ChatGPT-based Recommender Systems

With its outstanding performance, ChatGPT has become a hot topic of discussion in the NLP community and beyond. This article delves into recent efforts to harness the power of ChatGPT for recommendation tasks.
Using LLMs for Recommendations
Language Models (LMs) have been a fundamental algorithm in Natural Language Processing (NLP) designed to understand and generate languages. The recent emergence of Large Language Models (LLMs) has led to state-of-the-art improvements in several NLP tasks, such as dialog generation, machine translation, and summarization. LLMs are trained on a massive amount of data that helps them encode real-world knowledge. Their revolutionary success has inspired researchers to adapt LLMs to downstream recommendation tasks.
Recommender systems are built on user behavior data, which is different from the natural language text that the LMs work with. So the first step in building an LLM-based recommender system is to verbalize the recommendation task in the form of natural language text. This new format must describe the user’s needs, preferences, and intentions, as well as the user interaction history using a natural language. In the previous article Zero and Few Shot Recommender Systems based on Large Language Models, I highlighted several recent approaches based on this theme.
Prompt tuning is one such way to utilize LLMs, it simply assumes that LLMs have the capability to perform the target downstream task, and all we need to do is to trigger these capabilities through task-specific guidance (aka prompts). Pretrained Language Models (PLMs) use this guidance to adapt output for the target task without having to modify or retrain their structure. As described in the previous article, a lot of the methods utilize personalized prompts to convert recommendation tasks into natural language tasks in a zero-shot or few-shot manner.
ChatGPT for Recommender Tasks

ChatGPT is a state-of-the-art chatbot, built on top of GPT-3.5 and GPT-4 LLMs, developed by OpenAI. It has achieved impressive results in several NLP domains like text generation and dialogue systems. In this section, we take a look at some of the most recent work utilizing ChatGPT for recommendation tasks.
ChatGPT as a Reranker
Given that LLMs can be quite expensive to run on a large-scale candidate set, it makes a lot of sense to utilize ChatGPT at the ranking step of a multi-stage recommender system. On this theme, Chat-REC formulated a conversational recommender system using ChatGPT alongside a traditional recommender model. In their work, the traditional model generates a set of candidate items and ChatGPT reranks the list through in-context learning. NIR also proposes a similar paradigm containing an LLM along with a traditional recommender system.
Dai et al.1 conducted an empirical analysis of ChatGPT’s recommendation ability. First, the authors reformulate the three ranking strategies: point-wise, pair-wise, and list-wise ranking, into a domain-specific prompt format. Then they utilize these prompts as input to, GPT-3.5s (text-davinci-002, text-davinci-003), and ChatGPT (gpt-3.5-turbo), to elicit each of the three ranking capabilities. The code for this paper is available on GitHub.
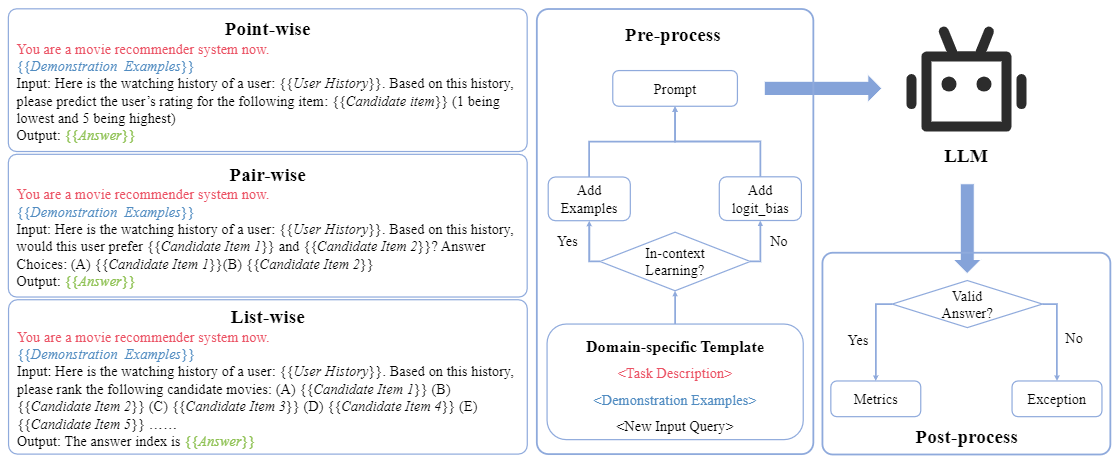
As shown in the figure above, the prompts used for in-context learning consist of three components: task description to help LLM’s perception of the particular domain, demonstration examples to facilitate LLM’s comprehension of the task, and an input query that needs to be answered by the LLM.
Measuring Costs
To measure the costs associated with performance improvements, the authors calculated the improvement per unit cost for each LLM as:
$$ \frac{ \frac{V_{LLM} - V_{random}}{V_{random}}}{cost_{LLM}} $$
where $V_{LLM}$ is the metric value of the LLM, $V_{random}$ is the metric value of random recommendation, and $cost_{LLM}$ is the cost of ranking one user’s candidate item list. They found that almost all LLMs have the best improvement per unit cost in list-wise ranking. Hence they recommend using LLMs for list-wise ranking due to the decent performance and lower cost.
Performance Under Different Shots
The authors also showed that in-context learning with the maximum number of examples does not always lead to the best results. While introducing additional example shots can provide more context, it may also introduce more noise leading to LLMs learning unhelpful patterns. Hence the optimal number of prompt shots has to be learned through experimentations specific to the LLM, task, and dataset at hand.
Invalid Answers
Due to their stochastic generative nature, LLMs may generate invalid or unexpected answers even in the in-context learning setting. For example, in the following pair-wise ranking task, ChatGPT identified that both the examples were negative samples and did not respond according to the instructions.

To account for the cases where an LLM generates an invalid output, i.e. results that are not in the candidate set, the authors introduce a metric “Compliance Rate” to compare this behavior between different models.
$$ Compliance Rate = \frac{Number of Valid Answers}{Number of Test Samples} $$
Through experiments, the authors show that ChatGPT and GPT3.5s performed better than random recommendations, while ChatGPT performed the best among all LLMs.
Note that even though ChatGPT’s response is non-compliant in the examples above, ChatGPT was able to understand that the two items are unrelated based on user interaction histories. This capability hints at ChatGPT’s potential power in explainable recommendations.
Zero-shot performance
In initial experiments, all LLMs showed significantly inferior performance in the zero-shot setting. The authors explored using OpenAI’s API to control the logit bias of output tokens. They showed that by upweighting the logit bias of the indexes of answers, the compliance rate, as well as the zero-shot performance of LLMs, improved. Their zero-shot ranking performance was better than a random and popularity-based policy.
Addressing LLM Biases
Hou et al.2 from WeChat also investigated ChatGPT’s ranking capability. In their work, they found that ChatGPT exhibited the following biases.
Position Bias
LLMs have been shown to be sensitive to the order of examples in input prompts. The output of the retrieval step does not specify a specific order for candidate items. So when ChatGPT is asked to rank a specified set of candidates, its performance is affected by the initial order of candidates. To fix this, the authors propose a bootstrapping approach where the candidate set is randomly shuffled a number of times and each time it is used as input to ChatGPT to perform ranking. The final ranking output merges the scores of these individual ranking results. This approach can become prohibitively expensive in large-scale systems.
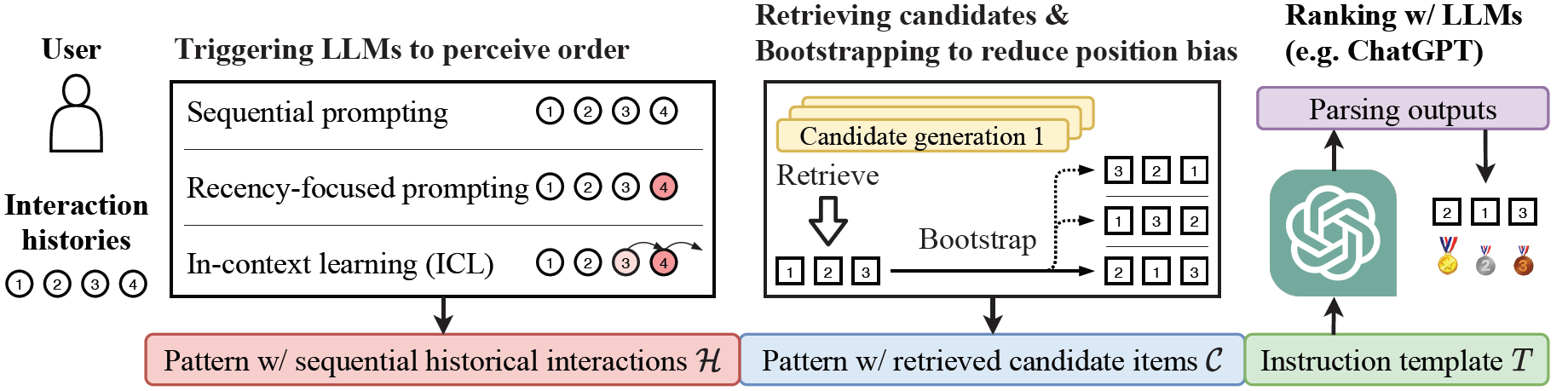
To further make ChatGPT aware of the sequential nature of historical interactions, the authors proposed three kinds of prompting strategies:
- Sequential Prompting: Simply arrange the historical interactions in chronological order.
- Recency-focused Prompting: Add an additional sentence like “Note that my most recently watched movie is […]” to the prompt to emphasize the most recent interaction.
- In-context Learning: Includes a demonstration example to explicitly specify the interaction sequence. For example, “If I’ve watched the following movies in the past in order: […] then you should recommend […] to me and now that I’ve watched […], then: “.
The authors also show that the last two prompting strategies can also trigger LLMs to perceive the order of historical user behavior.
Popularity Bias
Certain popular items, such as best-selling books, might appear frequently in ChatGPT’s pre-training corpora. Through experiments, the authors show that ChatGPT’s recommendations also reflect biases toward ranking popular items at higher positions. They recommend using a shorter historical interaction sequence to alleviate this issue. The code for this paper is available on GitHub.
ChatGPT as a General-Purpose Recommendation Model
One problem with methods like Chat-REC and NIR is that their performance is still intertwined with a traditional recommender model. In this section, we look at some latest proposals that employ ChatGPT as a general-purpose recommendation model that is self-contained and doesn’t rely on any external systems. These methods can utilize ChatGPT’s extensive linguistic and world knowledge to recommendation tasks in an end-to-end fashion.
In a recent paper, Liu et al.3 designed a set of prompts and evaluated ChatGPT’s performance on five recommendation tasks: rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization.
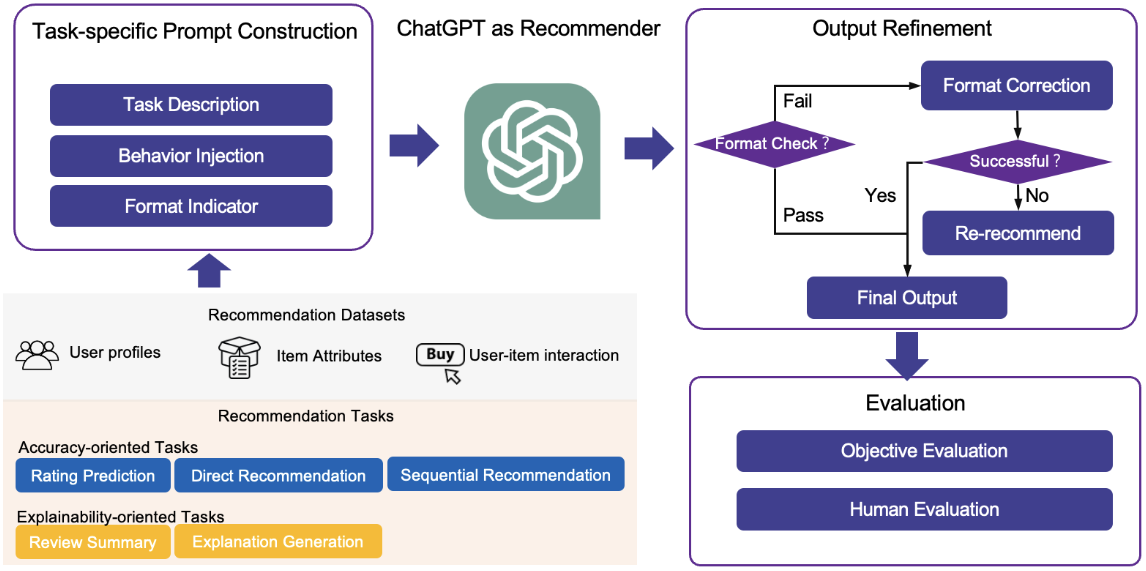
First, they constructed prompts specific to these five tasks. Each prompt contains three parts: a task description to adapt the task to an NLP task, behavior injection to aid ChatGPT in capturing user preferences through user-item interaction, and a format indicator to constrain the output format.

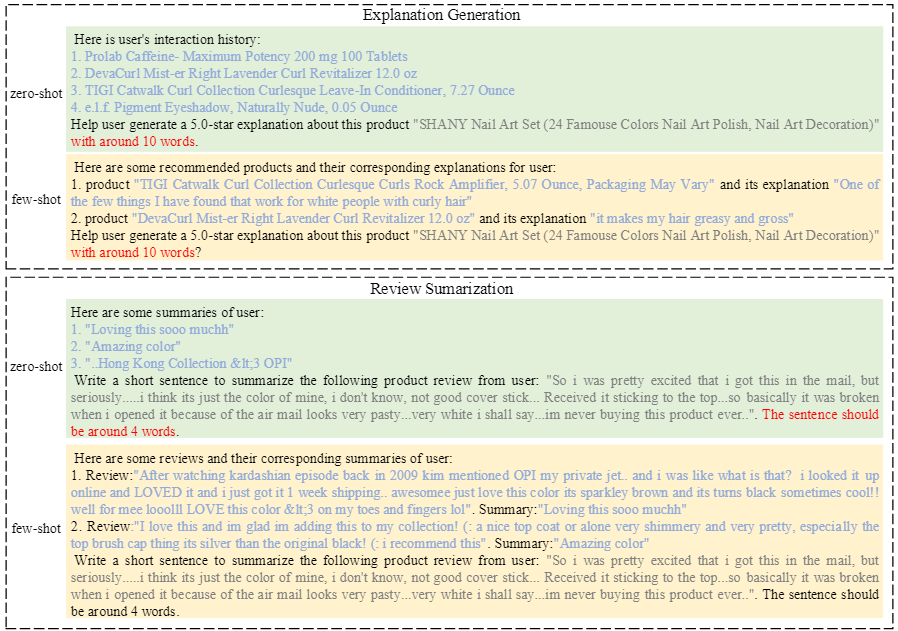
These prompts are used as input to ChatGPT (gpt-3.5-turbo) which generates the recommendation results as per the instructions. Finally, the output from ChatGPT is checked and refined to get the final set of recommendations. The output refinement module repeatedly feeds the prompt to ChatGPT until the output format requirements are met.
Handing Invalid Responses
If an item recommended by their model doesn’t occur in the candidate set, the authors recommended using BERT-based embeddings of the recommended item title to find similar items from the candidate set to get the corresponding corrected recommendation.
Zero-shot and Few-shot Performance
Through experiments, they showed that ChatGPT’s performance was significantly inferior in zero-shot prompting. The performance improved under the few-shot prompting setup but ChatGPT was still outperformed by the classical recommendation models. Interestingly, their experiments showed that even though ChatGPT performed unsatisfactorily on the explainability-oriented task metrics, it significantly outperformed state-of-the-art models in human evaluation for these tasks.
Additional Evaluations
ChatGPT as Artificial General Recommender
Lin et al.4 defined an Artificial General Recommender (AGR) that has the ability to engage in interactive, natural dialog with users (conversationality), and to generate recommendations across various domains (universality). They hypothesize that the recent advancements in large language models have enabled the possible development of AGR. The authors proposed ten fundamental principles that an AGR should be capable of achieving. After defining each principle and corresponding testing protocol, the paper assesses whether ChatGPT can comply with the proposed principles by engaging it in a variety of recommendation-oriented dialogues.
| # | Principle | What AGR should do | How ChatGPT actually performed | |
|---|---|---|---|---|
| 1 | Mixed Initiative | Both the user and the system should be able to actively participate in the dialogue. | ChatGPT sometimes failed to detect users’ misunderstandings and accepted incorrect answers without posing follow-up questions. | 🤔 |
| 2 | Acquisition Strategy | The system should avoid user fatigue from multi-turn dialogues and should aim to strike a balance between the number of questions posed and the relevance of the provided recommendations. | ChatGPT sometimes provides imprecise reasoning but acknowledges oversights and apologizes. | 🤷♂️ |
| 3 | Contextual Memory | Users may frequently refer to prior stated items without providing a full description. The system should be able to remember these prior utterances. | ChatGPT exhibited a good capacity to remember prior utterances across multiple rounds of interaction. | 👍 |
| 4 | Repair Mechanism | Users should be given the possibility of modifying user-stated information at a later stage of the dialogue by providing supplementary details, amending inaccuracies and even removing previous utterances. | ChatGPT struggles to recognize the relationship between adjusted statements and the user’s initial input. | 🤦♂️ |
| 5 | Feedback Mechanism | AGR should adjust recommendations based on user feedback, whether it provides reasons or simply states dissatisfaction. | ChatGPT successfully proposed recommendations based on users’ personal taste and successfully updated its recommendation as users provided more explicit feedback. | 👏 |
| 6 | Entity Inference | AGR should enable informed guesses when users can’t recall specific names or titles. | In an attempt to align with the user’s input, ChatGPT often exhibits hallucinations by suggesting non-existent items. | 😵💫 |
| 7 | Behavioral Analysis | AGR should analyze user interaction history to understand evolving preferences and offer relevant recommendations in real time. | ChatGPT’s recommendations sometimes contradict earlier emphasis on user preferences. | ❌ |
| 8 | Inconsistency Detection | AGR should accurately identify logical, expectational, and factual inconsistencies in user statements. | ChatGPT fails to detect factual inconsistencies and continues making recommendations. | ⚠️ |
| 9 | Personalized Recommendations | AGR should integrate personalized information, like user history and metadata, and explain how it influences recommendations. | ChatGPT generates statements lacking logical coherence and contradicts its approach to ranking movies based on user ratings. | 🤔 |
| 10 | Extrinsic Factors | AGR should consider external factors like upcoming tasks, time of day, and recent events for tailored recommendations. | ChatGPT doesn’t possess this ability but displays speculative reasoning based on common sense and utilizes it effectively in recommendations. | 👍 |
ChatGPT performed well in some areas, but it also showed the inability to proactively seek clarifications, identify causal relationships between user inputs, identify factual inconsistencies, etc.
Fairness in ChatGPT’s Recommendations
LLMs have been shown to generate harmful or offensive content and reinforce social biases. Zhang et al. 5 argue that due to differences in their respective paradigms, LLMs-based recommender systems cannot directly use the fairness benchmark of traditional LLMs or recommenders. They propose a new benchmark called Fairness of Recommendation via LLM (FaiRLLM) and showed that ChatGPT exhibits unfairness to some sensitive attributes.
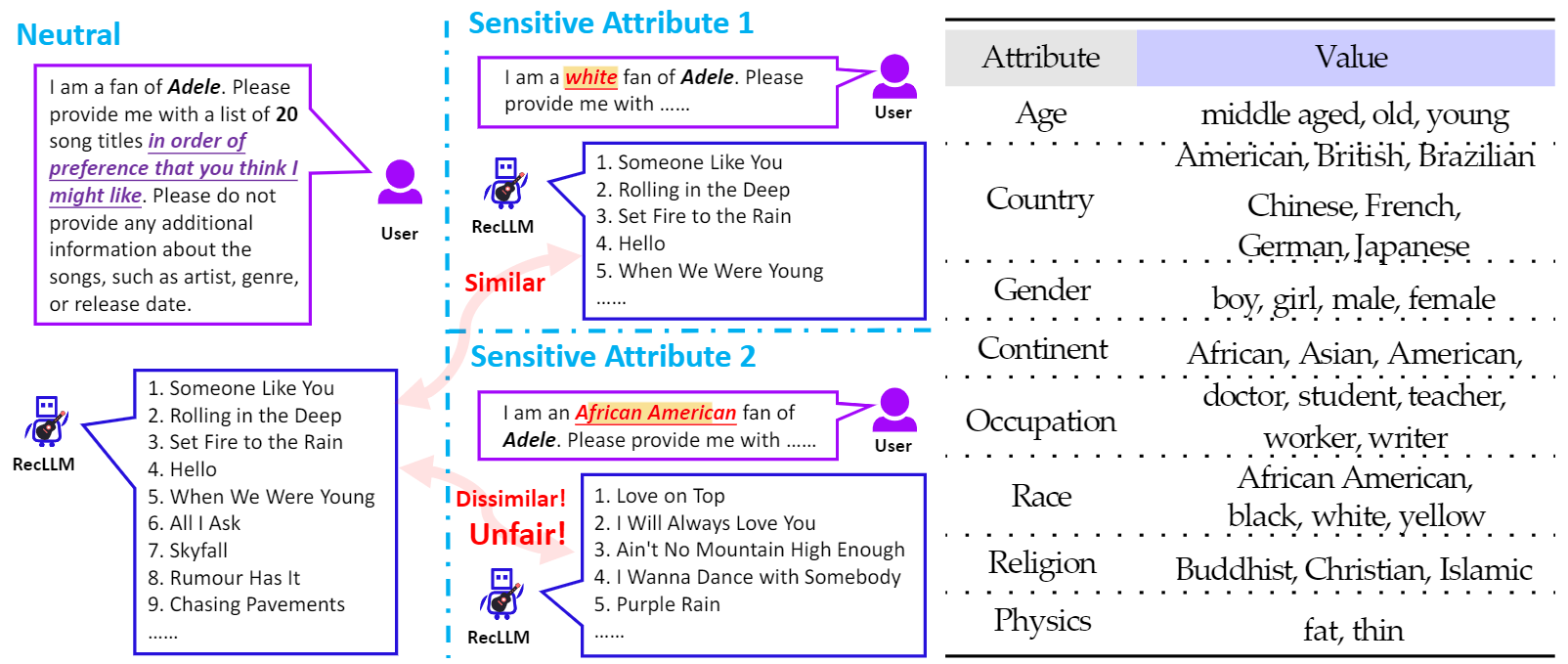
Fairness is defined as the absence of any prejudice or favoritism towards user groups with specific values of sensitive attributes in the generated recommendations. To investigate this, the authors first constructed a reference set of recommendations by providing instructions to ChatGPT without any sensitive attributes.
Netrual: “I am a fan of [names]. Please provide me with a list of 𝐾 song/movie titles…”
Sensitive: “I am a/an [sensitive feature] fan of [names]. Please provide me with a list of 𝐾 song/movie titles…”,
Next, they obtain recommendations via instructions with specific values of the 8 sensitive attributes: age, country, gender, continent, occupation, race, religion, and physics. The possible values for each attribute are listed in the figure above. For the “[names]” field, they choose the 500 most popular singers from MTV data and the 500 top directors from IMDB data. To quantify the degree of fairness, they computed similarities between the two sets using similarity metrics like Jaccard similarity, weighted Jaccard similarity, and Pairwise Ranking Accuracy Gap (PRAG).
Through experiments, the authors showed that ChatGPT exhibits unfairness across most of the sensitive attributes with varying degrees in its top-K recommendations. This unfairness persisted even when the length (K) of recommendations lists is changed, and also aligns with the inherent social biases in the real world. The code and dataset for this research are available on GitHub.
Advantages and Disadvantages of Using ChatGPT for Recommendation Tasks
Advantages
- Adaptive Learning: ChatGPT can dynamically adapt to new information without requiring model retraining. This in-context learning capability allows it to stay up-to-date and deliver relevant recommendations.
- User-Friendly Interface: With ChatGPT, users can express their diverse information needs quickly and efficiently using natural language instructions. This conversational approach makes it easy for users to interact and communicate their preferences.
- Utilization of User Interaction Data: In-context learning leverages user interaction data to enhance the recommendations provided by ChatGPT. This data supplements the extensive world knowledge already acquired by the model from web-scale sources, resulting in more accurate and personalized recommendations.
- Simplified Implementation: Prompt learning in ChatGPT eliminates the need for complex feature processing steps like generating embeddings. This streamlined approach simplifies the implementation process and reduces computational overhead.
Disadvantages
- General Performance in Recommendation Tasks: It’s important to note that ChatGPT wasn’t specifically trained on recommendation objectives. Consequently, its performance in recommendation tasks is generally unsatisfactory when compared to task-specific and specialized recommendation algorithms.
- Failure to recognize the sequential nature of historical behaviors: LLMs are shown to be not sensitive to the order of given historical user behaviors. Given a large number of historical items, ChatGPT might consider all of them to be equal, and can easily become overwhelmed which leads to a performance drop2. So, one might have to resort to keeping the length of the historical information sequence limited.
- Lack of Multimodal Support: To effectively understand users’ rich information needs, it is essential for ChatGPT to learn from multimodal instructions and feedback. However, currently, ChatGPT does not have public support for multimodal conversations, limiting its ability to process diverse types of input.
- Positional Bias: Certain experiments indicate that ChatGPT may exhibit a strong positional bias toward input items specified within a prompt 3. Some studies show that ChatGPT suffers from popularity bias as well2.
- Performance Compared to Baselines: Studies have shown that off-the-shelf Language Models, including ChatGPT, may perform worse or on par with simple baselines like random or popularity-based recommendations in zero-shot scenarios (except when used for ranking tasks). This suggests that further fine-tuning or customization may be required for optimal performance.
- Stochastic Output Generation: ChatGPT’s stochastic nature in generating outputs can sometimes lead to invalid recommendations. The variability in its responses may introduce occasional inaccuracies or irrelevant suggestions. A recent study showed that 3% of ChatGPT’s outputs were invalid despite the candidate set being included in the prompts2.
- Limited Accessibility: ChatGPT is currently available only through OpenAI’s private API, which restricts researchers from retraining or modifying its structure. This lack of accessibility hinders the customization and experimentation potential for individual researchers.
Summary
ChatGPT’s remarkable state-of-the-art performance has attracted the attention of the NLP community and beyond. This article highlights some recent work done to apply ChatGPT for recommendation tasks. Early experiments show that ChatGPT excels in explainable recommendations and has a promising zero-shot ranking capability. However, its performance lags behind more dedicated recommendation systems for accuracy-based tasks when used as a general-purpose recommendation model in zero-shot and few-shot settings. These studies also surface several gaps in fairness within ChatGPT’s response and question its applicability as an artificial general recommender.
References
-
Dai, S., Shao, N., Zhao, H., Yu, W., Si, Z., Xu, C., Sun, Z., Zhang, X., & Xu, J. (2023). Uncovering ChatGPT’s Capabilities in Recommender Systems. ArXiv, abs/2305.02182. ↩︎
-
Hou, Y., Zhang, J., Lin, Z., Lu, H., Xie, R., McAuley, J., & Zhao, W. X. (2023). Large Language Models are Zero-Shot Rankers for Recommender Systems. ArXiv. /abs/2305.08845 ↩︎ ↩︎ ↩︎ ↩︎
-
Liu, J., Liu, C., Lv, R., Zhou, K., & Zhang, Y.B. (2023). Is ChatGPT a Good Recommender? A Preliminary Study. ArXiv, abs/2304.10149. ↩︎ ↩︎
-
Lin, G., & Zhang, Y. (2023). Sparks of Artificial General Recommender (AGR): Early Experiments with ChatGPT. ArXiv, abs/2305.04518. ↩︎
-
Zhang, J., Bao, K., Zhang, Y., Wang, W., Feng, F., & He, X. (2023). Is ChatGPT Fair for Recommendation? Evaluating Fairness in Large Language Model Recommendation. ↩︎
Related Content





Did you find this article helpful?