Diffusion Modeling based Recommender Systems

Generative Modeling for Recommender Systems
The task of learning a user’s preference based on historical interactions and predicting the next item is essential to most modern recommendation systems. Most of the traditional deep learning approaches for sequential recommendations, like MLPs, CNNs, RNNs, and Transformers, represent items as a dense vector in latent space, and suffer from two issues:
- A fixed-length vector does not fully capture the uncertainty and diversity of a user’s interests.
- These methods lead to exposure bias because of the underlying assumption that the true interacted item is the most relevant one.
To address these shortcomings, several generative models such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) are utilized to infer the user interaction probabilities over non-interacted items. These models use a generative process in which the user preferences are considered latent factors that determine users’ interaction behaviors. Sampling from the learned probability distribution mimics the uncertainty of user behavior.
- GANs learn a generator and a discriminator adversarially. While the generator estimates users’ interaction probabilities, the discriminator provides guidance to the generator. For example, in IRGAN1 researchers proposed a generative retrieval GAN model to serve item recommendations, and the SD-GAR2 paper further improved the process with a sampling-decomposable generator. However, this adversarial training often leads to poor performance due to the instability of adversarial training.
- VAEs maximize the likelihood of historical interactions to learn a posterior distribution over latent factors. For example, Liang et. al3 used VAEs to perform collaborative filtering over implicit feedback, and in ACVAE4 authors augmented a sequential VAE with adversarial training to capture user preferences. Despite outperforming GANs for recommendations, VAEs struggle to balance the tradeoff when a simple encoder fails to capture heterogeneous user preference and a complex one makes the posterior distribution calculation to be intractable.
Towards Diffusion Models for Recommendations
Apart from the problems mentioned above, both GANs and VAEs suffer from posterior collapse due to information bottleneck, so the hidden representation may not contain information about the user preference. These methods are also prone to mode collapse where they generate only a small set of outputs over multiple iterations. To tackle these challenges, a new paradigm of generative models called diffusion models has been utilized by various researchers recently. These diffusion models overcome the issues of traditional generative models and produce more accurate modeling of the complex user interaction in a denoising manner.
Introduction to Diffusion
The Diffusion Model (DMs) is a new generative AI paradigm that is inspired by nonequilibrium thermodynamics. These models have achieved state-of-the-art results in various fields such as image synthesis, audio generation, etc. Dall-E2 by OpenAI, Imagen by Google, Stable Diffusion by StabilityAI, and Midjourney are some of the most popular diffusion models.
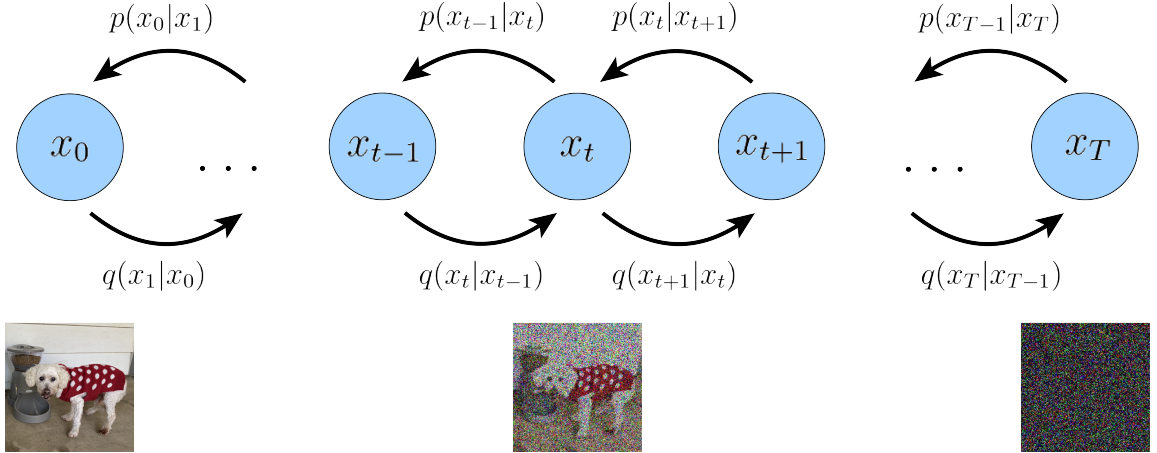
The diffusion process works in the following two steps:
-
Forward Process: Given an input data sample $x_{0}$, sampled from a distribution $q(x)$, forward diffusion creates latent variables $x_{1:T}$, using a Markov chain of $T$ steps, by gradually adding Gaussian noises at each step. Formally, we can define forward transition ${x}_{t-1} \to x_t$ as:
$$q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t}{x}_{t-1}, \beta_t{I})$$
where $t$ is the diffusion step, $\mathcal{N}$ is the Gaussian distribution, $I$ is an identity matrix, and $\beta_t \in (0,1)$ is the noise scale at each step. $\beta_{t}$ can also be defined using a linear, quadratic, sqrt, or cosine variance schedule. For $T\to\infty$, $x_T$ approaches a standard Gaussian distribution. Thanks to the reparameterization trick and additivity of two Gaussian noises, we can directly obtain $x_{t}$ from $x_{0}$.
-
Reverse Process: In this step, a neural network (parameterized by $p_{\theta}$), such as a Transformer or a U-Net, learns to remove the added noises from $x_t$ to recover $x_{t-1}$ . The network takes $x_t$ as input and learns to denoise it to $x_{t-1}$, iteratively by: $$p_{\theta}(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_t, t), \Sigma_{\theta}(x_t, t))$$
where $\mu_{\theta(x_t,t)}$ and ${\Sigma}_\theta({x}_t,t)$ are the mean and covariance of the Gaussian distribution predicted by the network with parameters $\theta$.
Essentially, in the forward process, DMs gradually convert the original data to Gaussian noises using a Markov chain. In the reverse process, a neural network takes the noised data and reconstructs the original data in multiple diffusion steps. Having no learnable parameters in the forward chain helps in avoiding the posterior collapse, and having only a single neural network (as opposed to generator-discriminator or encoder-decoder in GANs or VAEs) avoids the mode collapse problem.
Diffusion models are optimized by maximizing the Evidence Lower Bound (ELBO) of the likelihood of observed input data $x_{0}$:
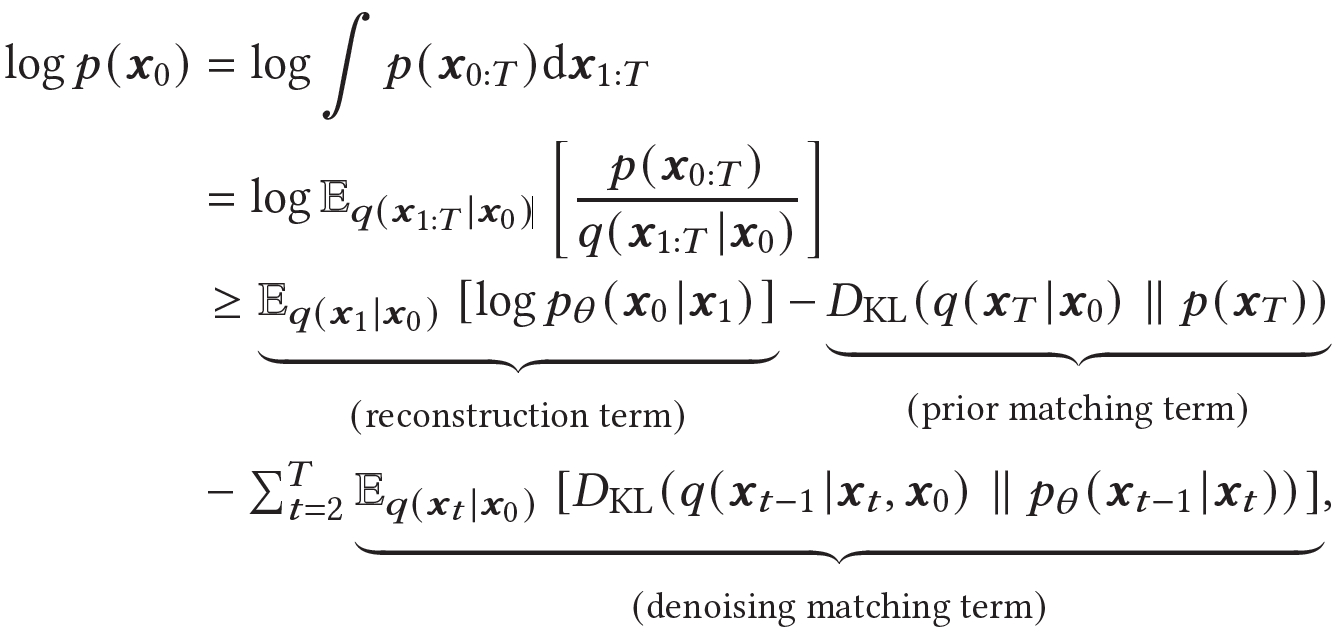
Here reconstruction term is similar to the ELBO of a VAE and measures the recovery probability of $x_0$, the prior matching term is a constant value that is ignored during training, and the denoising matching term is the difference between the desired and approximated denoising step. For further details, please refer to Luo et. al5.
At inference time, diffusion models draw $x_T \sim \mathcal{N}(0,I)$ and utilize the denoising step $p_{\theta(x_{t-1} | x_t)}$ to iteratively repeat the generation process $x_T \to x_{T-1} \to \dots \to x_0$. This iterative process makes them slow at sampling, at least compared to GANs.
Why Should You Use Diffusion for Recommendations?
Real-world recommendation applications often have to deal with complex scenarios that cannot be encoded in a single vector representation. Such as:
- Users’ interests and preferences are dynamic, diverse, and inconsistent.
- Items contain multiple complex latent aspects.
- Users’ currently known preferences are always uncertain to some degree due to diversity and the evolution of interests.
Soft-attention and dynamic-routing-based methods like DIN, MIND, and ComiRec can do multi-interest modeling, but they also require a predefined number of interests. It is possible to address some of these concerns by modeling users’ current interests as a distribution. Generative methods like VAEs can model the multiple latent aspects of an item as a distribution and inject uncertainty as Gaussian noises. But as explained earlier, these traditional methods suffer from a lot of issues like mode collapse, and Diffusion Models are much better alternatives.
The goal of recommender systems is to predict future interaction probabilities based on historical interactions. In practice, the collected user interactions in implicit feedback can be considered naturally noisy (or corrupt) due to false-positive and false-negative interactions. Hence the objective of the diffusion model to predict probabilities based on the iterative denoising process aligns well with recommender systems. We can use DMs to predict users’ future interaction probabilities based on corrupted interactions by learning to recover the original interactions. Then these probabilities can be used to rank and recommend items.
Diffusion-based Recommender Systems
In the last couple of weeks, several researchers have proposed ways to utilize diffusion models for recommendation tasks. This section highlights some of those ideas.
DiffRec by Soochow University
Du et. al6 proposed DiffRec to adapt the diffusion model to sequential recommendations task. Diffusion models originally process continuous data (like images, and audio). To adapt them to discrete recommendation data, this paper added one additional transition that maps discrete items into hidden representation in the forward process. Another transition was added in the reverse process that converts hidden representation back to the probability distribution over the items by using a linear layer. An additional KL-Divergence term is also introduced in the objective function to control the behavior of this additional transition.
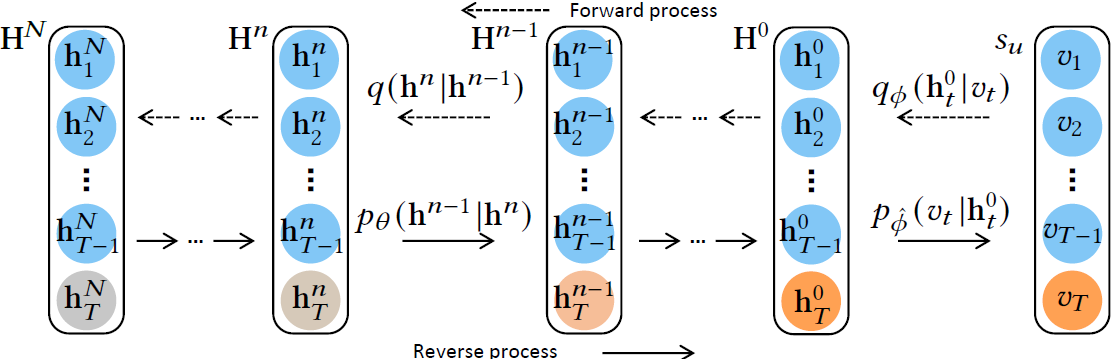
To further make the diffusion model suitable for the recommendations domain, noising, and denoising are done only on the hidden representation of the target item instead of the whole sequence. The authors also proposed a simplification trick that rewrites the KL divergence term in the objective function as the mean square error. This allows for a neural network $f_{\theta}$ that can directly predict $h_T^0$ based on $h_T^n$. The paper used a Transformer Encoder as the neural network and named it Denoise Sequential Recommender (DNR).
Modern recommender systems can have millions or billions of users and items. This means that the training and inference cost for the multiple diffusion steps can be extremely costly. To alleviate this, only the important diffusion steps (highest MSE loss) are sampled, as opposed to calculating model output at all diffusion steps, during training and benefit from the direct inference of $h_T^0$ from any diffusion step during inference.
The experiments conducted by the paper used three public benchmark datasets and showed that DiffRec outperforms the state-of-the-art sequential recommendation models like GRU4Rec, SASRec, BERT4Rec, and STOSA, and several generative and contrastive methods as well.
DiffRec by National University of Singapore
Wang et. al7 proposed a Diffusion Recommender Model (DiffRec) to infer user interaction probabilities in a denoising manner to serve sequential recommendations. In the forward step, DiffRec uses a linear noise schedule to gradually corrupt user interaction histories by injecting scheduled Gaussian noises. During the reverse step, it recovers the original interaction from corrupted interactions iteratively by predicting Gaussian parameters via a parameterized neural network (like an MLP).
The authors hypothesize that using pure noising like in image synthesis for interaction histories can hurt personalized recommendations, so they keep the added noise in forward pass to a minimum, meaning that the latent variable $x_T$ does not approach the standard Gaussian noises. They also propose a simplification of denoising matching terms in ELBO to make the approximation tractable and use the importance sampling similar to the previous method.
The paper proposed two extensions of DiffRec: Latent DiffRec (L-DiffRec) for scalable and cost-efficient large-scale item prediction and Temporal DiffRec (T-DiffRec) for temporal modeling to facilitate the use of DiffRec in practical recommender systems.
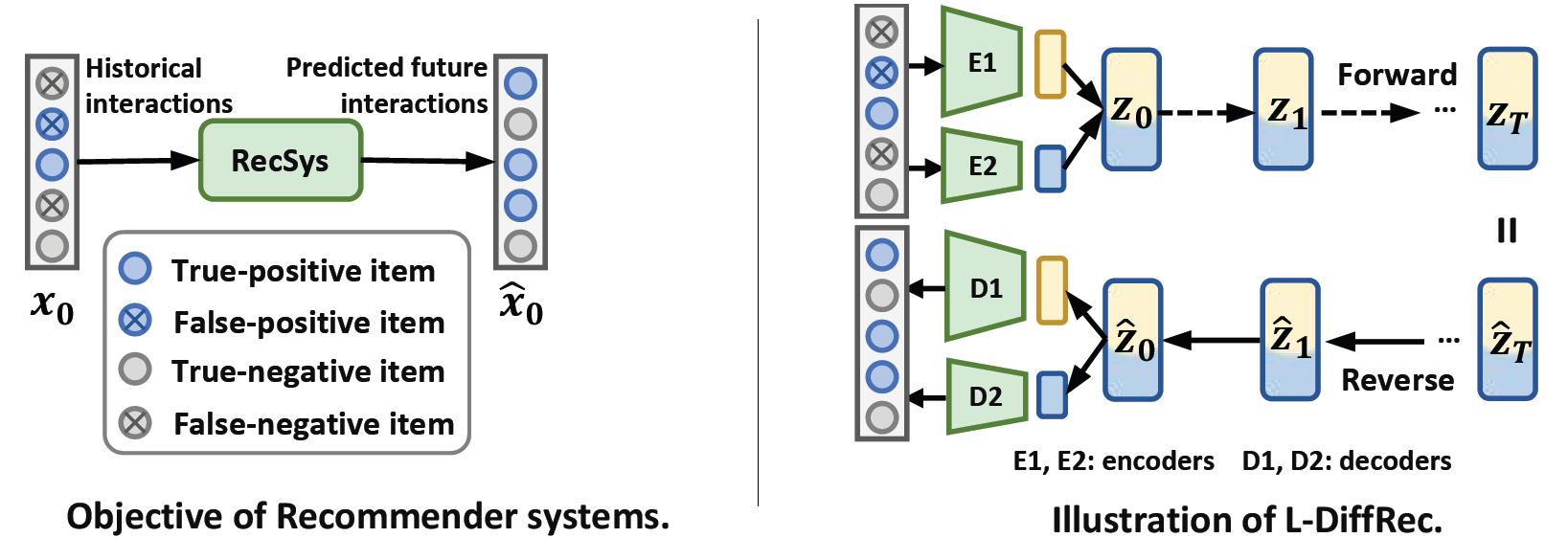
In L-DiffRec, the k-means method is used to cluster the item set into $C$ categories using the item embeddings learned from a LightGCN algorithm. The user interaction vector $x_0$ is then divided into $C$ parts according to the clusters. A variational encoder is then used to compress these interactions by predicting the mean and variance of the variational distribution. The diffusion process is conducted over these latent space representations. This method significantly reduces the model parameters and memory costs for deploying diffusion models for large-scale recommender systems.
T-DiffRec uses a time-aware reweighting strategy that assigns larger weight to recent user interactions. The underlying hypothesis is that user preferences shift over time and more recent interactions can better represent users’ current preferences. These weights are defined through a simple time-aware linear schedule: $w_m = w_{\min} + \dfrac{m-1}{M-1}(w_{\max}-w_{\min})$ for an interaction sequence $\mathcal{S}={i_1, i_2, \dots, i_M}$ of M items, where $w_{\min}<w_{\max}\in(0,1]$ represent two hyperparameters for the lower an upper bound of the interaction weights.
The code and data for DiffRec are available on GitHub.
DiffuRec by Wuhan University
Li et. al8 proposed DiffuRec, a diffusion-based sequential recommender system, for modeling items’ latent aspects and users’ multi-level interests. The overall architecture for DiffuRec is shown below.
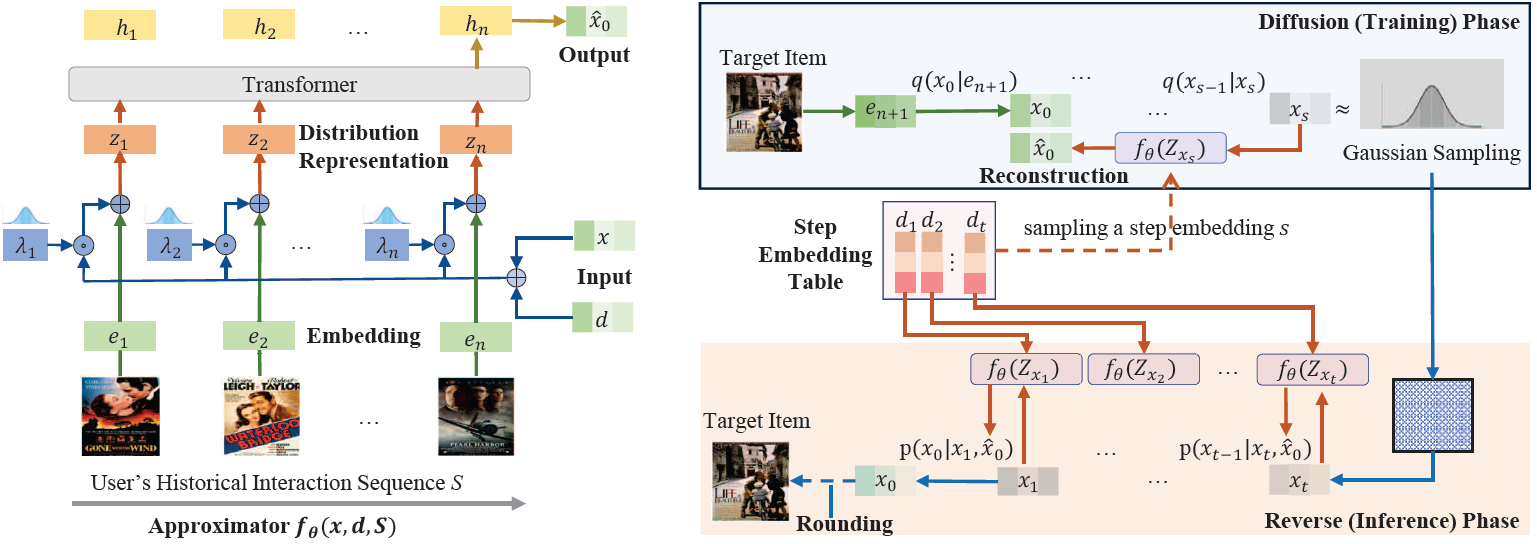
During the diffusion phase, Gaussian noise is gradually added into the target embedding using a truncated linear schedule to generate a noised item representation. The authors hypothesize that this noise helps in injecting some uncertainty into the recommendation process. A step index is sampled from a uniform distribution and the corresponding step embedding is fed into the Approximator for model training. A Transformer model is used as an Approximator (shown on the left) that iteratively reconstructs target item representation for model training. At inference time, this Approximator iteratively reverses pure Gaussian noise into target item distribution representation to predict the users’ current interests.
While the earlier work simplified the KL divergence in the objective function to mean square error, the authors of DiffuRec utilize cross-entropy loss for model optimization. Their experiments show that the DiffuRec model outperforms nine strong baseline methods.
Summary
Generative methods have shown considerable success in the recommender systems domain by modeling historical interactions to learn posterior distributions over latent factors. These factors characterize highly entangled user preferences when executing an intention. Diffusion Models present a new and powerful paradigm to effectively model this latent space. This article introduced several recent proposals that adapt diffusion models to the recommendations domain.
References
-
Wang, Jun & Yu, Lantao & Zhang, Weinan & Gong, Yu & Xu, Yinghui & Wang, Benyou & Zhang, Peng & Zhang, Dell. (2017). IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models. 10.1145/3077136.3080786. ↩︎
-
Jin, B., Lian, D., Liu, Z., Liu, Q., Ma, J., Xie, X., & Chen, E. (2020). Sampling-Decomposable Generative Adversarial Recommender. ArXiv. /abs/2011.00956 ↩︎
-
Liang, D., Krishnan, R. G., Hoffman, M. D., & Jebara, T. (2018). Variational Autoencoders for Collaborative Filtering. ArXiv. /abs/1802.05814 ↩︎
-
Xie, Z., Liu, C., Zhang, Y., Lu, H., Wang, D., & Ding, Y. (2021). Adversarial and Contrastive Variational Autoencoder for Sequential Recommendation. ArXiv. /abs/2103.10693 ↩︎
-
Luo, C. (2022). Understanding Diffusion Models: A Unified Perspective. ArXiv. /abs/2208.11970 ↩︎
-
Du, H., Yuan, H., Huang, Z., Zhao, P., & Zhou, X. (2023). Sequential Recommendation with Diffusion Models. ArXiv. /abs/2304.04541 ↩︎
-
Wang, W., Xu, Y., Feng, F., Lin, X., He, X., & Chua, T. (2023). Diffusion Recommender Model. ArXiv. /abs/2304.04971 ↩︎
-
Li, Z., Sun, A., & Li, C. (2023). DiffuRec: A Diffusion Model for Sequential Recommendation. ArXiv. /abs/2304.00686 ↩︎
Related Content





Did you find this article helpful?