adoption and popularity, bi-encoder models suffer from issues such as embedding space bottleneck, information loss, and limited expressiveness due to fixed-size embeddings, and lack of fine-grained interactions between embeddings. Overall, the following issues with the traditional “index-retrieve-then-rank” framework build the motivation for generative retrieval systems.
- During training, the heterogeneous components in the traditional pipeline are difficult to jointly optimize in an end-to-end way towards a global objective. It also leads to errors accumulating and propagating among the sequential components.
- At the inference stage, it requires a large document index to search over the corpus, leading to significant memory consumption. This memory footprint further increases linearly with the corpus size.
- In a dual encoder setup, the representation for the queries and documents are obtained independently allowing for only shallow interactions between them.
- ANN algorithms require a strong assumption for the Euclidean space, so bi-encoders have to adopt simple functions such as cosine similarity which is unable to incorporate deep query-document interactions.
- By limiting the query and document representations to a single fixed-size dense vector, dual encoders also potentially miss fine-grained information when capturing the similarity between two vector representations. The problem is even more critical in the case of multi-hop retrieval 1.
- An appropriately hard set of negative data has to be subsampled at training time.
Generative Retrieval
Generative Retrieval is fundamentally different from the long-standing “index-retrieve-then-rank” paradigm. This model-based IR system collapses the indexing, retrieval, and ranking components to a single consolidated model 2. In this framework, a single generative model, such as a Transformer-based model, is used to directly return relevant information corresponding to a query, without utilizing any explicit document indexes. The model parameters encode the semantic information of documents and hence it can be regarded as a differentiable indexer which can be optimized end-to-end 3. This design employs the sequence-to-sequence paradigm with an encoder-decoder architecture, such as T5 and BART, and generates the output left-to-right, token-by-token in an autoregressive fashion conditioned on context. Different research groups have referred to this paradigm with different names, such as Autoregressive Search Engine 4, Differentiable Search Index (DSI) 5, and Neural Corpus Indexer (NCI) 6. Interested readers may refer to the blueprint that Metzler et al. proposed for model-based IR paradigm7.
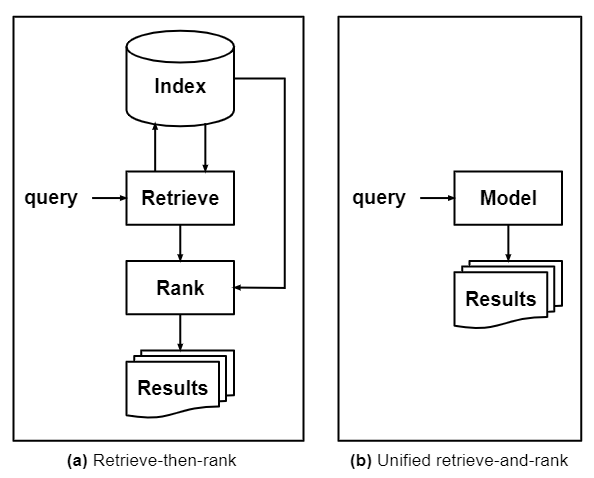
Generative Retrieval offers the following advantages:
- It simplifies the retrieval pipeline by replacing the large external index with an internal index (i.e., model parameters), thereby greatly reducing the memory cost.
- The knowledge of all documents in the corpus, that is encoded into the model parameters, can be optimized during the model training end-to-end towards a global objective for IR tasks 8.
- It improves generalization ability by forcing the model to explain every token in the question and document using cross-attentions and enables complete capture of relevance between queries and documents.
- Dense Retrieval models rely on contrastive learning to distinguish positives from negatives, which is inconsistent with the language models’ training objective. Generative retrieval allows for better exploitation of the capabilities of large language models, such as exploiting the knowledge learned during pre-training.
Inputs and Outputs
During training, the model learns to map the textual representation of documents to output targets, such as document identifiers or an entire text sequence like a title, while also learning to fetch the same targets when it receives a relevant query as input. Different lines of research have explored multiple design choices here.
Document Representation
A straightforward way to represent a document is to use a text span from the document. For example, DSI5 uses a strategy called FirstP which utilizes the first 64 tokens from each document. The authors also propose a Set Indexing strategy that de-duplicates repeated terms and removes stopwords and an Inverted Index strategy that maps chunked documents (as opposed to entire documents) to identifiers. Similarly, NCI6 leverages a method called Document As Query (DaQ), which randomly selects 10 chunks of 64 consecutive tokens.
Output Representation
Current generative retrieval methods either predict a unique identifier corresponding to each document, or take semantic text pieces, such as titles, URLs, and substrings as identifiers. The former approach requires additional memorization of one-to-one mappings between identifiers and corresponding documents, while the latter approach usually requires a heuristic function to transform predicted identifiers into a ranked passage list 9.
-
De Cao et al. 10 proposed one of the earliest generative retrieval models called GENRE (Generative Entity Retrieval) in which they used the autoregressive BART model to perform entity retrieval. GENRE retrieves entities by generating their names (such as Wikipedia page titles) of documents through a sequence-to-sequence model.
-
Chen et al. 11 proposed a generative model called GERE (Generative Evidence Retrieval) for fact-checking tasks, which generates the document titles as well as evidence sentence identifiers.
-
Tay et al. 5 devised the DSI (Differentiable Search Index) that first assigns a unique ID to each item in the corpus, and then performs retrieval with a T5 model by directly generating relevant document identifiers corresponding to the query. The authors also explored different ways to obtain these document identifiers.
-
Bevilacqua et al. 4 proposed the SEAL (Search Engines with Autoregressive LMs) model which considers all n-grams in the passage as identifiers and retrieves an item (paragraph or document) by finding the item containing the generated n-gram using an FM index.
-
Lee et al. 1 proposed GMR (Generative Multi-hop Retrieval) for applying generative retrieval to multi-hop retrieval tasks. Their model generates the entire text of the target paragraph.
-
Li et al. 12 proposed MINDER ( Multiview Identifiers Enhanced Generative Retrieval) that simultaneously utilized multiple types of identifiers, including titles, substrings, and pseudo-queries.
-
Zhou et al. 3 proposed Ultron (Ultimate Retriever on Corpus) that suggested using either document URLs (split by
/and reversed), document title and domain, or a quantization-based semantic ID as target.$docid_{URL} = \begin{cases} \text{reversed URL}, & \text{if}\ \text{title length} \le L \ \text{title+domain}, & \text{otherwise} \end{cases} $
-
Ren et al.13 proposed TOME (Two-stage Model-based Retrieval) that solely utilizes tokenized URLs as the identifier, without any additional processing. LLM-URL proposed by Ziems et al.14 uses Wikipedia URLs with
https://en.wikipedia.org/wiki/appended to the end of the prompt to encourage the generation of URLs.
Document Identifiers
Autoregressively generating document identifiers token-by-token as output, instead of generating strings of passages directly, can help in reducing useless information in the output while also making it easier for the model to memorize and learn during training. However, the identifiers must be distinctive enough to represent a passage. DSI was the first system to assign an identifier for each document as the target. Since then several researchers have proposed different ways to create high-quality identifiers for effective generative retrieval.
Unstructured Atomic Identifiers
One of the simplest methods that DSI suggested was to assign each document an arbitrary random integer identifier. The role of decoding is then to learn a probability distribution over the identifiers. Similar to the output layer of a standard language model, one logit is used for each unique document identifier (docid). To retrieve a list of top-k documents, these output logits can simply be sorted.
Naively Structured String Identifiers
DSI also tried treating the above unique integer identifier as tokenizable strings. In this approach, the docid string is sequentially decoded one token at a time, thereby eliminating the need for a large softmax output space or learning embeddings for each individual docid. An approximation (partial beam search tree) can be used to construct the top-k retrieval scores.
Semantically Structured Identifiers
DSI authors hypothesized that enriching the docids with semantic structure can lead to better retrieval performance. They proposed an unsupervised preprocessing step that employed a hierarchical k-means clustering algorithm over document embeddings to create 10 clusters. Each document is assigned an identifier based on its cluster number and the number of documents within the cluster.
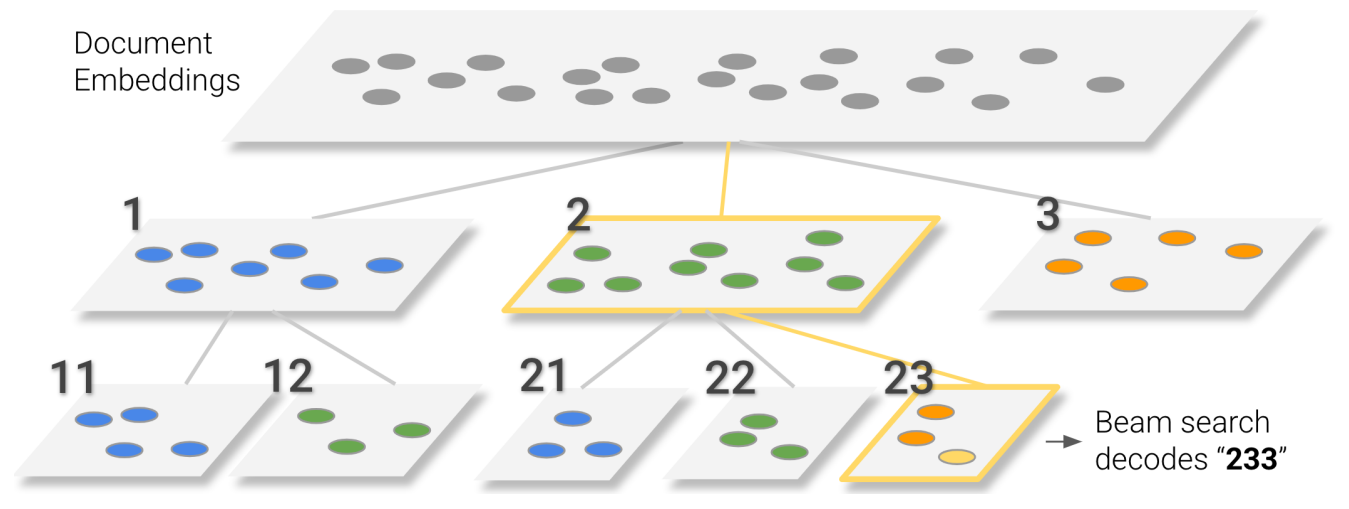
NCI further extended DSI’s semantic identifier method by prepending each digit in the docid with a position number and proposed a novel prefix-aware weight-adaptive auto-regressive decoder that specifically takes into account the prefixes in semantic docids. By doing this, the same token will be assigned different embedding vectors at different positions in the identifiers.
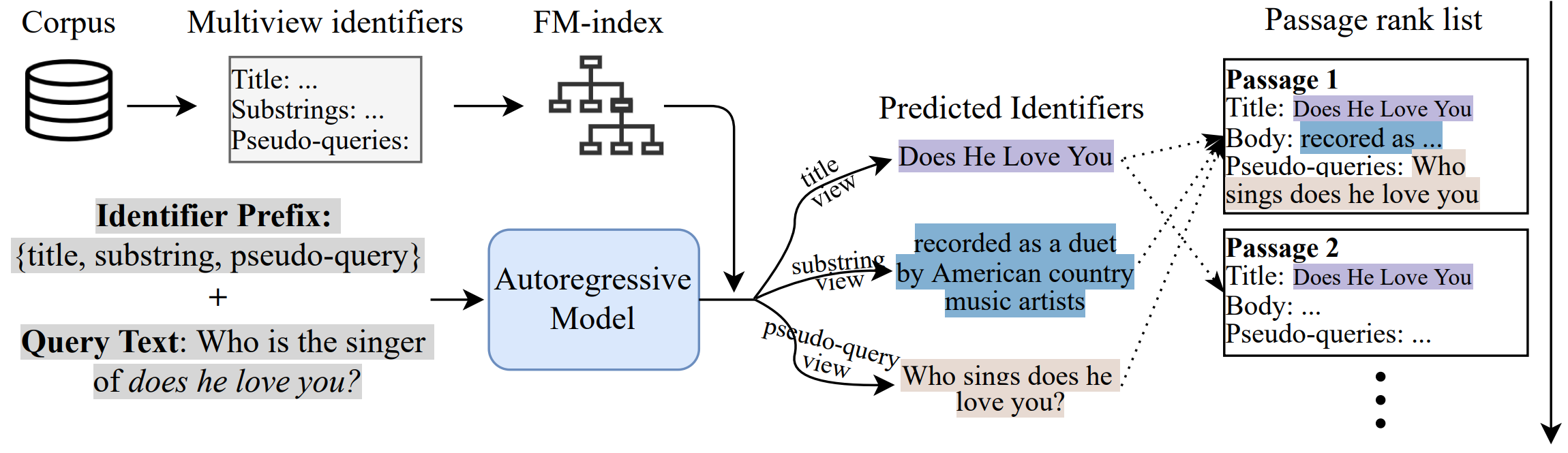
In MINDER 12, the authors argue that a single type of identifier is usually not sufficient to accurately represent a document. So they propose generating a multiview identifier that combines information from complementary sources, such as titles, substrings, and pseudo-queries to facilitate holistic ranking of documents from multiple perspectives. Title information could help with general queries, substring can respond to more detailed ones, and the synthetic text could cover some complex and difficult queries.
Some researchers have also utilized learned quantization for constructing document identifiers. For example, Ultron 3 suggested dividing the D-dimensional document vectors into m groups and then performing k-means clustering to obtain k cluster centers. Each document is then represented as a set of m cluster IDs. In GENRET, Sun et al. 15 used an auto-encoding framework to learn semantic docids in an end-to-end manner. In TIGER (Transformer Index for Generative Recommenders), Rajput et al. 16 proposed generative retrieval for building a sequential recommender system. They used a hierarchical method called RQ-VAE to generate a tuple of codewords, called semantic ID, for each item.
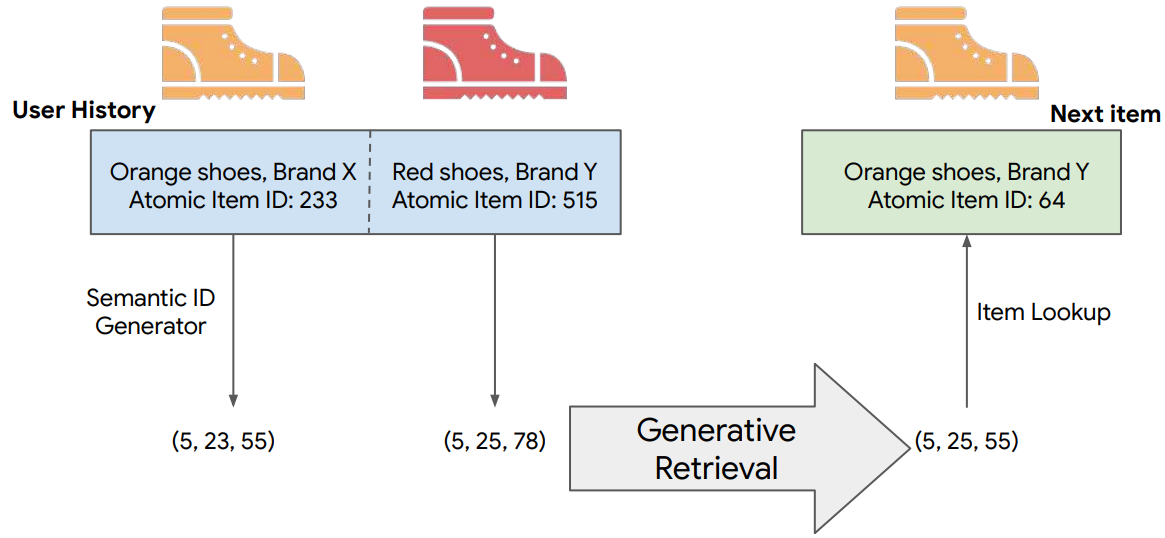
In AutoTSG (Auto-regressive Search Engine with Term-Set Generation), Zhang et al.17 proposed an unordered term-based document identifier. The authors introduced a set-oriented strategy in which any permutation of the term-set identifier will lead to the retrieval of the corresponding document. This relieves the seq2seq of the requirement for the exact generation of the document identifier. It also prevents cascading errors where an incorrect prediction made at any step of the generation process leads to an incorrect or invalid retrieval result.
Modes of Operation
This section describes how generative retrieval unifies the two basic modes of operation, i.e., indexing and retrieval in an end-to-end way by leveraging two sequence-to-sequence tasks.
Indexing Phase
During training, the model learns to generate the document identifier given the document content. This learned mapping between the document’s content and the corresponding identifier is encoded in the parameters of the model. The two main objectives at this stage are:
-
Generate identifiers for documents: We looked at different ways to do this in the previous section.
-
Establish a semantic mapping from documents to identifiers: During the indexing phase, the generative model aims to memorize the mapping of document collections with corresponding identifiers. Various researchers have suggested different ways to enhance this association.
-
DSI: The authors of DSI also proposed some variants of sequence-to-sequence tasks for indexing: Inputs2Target (learn mapping from document tokens to identifiers), Targets2Inputs (learn mapping from identifiers to document tokens), Bidirectional (use both Inputs2Target and Targets2Inputs distinguished with a prefix token), Span Corruption (prefix identifiers to documents tokens and learn with span correction objective).
-
CorpusBrain: In CorpusBrain, Chen et al. 18 showed that a strong generative retrieval model can be learned with a set of adequately designed pre-training tasks, and be adopted to improve a variety of downstream tasks with further fine-tuning. The pre-training data in this context is the positive pairs of query and document identifiers. They propose three pre-training tasks: Inner Sentence Selection (treat sentences randomly drawn from a document as a pseudo-query), Lead Paragraph Selection (treat top paragraph randomly drawn from documents as pseudo-queries), and Hyperlink Identifier Prediction (treats anchor text as pseudo-queries).
-
Ultron: In Ultron, the authors propose two stages of pre-training to learn more enriched mappings. In the “General Pretraining” step, each document is segmented into passages by fixed-size windows, and passages to identifier pairs are used for training. The paper also extracts important words (based on tf-idf) and learns to map this set of terms to identifiers within the same training step. In the “Search-oriented Pretraining” step, a DocT5Query model is used to generate queries for the first passage in documents, and the corresponding query and document identifiers pairs are used for training the model. Finally, to adapt the model to downstream tasks, it is fine-tuned on the downstream dataset in a supervised fashion.
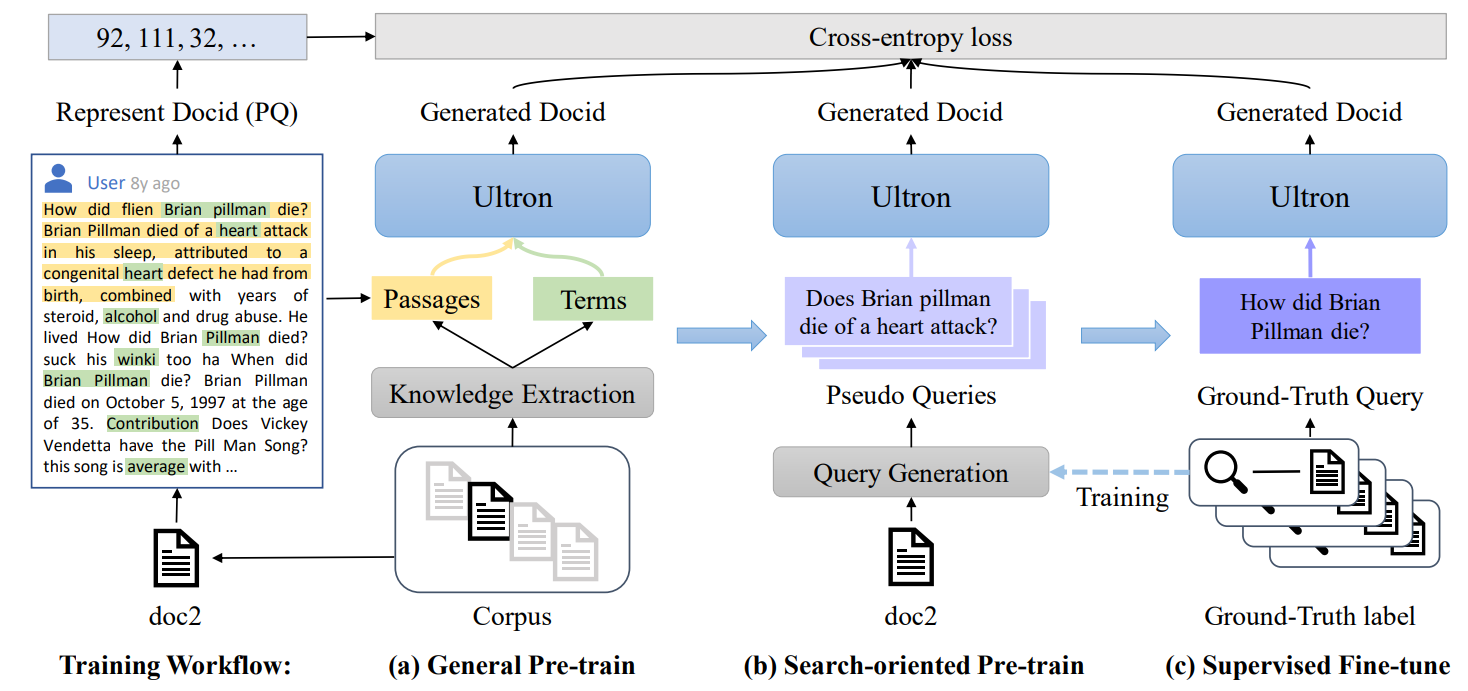
Ultron's Training Workflow -
DynamicRetriever: Similarly, Zhou et al. 19 proposed 3 pre-training tasks: learning passage to identifier mapping, learning sampled words to identifiers mapping, and learning n-grams (that are common across documents) to identifiers mapping. These tasks are helpful for the model to get a local view of document content and to distinguish between similar documents. The authors also propose a variant called OverDense that uses a dual encoder model (fine-tuned with query-document pairs) to initialize the projection matrix of the decoder with dense vectors of each document, before learning the query-identifier mapping.
-
A common idea among these works is that the model is pretrained to memorize the document collection while aligning it with corresponding identifiers. At the fine-tuning stage, the model learns to generate identifiers from query text (retrieval phase).
Retrieval Phase
As mentioned above, during retrieval the trained model gets an input query and autoregressively generates a document identifier. The efficiency of the decoding step is greatly influenced by how document identifiers are structured. The generated identifier may not always be a valid identifier. Hence, the constrained beam search algorithm is used to decode the most likely document identifiers from the predefined candidate set. The generation probability of each identifier is used for ranking the documents 20.
Model Training
Generative Retrieval is implemented through a sequence-to-sequence modeling technique with a pre-trained language model like T5 as the backbone. The model training is optimized cross-entropy loss and is trained with teacher forcing. Note that the DSI paper reported that indexing and fine-tuning together in a multi-task setup yields better results than training these tasks separately. The multi-task learning is:
$$ L_{DSI}^{\theta} = \sum_{d_i \in D} log_{P(i|T5_{\theta}(d_i))} + \sum_{q_j \in Q} log_{P(i|T5_{\theta}(q_j))} $$
Both indexing and fine-tuning use the sequence-to-sequence cross-entropy loss with teacher forcing to update the model’s parameters and the generation stops when decoding a special EOS token. Given a text query or document as input, the basic “text-to-id” task can be denoted as: $ score(d|q) = p_{\theta}(y|q) = \prod_{i=1}^{N} p_{\theta}(y_i|y_{<i},q) $, where y is the string docid of a document d with N tokens, and $\theta$ model parameters.
More specifically, we can think of this paradigm in terms of two tasks: mapping a unique identifier set $\textit{I}(D)$ to each document $D$, and mapping $\Theta(.)$. For an input query $Q$, the model estimates the relevance between $Q$ and $D$ based on the following generation likelihood:
$$ Rel(Q,D) = Agg({\prod_{i=1}^{|I|} Pr(I_i | I_{<i} Q;\Theta): I \in \textit{I}}) $$
where $I$ is an element of $\textit{I}(D)$; $Pr(I_i | I_{<i}Q;\Theta)$ indicates the generation probability of $i$th element $I_i$, given the prefix $I_{<i}$, the query $Q$, and the Seq2Seq model $\Theta$. The function $Agg(.)$ stands for Aggregation of the likelihood for sequences within $\textit{I}(D)$. Methods like DSI use a single sequence for document identification, hence their $Agg(.)$ will simply be the identity function, while SEAL uses an intersective scoring function to aggregate the generation likelihood of different n-grams 21.
Free-form generation might result in an invalid output identifier. To ensure that the generated ID exists in the corpus, a constrained beam search is applied to guide the decoder to search in limited token space at each step. These constraints can be defined based on a prefix tree built on all docid strings. Decoding along the prefix tree ensures that the generated docid exists in the corpus. Finally, the autoregressive scores during beam search a ranked list of top-k results can be returned 3. A recent study found that less than 1 out of 20 DSI-based generation beams were invalid 22.
Optimizations
This section lists some of the ideas proposed by researchers to improve the efficiency and effectiveness of generative retrieval models.
Query Generation
Some recent research works have shown that generative retrieval can greatly benefit from performing indexing with generated synthetic queries 23. The key idea here is that at inference time the generative retrieval model does not explicitly know about the content of each document. So it is critical for the identifiers to be aware of document semantics. There also exists a mismatch between the training data distributions of indexing and retrieval. At indexing time, long text from documents is fed as input, while queries at retrieval time are usually much shorter. The docT5query is one of the most commonly utilized models for generating synthetic queries from documents to augment the training data. These pseudo-queries combined with pre-training tasks help to tackle the limited availability of labeled data.
NCI paper showed that training with augmented queries allowed the model to better understand the semantic meanings of each document. Ultron also utilized generated queries in the “Search-oriented Pretraining” step. Similarly in DSI-QG, Zhuang et al. 23 replace the indexing phase in DSI with a new indexing method in which only the pairs of pseudo-queries (generated from documents) and document identifiers are used for training the model. This is done so that during both indexing and retrieval, the model only sees short queries as input data. The authors also generalize their framework with cross-lingual query generation and suggest an extension in which a cross-encoder ranker is used to rank all the generated queries and only the top-k ranked queries are used to represent the original document. In SE-DSI (Semantically-Enhanced DSI), Tang et al.24 perform elaboration by concatenating each document with a query generated from it and helping the model do rehearsal (document memorization) with important parts of the document.
External Memory
Lee et al.25 argued that the generative retrieval models are limited in their capacity because they solely rely on encoding all the information about the document corpus in their parameters. To overcome this limitation, they proposed using nonparametric contextualized vocab embeddings (external memory) rather than vanilla vocab embedding matrix as decoder vocab embeddings for both the training and the inference steps. This allows the model to use both the parametric and nonparametric space, and a token can now also have multiple token embeddings. The authors also propose three different contextualized embedding encoders.
Distillation
Chen et al.26 proposed a multi-task distillation approach to improve the generative retriever model without altering its structure. The authors utilized a dense retrieval approach to provide effective supervision signals for training the DSI model. A dense retrieval model first selects the top-k text fragments that effectively recall the original documents. These fragments are then added to the training data to provide more unique and comprehensive information.
Learning To Rank
Li et al.9 proposed training the generative retrieval model with an additional passage rank loss for it to learn how to rank passages directly. The authors utilized a margin-based rank loss to assign higher scores to positive passages than to negative passages. This method only requires an additional training step and does not burden the inference stage.
Continual Learning
To add a new document to the dual encoder system, it is first mapped to the joined space using the trained document encoder and then the corresponding vector is included in the nearest neighbor search. Generative Retrieval methods have a significant limitation in that it is not easy to add new documents after a model is trained. Naively retraining the model on all new and old datasets on a regular basis can be very costly and it can also lead to catastrophic forgetting of existing documents (prediction for documents goes from correct to incorrect over the course of learning). The fact that the generative retrieval problem setup has only one labeled example per class makes this problem even worse. Moreover, most of the real-world applications of search systems expect the new documents to be indexed and available in real-time. To address this, several researchers have proposed solutions for continual learning where past information is preserved and used to efficiently learn new concepts.
In DSI++, Mehta et al.27 experimented with the DSI model and showed that almost 88% of documents went through forgetting at least once, and continuously updating with the indexing objective led to forgetting on the retrieval task. They proposed two methods to enable fast model updates and prevent forgetting. First, they suggested modifying the training dynamics by optimizing for flatter loss basins using the Sharpness-Aware Minimization (SAM) optimizer. Recent research has shown that models in flatter loss basins tend to undergo less forgetting. Additionally, they proposed using a “generative memory” for training by sampling pseudo-queries for the already indexed documents and also for the incoming batch of new documents. They showed that with their enhancements, the DSI model memorized 12% more documents.
In StreamingIR, Yoon et al.28 proposed a benchmark to quantify the generalizability of retrieval methods on dynamically changing corpora. In IncDSI, Kishore et al.29 formulate the addition of new documents as a constrained optimization problem that makes minimal changes to the network parameters. They leverage the fact that the output classification layer of the DSI model can be viewed as a matrix where each row corresponds to a document vector. The independence among these vectors allows them to formulate the problem to find the optimal document vector for each new document. Adding a new document class is then done by using pseudo-queries for the new document and ensuring those queries map to the new document. With their method, they are able to add documents in real time (about 20-50ms per document) without retraining the model on the entire or partial dataset.
In CLEVER (Continual-Learner for generative Retrieval), Chen et al.30 a method called Incremental Product Quantization which updates a partial quantization codebook based on two adaptive thresholds. They use quantization to generate PQ codes for documents as docids and represented documents using quantization centroids. The thresholds dictate the updates for centroid representations based on the distance between old and new documents in the representation space. Additionally, they also propose using memory-augmented learning to form meaningful connections between old and new documents.
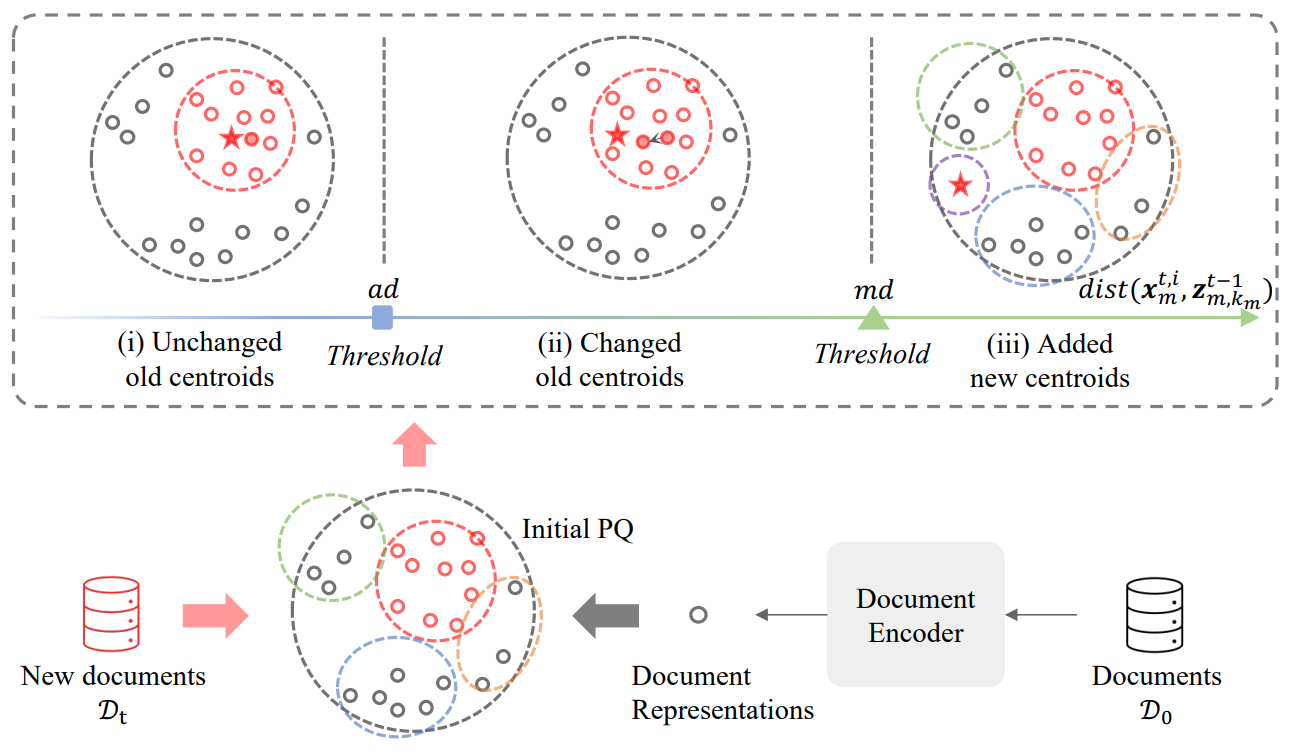
Comparative Performance
The memory footprint of generative models is much smaller than that of traditional sparse or dense retrieval methods. The memory footprint of generative methods is only dependent on the model parameters, while for traditional methods it increases linearly with the size of the document collection 15. Several studies have suggested that the generative retrieval methods when compared with bi-encoders, perform worse when only supervised data is used, perform better when only unsupervised data is available, and perform competitively when both unsupervised and supervised data is used and a continual learning strategy is employed 28. Query augmentation23 and pre-training3 techniques mentioned above have also been shown to help improve the otherwise lackluster vanilla DSI model performance (when compared with dual encoders).
Several studies offer ablation experiments to identify performance and efficiency metrics corresponding to different components in generative retrieval 22 28. Pradeep et al.22 also pointed out that a majority of work research work in generative retrieval only evaluated the model performances on small corpora (order of 100K document), but the retrieval performance drops significantly when the evaluation is done on large corpora. Other evaluations also confirm that the generative retrieval performance still lags behind the state-of-the-art retrieval models 24 13. Liu et al.31 measured the out-of-distribution (OOD) generalization capability of several representative generative retrieval models against dense retrieval models and concluded that generative models still require a lot of enhancements.
Summary
Model-based generative retrieval has emerged as a new paradigm in text retrieval. This framework eliminates the large corpus index used in traditional retrieval methods and memorizes the corpus in its model parameters. It employs a sequence-to-sequence generator to directly generate document identifiers or explicit terms as output, which improves the capturing of relevance between queries and documents and also offers an end-to-end differentiable architecture. Despite simplifying retrieval and reducing the memory footprint of retrieval systems, generative retrieval has a lot of room for improvement when compared with state-of-the-art models. This article provides an introduction to generative retrieval as well as a deep dive into the latest research works being done to optimize, extend, and evaluate this paradigm.
References
-
Lee, H., Yang, S., Oh, H., & Seo, M. (2022). Generative Multi-hop Retrieval. Conference on Empirical Methods in Natural Language Processing. ↩︎ ↩︎
-
Chen, J., Zhang, R., Guo, J., Liu, Y., Fan, Y., & Cheng, X. (2022). CorpusBrain: Pre-train a Generative Retrieval Model for Knowledge-Intensive Language Tasks. Proceedings of the 31st ACM International Conference on Information & Knowledge Management. ↩︎
-
Zhou, Y., Yao, J., Dou, Z., Wu, L.Y., Zhang, P., & Wen, J. (2022). Ultron: An Ultimate Retriever on Corpus with a Model-based Indexer. ArXiv, abs/2208.09257. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Bevilacqua, M., Ottaviano, G., Lewis, P., Yih, W., Riedel, S., & Petroni, F. (2022). Autoregressive Search Engines: Generating Substrings as Document Identifiers. ArXiv, abs/2204.10628. ↩︎ ↩︎
-
Tay, Y., Tran, V.Q., Dehghani, M., Ni, J., Bahri, D., Mehta, H., Qin, Z., Hui, K., Zhao, Z., Gupta, J., Schuster, T., Cohen, W.W., & Metzler, D. (2022). Transformer Memory as a Differentiable Search Index. ArXiv, abs/2202.06991. ↩︎ ↩︎ ↩︎
-
Wang, Y., Hou, Y., Wang, H., Miao, Z., Wu, S., Sun, H., Chen, Q., Xia, Y., Chi, C., Zhao, G., Liu, Z., Xie, X., Sun, H., Deng, W., Zhang, Q., & Yang, M. (2022). A Neural Corpus Indexer for Document Retrieval. ArXiv, abs/2206.02743. ↩︎ ↩︎
-
Metzler, D., Tay, Y., Bahri, D., & Najork, M. (2021). Rethinking Search: Making Experts out of Dilettantes. ArXiv, abs/2105.02274. ↩︎
-
Chen, J., Zhang, R., Guo, J., de Rijke, M., Chen, W., Fan, Y., & Cheng, X. (2023). Continual Learning for Generative Retrieval over Dynamic Corpora. ↩︎
-
Li, Y., Yang, N., Wang, L., Wei, F., & Li, W. (2023). Learning to Rank in Generative Retrieval. ArXiv, abs/2306.15222. ↩︎ ↩︎
-
De Cao, N., Izacard, G., Riedel, S., & Petroni, F. (2020). Autoregressive Entity Retrieval. ArXiv, abs/2010.00904. ↩︎
-
Chen, J., Zhang, R., Guo, J., Fan, Y., & Cheng, X. (2022). GERE: Generative Evidence Retrieval for Fact Verification. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. ↩︎
-
Li, Y., Yang, N., Wang, L., Wei, F., & Li, W. (2023). Multiview Identifiers Enhanced Generative Retrieval. Annual Meeting of the Association for Computational Linguistics. ↩︎ ↩︎
-
Ren, R., Zhao, W.X., Liu, J., Wu, H., Wen, J., & Wang, H. (2023). TOME: A Two-stage Approach for Model-based Retrieval. ArXiv, abs/2305.11161. ↩︎ ↩︎
-
Ziems, N., Yu, W., Zhang, Z., & Jiang, M. (2023). Large Language Models are Built-in Autoregressive Search Engines. ArXiv, abs/2305.09612. ↩︎
-
Sun, W., Yan, L., Chen, Z., Wang, S., Zhu, H., Ren, P., Chen, Z., Yin, D., de Rijke, M., & Ren, Z. (2023). Learning to Tokenize for Generative Retrieval. ArXiv, abs/2304.04171. ↩︎ ↩︎
-
Rajput, S., Mehta, N., Singh, A., Keshavan, R.H., Vu, T.H., Heldt, L., Hong, L., Tay, Y., Tran, V.Q., Samost, J., Kula, M., Chi, E.H., & Sathiamoorthy, M. (2023). Recommender Systems with Generative Retrieval. ArXiv, abs/2305.05065. ↩︎
-
Zhang, P., Liu, Z., Zhou, Y., Dou, Z., & Cao, Z. (2023). Term-Sets Can Be Strong Document Identifiers For Auto-Regressive Search Engines. ArXiv, abs/2305.13859. ↩︎
-
Chen, J., Zhang, R., Guo, J., Liu, Y., Fan, Y., & Cheng, X. (2022). CorpusBrain: Pre-train a Generative Retrieval Model for Knowledge-Intensive Language Tasks. Proceedings of the 31st ACM International Conference on Information & Knowledge Management. ↩︎
-
Zhou, Y., Yao, J., Dou, Z., Wu, L.Y., & Wen, J. (2022). DynamicRetriever: A Pre-training Model-based IR System with Neither Sparse nor Dense Index. ArXiv, abs/2203.00537. ↩︎
-
Nguyen, T., & Yates, A. (2023). Generative Retrieval as Dense Retrieval. ArXiv, abs/2306.11397. ↩︎
-
Zhang, P., Liu, Z., Zhou, Y., Dou, Z., & Cao, Z. (2023). Term-Sets Can Be Strong Document Identifiers For Auto-Regressive Search Engines. ArXiv, abs/2305.13859. ↩︎
-
Pradeep, R., Hui, K., Gupta, J., Lelkes, Á.D., Zhuang, H., Lin, J., Metzler, D., & Tran, V.Q. (2023). How Does Generative Retrieval Scale to Millions of Passages? ArXiv, abs/2305.11841. ↩︎ ↩︎ ↩︎
-
Zhuang, S., Ren, H., Shou, L., Pei, J., Gong, M., Zuccon, G., & Jiang, D. (2022). Bridging the Gap Between Indexing and Retrieval for Differentiable Search Index with Query Generation. ArXiv, abs/2206.10128. ↩︎ ↩︎ ↩︎
-
Tang, Y., Zhang, R., Guo, J., Chen, J., Zhu, Z., Wang, S., Yin, D., & Cheng, X. (2023). Semantic-Enhanced Differentiable Search Index Inspired by Learning Strategies. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ↩︎ ↩︎
-
Lee, H., Kim, J., Chang, H., Oh, H., Yang, S., Karpukhin, V., Lu, Y., & Seo, M. (2022). Nonparametric Decoding for Generative Retrieval. Annual Meeting of the Association for Computational Linguistics. ↩︎
-
Chen, X., Liu, Y., He, B., Sun, L., & Sun, Y. (2023). Understanding Differential Search Index for Text Retrieval. ArXiv, abs/2305.02073. ↩︎
-
Mehta, S., Gupta, J., Tay, Y., Dehghani, M., Tran, V.Q., Rao, J., Najork, M., Strubell, E., & Metzler, D. (2022). DSI++: Updating Transformer Memory with New Documents. ArXiv, abs/2212.09744. ↩︎
-
Yoon, S., Kim, C., Lee, H., Jang, J., & Seo, M. (2023). Continually Updating Generative Retrieval on Dynamic Corpora. ArXiv, abs/2305.18952. ↩︎ ↩︎ ↩︎
-
Kishore, V., Wan, C., Lovelace, J., Artzi, Y., & Weinberger, K.Q. (2023). IncDSI: Incrementally Updatable Document Retrieval. ArXiv, abs/2307.10323. ↩︎
-
Chen, J., Zhang, R., Guo, J., de Rijke, M., Chen, W., Fan, Y., & Cheng, X. (2023). Continual Learning for Generative Retrieval over Dynamic Corpora. ArXiv, abs/2308.14968. ↩︎
-
Liu, Y., Zhang, R., Guo, J., Chen, W., & Cheng, X. (2023). On the Robustness of Generative Retrieval Models: An Out-of-Distribution Perspective. ArXiv, abs/2306.12756. ↩︎
Related Content





Did you find this article helpful?