Zero and Few Shot Recommender Systems based on Large Language Models

Recent developments in Large Language Models (LLMs) have brought a significant paradigm shift in Natural Language Processing (NLP) domain. These pretrained language models encode an extensive amount of world knowledge, and they can be applied to a multitude of downstream NLP applications with zero or just a handful of demonstrations.
While existing recommender systems mainly focus on behavior data, large language models encode extensive world knowledge mined from large-scale web corpora. Hence these LLMs store knowledge that can complement the behavior data. For example, an LLM-based system, like ChatGPT, can easily recommend buying turkey on Thanksgiving day, in a zero-shot manner, even without having click behavior data related to turkeys or Thanksgiving.
Many researchers have recently proposed different approaches to building recommender systems using LLMs. These methods convert different recommendation tasks into either language understanding or language generation templates. This article highlights the prominent work done on this theme.
Why should you use LLMs for building recommendation systems?
A lot of characteristics of LLMs make them a great choice for building recommender systems.
- By expressing user behavior data as a part of the task descriptions (aka prompts), the knowledge stored in LLM parameters can be used to generate personalized recommendations. LLMs’ reasoning capability can infer user interest from the context provided through prompts.
- Research work done in zero and few-shot domain adaptions for LLMs have proven their ability to effectively adapt to downstream domains. This allows startups and large businesses to expand into new domains and set up recommendation applications even with a limited amount of task-specific data.
- Large-scale recommender systems are often built as a multi-step cascade pipeline. Using a single LLM framework for recommendations can help in unifying common improvements, like bias reduction, which are usually tuned at each step. It can even minimize the carbon footprint by avoiding training a separate model for each downstream task.
- In the majority of workflows, these different recommendation tasks share a common user-item pool and have overlapping contextual features. Hence they have a high likelihood of benefitting from unified frameworks for representing inputs and jointly learning from them. Such a learned model will also likely generalize well on unseen tasks.
- Their interactive nature can help with model explainability.
- Their feedback mechanism can help enhance the overall user experience.
Next, we will see various ways in which researchers have proposed to use LLMs for recommender systems.
Pretraining Foundation Language Model on Recommendation Tasks
In Pretrain, Personalized Prompt & Predict Paradigm (P5), Geng et al.1 proposed a unified text-to-text paradigm for building recommender systems. Their framework combines five types of recommendation tasks: Sequential Recommendation, Rating Prediction, Explanation Generation, Review Summarization, and Direct Recommendation. During pretraining, all of these tasks are learned using the same language modeling objective. All of the available data, such as user information, item metadata, user reviews, and user-item interactions are converted to natural language sequences. This rich information in multitask learning setup helps P5 to learn the semantic information required for making personalized recommendations.
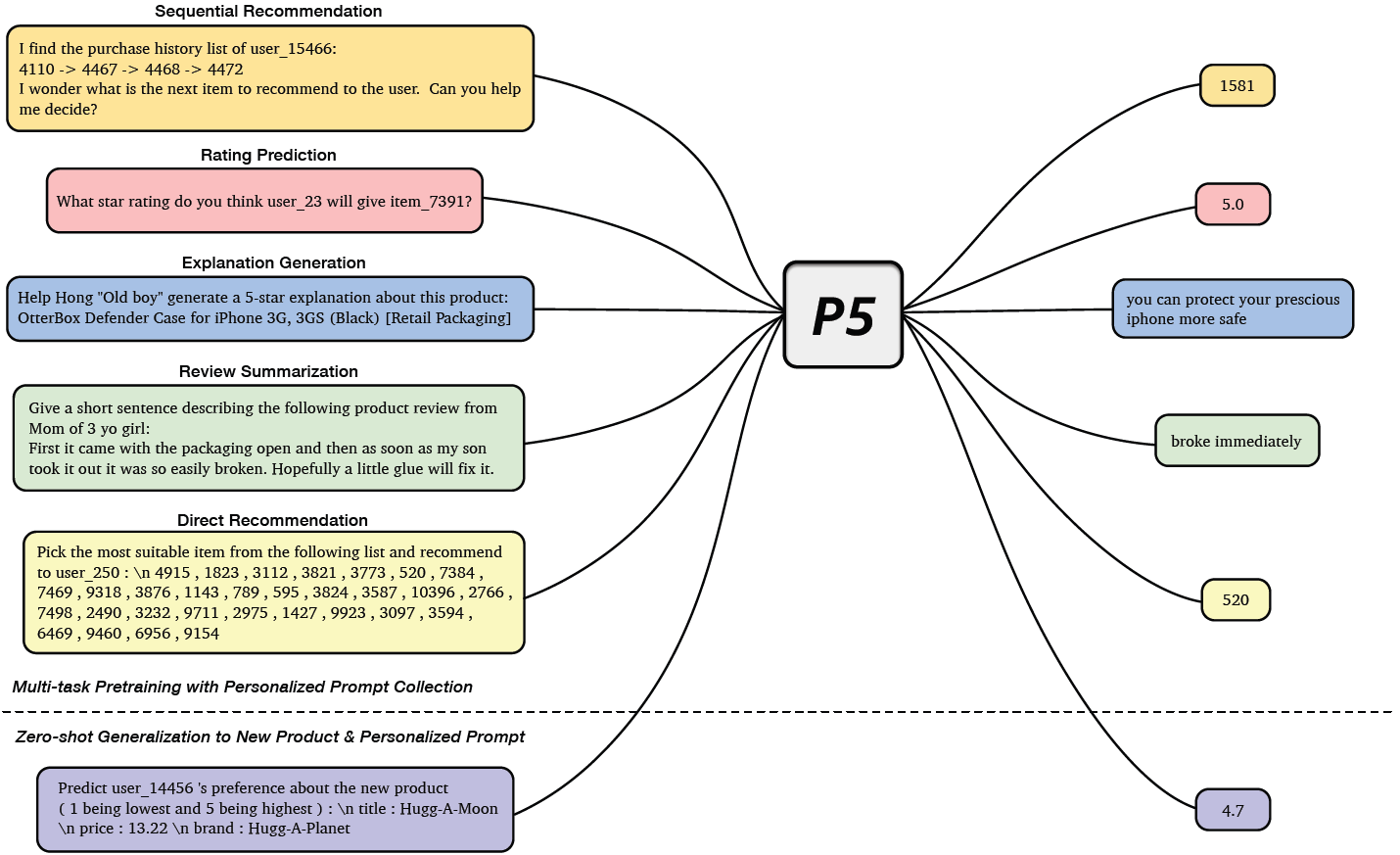
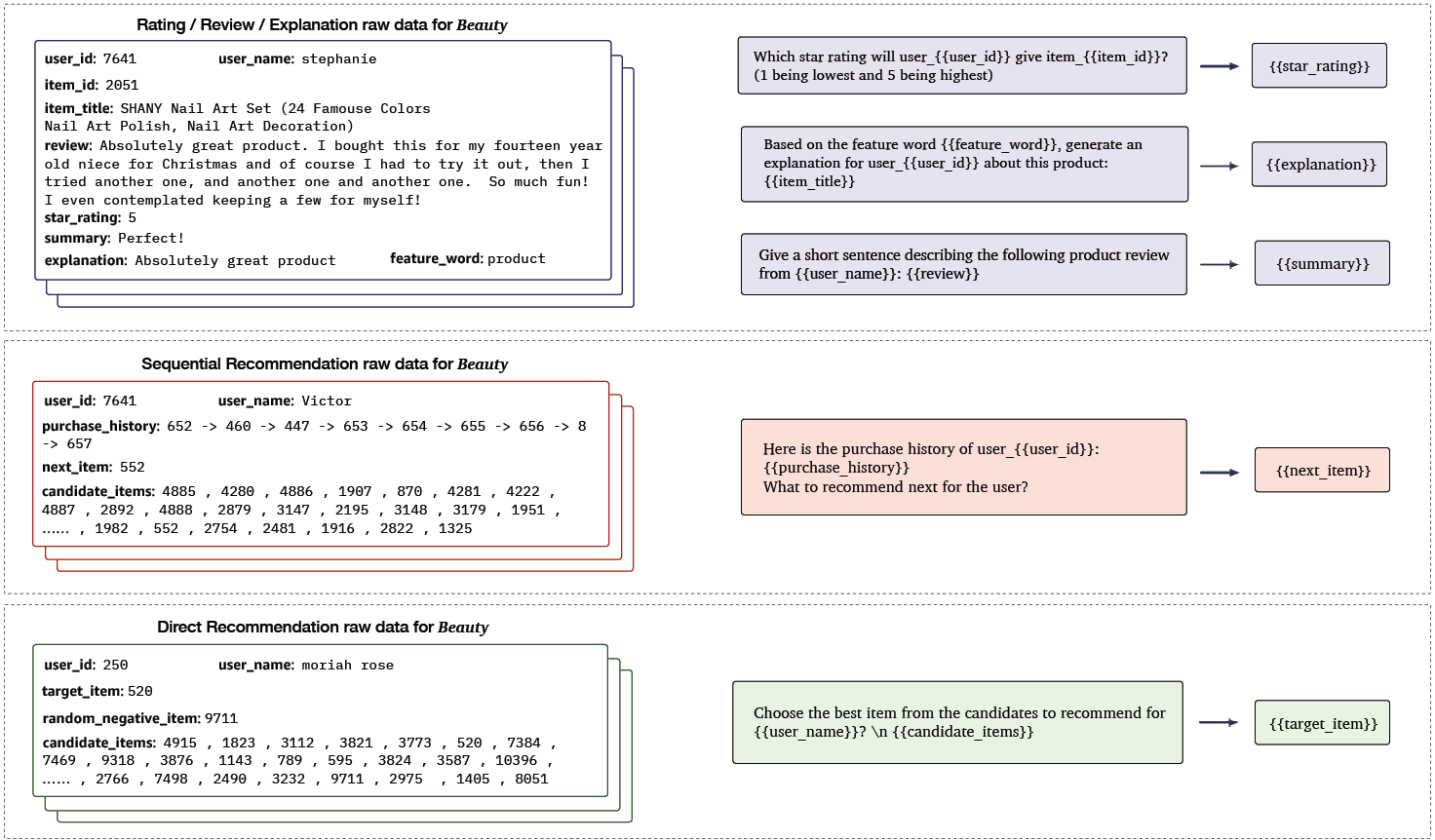
As shown above, P5 learns these related recommendation tasks together with a unified sequence-to-sequence framework by formulating tasks in prompt-based natural language format. The features input is fed to the model using adaptive personalized prompt templates. P5 treats all personalized tasks as a conditional text generation problem and solves them using an encoder-decoder Transformer model pretrained with instruction-based prompts. These personalized prompts have fields for user and item information and can be further categorized into three prompt templates. The following figure shows examples of each prompt template built using the beauty products category from an Amazon dataset.
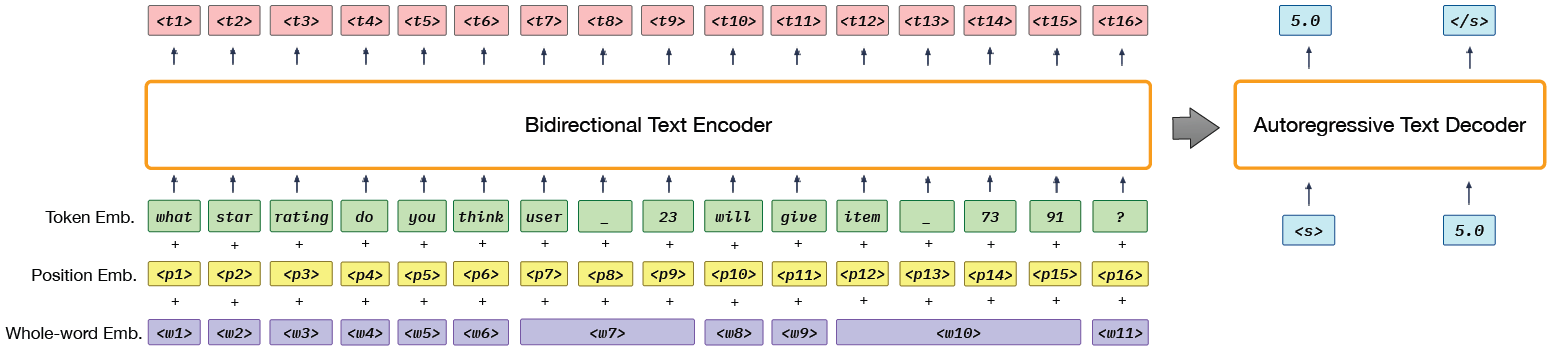
Using the above prompt templates, all input and output data is converted to the same token sequence format. The following figure shows P5’s Transformer model architecture along with an example prompt What star rating do you think user_23 will give item_7391? as input. Note that instead of the sentence-piece tokenization process that divides the user_23 token to user, _, and 23, an independent extra token <user_23> can also be used, however, this approach will incur a significant amount of extra compute. P5 learns to minimize the negative log-likelihood of target tokens given the input tokens along with different performance metrics for different tasks. Note that P5 uses pretrained T5 model checkpoints as the backbone.
The shared task framework enables knowledge generalization such that P5 can serve as a foundation model for various unseen downstream recommendation tasks in a zero-shot or few-shot manner with novel downstream prompts. Through experiments, authors exhibit P5’s zero-shot generalization capability through transfer to unseen personalized prompts and new items in new domains.
Fine-Tuning Pretrained Language Models
Cui et al.2 built a foundation model, M6-Rec, using Alibaba’s pretrained LLM called M6. To train the model, they added a negligible amount (1%) of task-specific parameters without making changes to the original M6 Transformer model. The following diagram shows the M6 architecture that takes sentence inputs to its bidirectional and autoregressive regions and calculates autoregressive loss on the output of the autoregressive region.

The authors represented user behavior as plain texts and converted various recommendation tasks, such as retrieval, scoring, explanation generation, conversational recommendation, etc. to either language understanding or generation. To further adapt to open-domain recommendations, M6-Rec avoids using user IDs or item IDs as input. This enables M6-Rec to be applied to target domains that consist of unseen items.
- For scoring tasks, such as click-through rate prediction and conversion rate prediction, M6-Rec uses the following template.
The text between [BOS'] and [EOS'] tokens represents user-side features and is fed to the bidirectional region, the text between [BOS] and [EOS] represents items as well as information common to both user and items.
- For generation tasks, such as product design and explainable recommendations, it uses the following template.
This prompt is populated using information mined from the product description and user’s review.
- For zero-shot scoring tasks, for example, for a user who clicks hiking shoes prefers trekking poles or yoga knee pads, M6-Rec uses the following template:
[BOS’] A user clicks hiking shoes [EOS’] [BOS] also clicks trekking poles [EOS]
[BOS’] A user clicks hiking shoes [EOS’] [BOS] also clicks yoga knee pads [EOS]
The plausibility of each is calculated based on token probability from M6.
Similarly, for retrieval tasks, M6-Rec feeds user and item prompt information separately to the two regions followed by a nearest-neighbor approach over learned representations. The authors also showed that the trained model could be deployed to edge devices in Alipay through various optimizations such as pruning, early exiting, 8-bit quantization, and parameter sharing.
Prompt-Tuning Pretrained Language Models
Several researchers have proposed various prompt-based fine-tuning methods that enable downstream adaption by using a few examples without any gradient updates or fine-tuning.
LMRecSys
In Language Model Recommender Systems (LMRecSys), Zhang et al.3 use prompts to reformulate the session-based recommendation task as a multi-token cloze task. They use the user’s past interaction history (watched movies), taken from the MovieLens-1M dataset, to predict the next movie that the user would watch. First, they use a rule-based system to create a personalized prompt, similar to the one shown below.
Next, they use a GPT-2 to estimate the probability distribution of the next item by multi-token inference. The probability of the ground-truth item is maximized using a cross-entropy loss. MRR@K and Recall@K metrics are used for evaluation. Through experiments, they showed that in zero-shot settings, the pretrained language model (PLM) outperformed the random recommendations baseline, but also had linguistic biases. In few-shot settings, the PLM underperformed the GRU4Rec baseline.
NIR
In Zero-Shot Next-Item Recommendation (NIR), Wang et al.4 proposed a prompting strategy to perform next-item recommendations in a zero-shot setting. Their method works in the following three steps.
- Candidate Generation: The authors argue that a PLM, like GPT-3, will exhibit poor performance when given a zero-shot prompt like:
Based on the movies I have watched, including..., can you recommend 10 movies to me?because the recommendation space is large. Hence, in their experiment, they used a user-filtering or item-filtering-based external recommendation system component to first construct a candidate set of items. - Three-step Prompting: This step uses GPT-3 and three prompts. First, they prompt GPT-3 to summarize the user’s preferences using the items from the watch history. Next, they use GPT-3’s response and the candidate movies in a prompt to request GPT-3 to select representative movies in descending order of preference. Finally, they create a recommendation prompt to guide GPT-3 to recommend 10 movies from the candidate set that is the most similar to the representative movies.
- Answer Extraction: They use a rule-based extraction method to get the recommended items from GPT-3’s final response. The extracted items can be used in downstream applications, or for performance evaluation.

Chat-REC
In Chat-GPT Augmented Recommender System (Chat-REC), Gao et al.5 used an LLM to augment their conversational recommender system. They first created prompts using user profiles, like age, gender, location, interests, etc., historical interactions, like clicked, purchased, or rated items, and history of dialogues (optional). The LLM is then asked to summarize user preferences. Next, a conventional recommender system is used to generate a large set of candidate items, and finally, LLM narrows down the candidate set to generate the final set of recommendations.
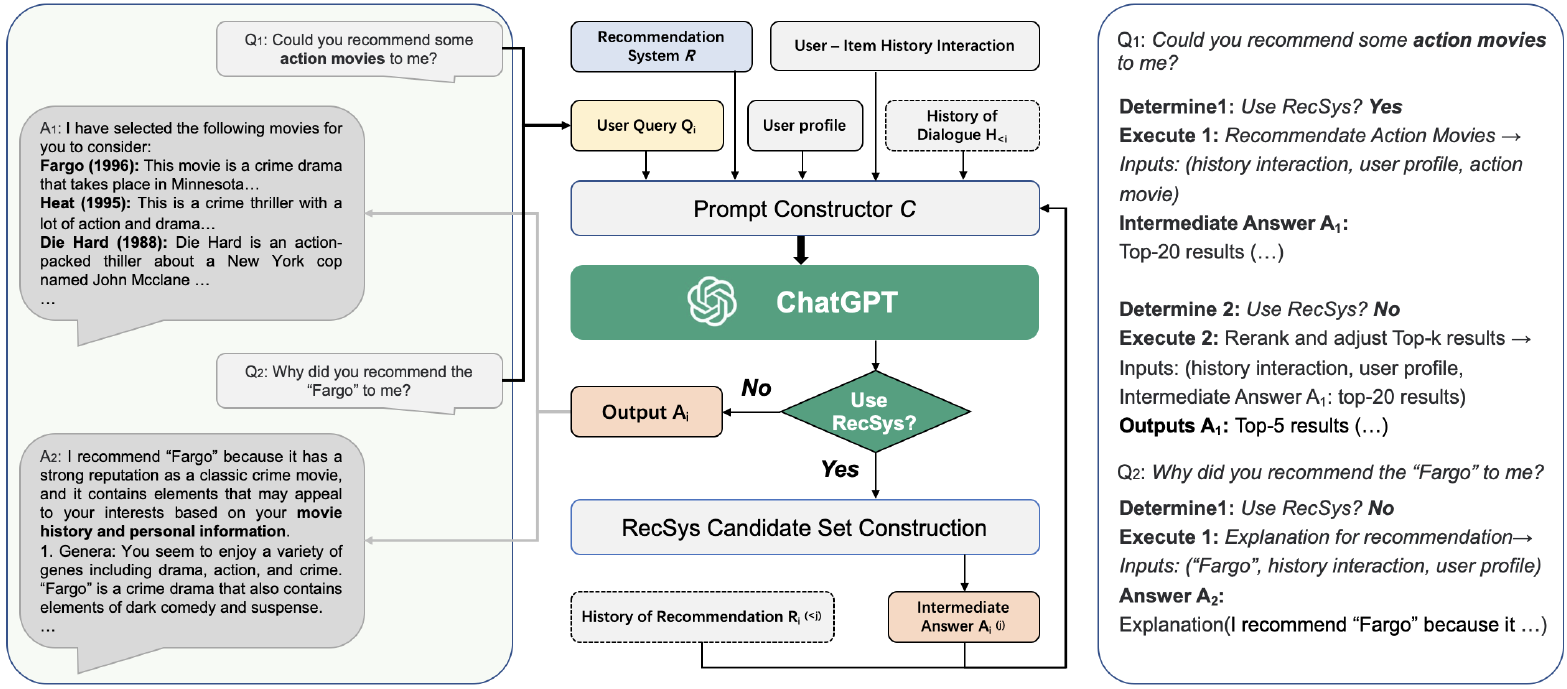
The authors leverage OpenAI’s Chat-GPT as their recommender system interface to enable multi-round recommendations, interactivity, and explainability. To tackle the cold item recommendations (note that current ChatGPT’s training data is capped till September 2021), they recommend using an item-to-item similarity approach using an external source of current information. In their experiments, Chat-REC exhibited good performance on zero-shot and cross-domain recommendation tasks.
Summary
Language grounding is a powerful medium to describe different tasks and modalities in the form of natural language. Pretrained language models (PLMs) have shown remarkable performance on natural language tasks. Expressing different recommendation tasks in natural language opens up a world of possibilities for using large language models for effective recommendations. In this article, I summarized various methods that combine language modeling with user behavior data through personalized prompts for building recommender systems.
References
-
Geng, S., Liu, S., Fu, Z., Ge, Y., & Zhang, Y. (2022). Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5). Proceedings of the 16th ACM Conference on Recommender Systems. ↩︎
-
Cui, Z., Ma, J., Zhou, C., Zhou, J., & Yang, H. (2022). M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems. ArXiv, abs/2205.08084. ↩︎
-
Zhang, Y., Ding, H., Shui, Z., Ma, Y., Zou, J.Y., Deoras, A., & Wang, H. (2021). Language Models as Recommender Systems: Evaluations and Limitations. ↩︎
-
(2023). Zero-Shot Next-Item Recommendation using Large Pretrained Language Models. ↩︎
-
Gao, Y., Sheng, T., Xiang, Y., Xiong, Y., Wang, H., & Zhang, J. (2023). Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System. ↩︎
Related Content





Did you find this article helpful?