Two Tower Model Architecture: Current State and Promising Extensions

Introduction
Two-tower model is widely adopted in industrial-scale retrieval and ranking workflows across a broad range of application domains, such as content recommendations, advertisement systems, and search engines. It is also the current go-to state-of-the-art solution for pre-ranking tasks. This article explores the history and current state of the Two Tower models and also highlights potential improvements proposed in some of the recently published literature. The goal here is to help understand what makes the Two Tower model an appropriate choice for a bunch of applications, and how it can be potentially extended from its current state.
Cascade Ranking System
Large-scale information retrieval and item recommendation services often contain tens of millions of candidate items or documents. A search query on Google may have matching keywords in millions of documents (web pages), and Instagram may have thousands or even millions of candidate videos for generating a recommended feed for a user. Designing such systems often has to deal with the additional challenge of strict strict latency constraints. Studies have shown that even a 100ms increase in response time leads to degraded user experience and a measurable impact on revenue 1. A single, complex ranking algorithm cannot efficiently rank such large sets of candidates. Hence, a multi-stage ranking system is commonly adopted to balance efficiency and effectiveness.
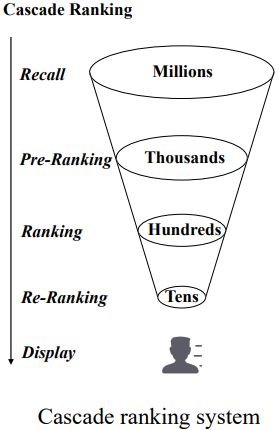
In this system, simpler and faster algorithms that focus on recall metrics are employed at earlier steps (Recall and Pre-Ranking). Whereas the large-scale deep neural networks are employed at the later steps (Ranking and Re-Ranking). Keeping latency expectations and accuracy tradeoffs in mind, an appropriate algorithm is used at each step. Each algorithm calculates some form of relevance or similarity value for every single candidate and passes the most relevant candidate set onto the next step.
In an earlier blog post 2, I introduced several interaction-focused DNN algorithms that can be used for the ranking stage. I recommend going through that article for developing a good understanding of these algorithms. This current article will mainly talk about the Two Tower model in the context of the pre-ranking stage.
Two Tower Model
The pre-ranking stage does the initial filtering of the candidates received from the preceding recall or retrieval stage. Compared to the ranking stage, the pre-ranking model has to evaluate a larger number of candidates and therefore a faster approach is preferred here. The following figure shows the development history of pre-ranking systems from an ads recommendation modeling perspective 3.
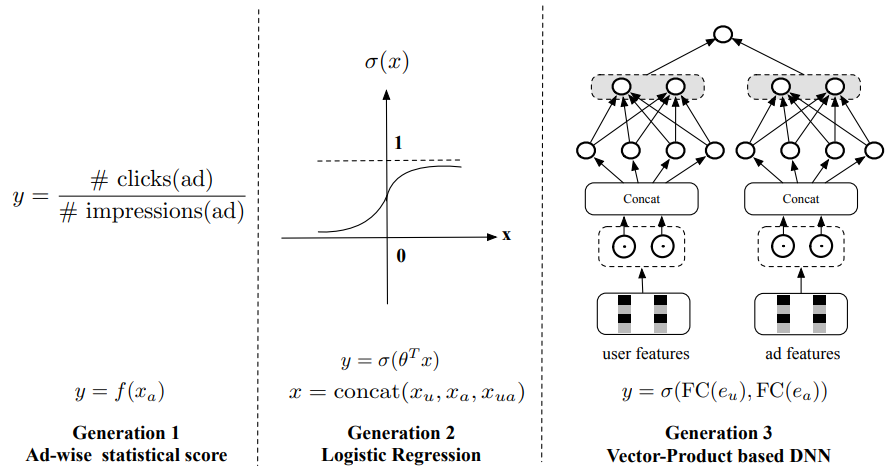
Here $x_{u}$, $x_{a}$, $x_{ua}$ are the raw user features, ad features, and cross features. The first generation calculated the pre-rank score in a non-personalized way by averaging the recent click-through rate of each ad. Logistic regression used in the second generation is also a lightweight algorithm that can be deployed in online learning and serving manner. The third generation commonly used a Two Tower model which is a vector-produced based DNN. In this method, user and ad features pass through embedding and DNN layers to generate a latent vector representation for both the user and the ad. Then an inner product of the two vectors is calculated to obtain the pre-ranking score. This Two Tower structure was originally developed in search systems as a means to map a query to the most relevant documents4.
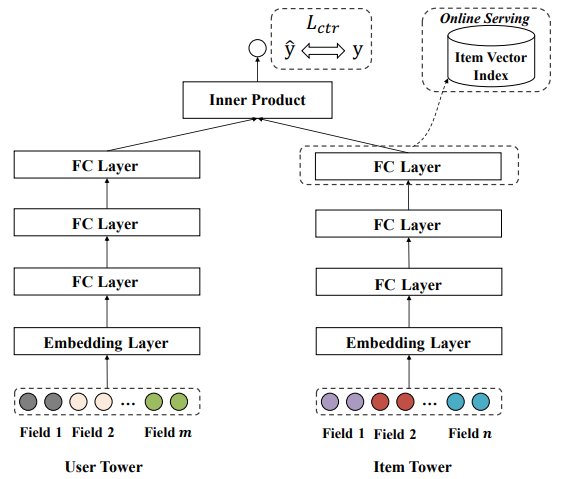
The reason why the Two Tower model rose to popularity was its accuracy as well as its inference efficiency-focused design. The two towers generate latent representations independently in parallel and interact only at the output layer (referred to as “late interaction”). Often the learned ad or item tower embeddings are also frozen after training and stored in an indexing service for a quicker operation at inference time.
Related DNN Paradigms
The information retrieval domain has several other DNN paradigms related to the Two Tower model. The following figure shows some examples in the context of neural matching applications (query to document matching)5.
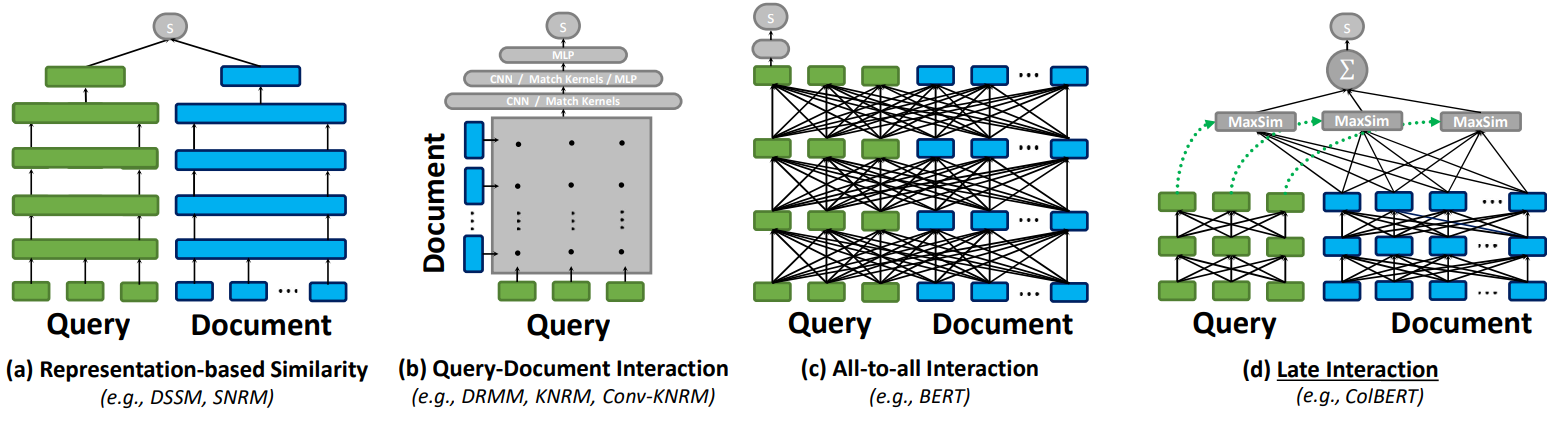
As you can see, the Two Tower model (Figure a) is a representation-based ranker architecture, which independently computes embeddings for the query and documents and estimates their similarity via interaction between them at the output layer. The other paradigms represent more interaction-focused rankers. Models like DRMM, and KNRM (Figure b) model word- and phrase-level relationships across query and document using an interaction matrix and then feed it to a neural network like CNN or MLP. Similarly, models like BERT (Figure c), also called cross-encoders, are much more powerful as they model interactions between words as well as across the query and documents at the same time. On the other hand, models like ColBERT (Contextualized later interactions over BERT) (Figure d) keep interactions within the query and document features while delaying the query-document interaction to the output layer. This allows the model to preserve the “query-document decoupling” (or “user-item decoupling”) architecture paradigm, and the document or item embeddings can be frozen after training and served through an index at the inference time as shown on the left in the figure below. Inference costs can be further reduced if the application can work with freezing both towers. For example, as shown on the right in the following figure, Alibaba creates indexes out of the learned embeddings from both towers and retrains the model offline on a daily frequency 3.
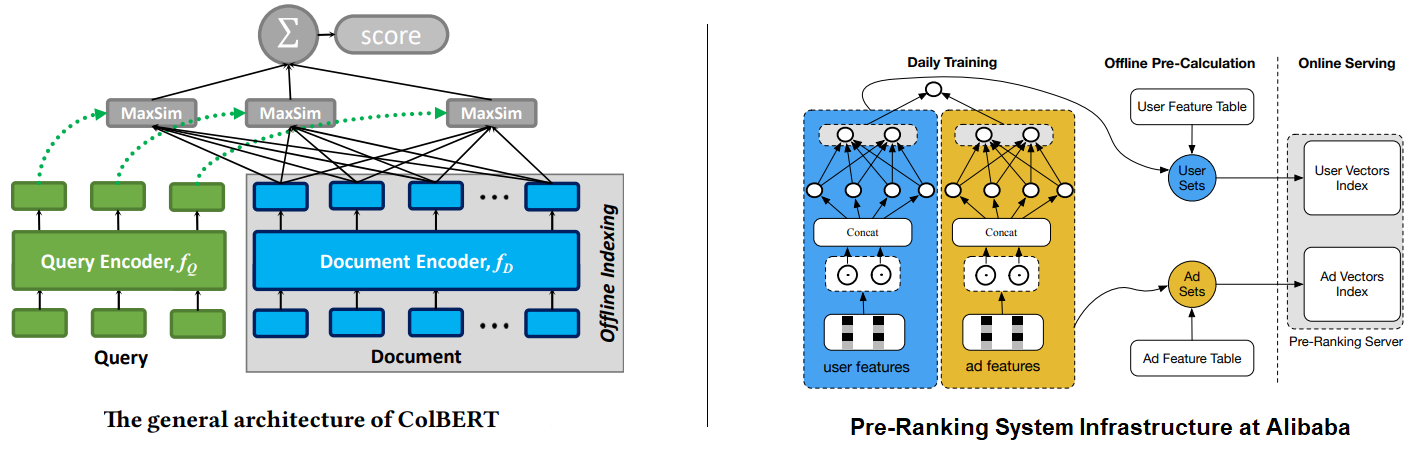
Comparing Dual Encoder Architectures
Two tower models, like DSSM, are also called the dual encoder or bi-encoder architecture as they encode the input (such as a query, an image, or a document) into an embedding using the two sub-networks ("towers" or “encoders”). The model is then optimized based on similarity metrics in the embedding space. Dual encoders have shown excellent performance in a wide range of information retrieval tasks, such as question-answering, entity linking, dense retrieval, etc. They are also easy to productionize because the embedding for new or updated documents can be dynamically added to the embedding index, without retraining the encoders6.
A Siamese encoder model is a type of dual encoder that consists of two identical sub-networks joined at their outputs. Generally, the two sub-networks also share their parameters. The Siamese architecture was originally proposed by Bromley et al.7 for signature verification application. It processes two inputs concurrently and maps them onto a single scalar output representing the distance or similarity between the inputs. On the other hand, an asymmetric dual encoder (ADE) refers to a model with two distinctly parameterized encoders. In practice, ADEs are used when a certain asymmetry is required in the dual encoders. Dong et al.6 conducted a study to explore the different ways dual encoders can be structured and compared their efficacy on the question-answering retrieval task.
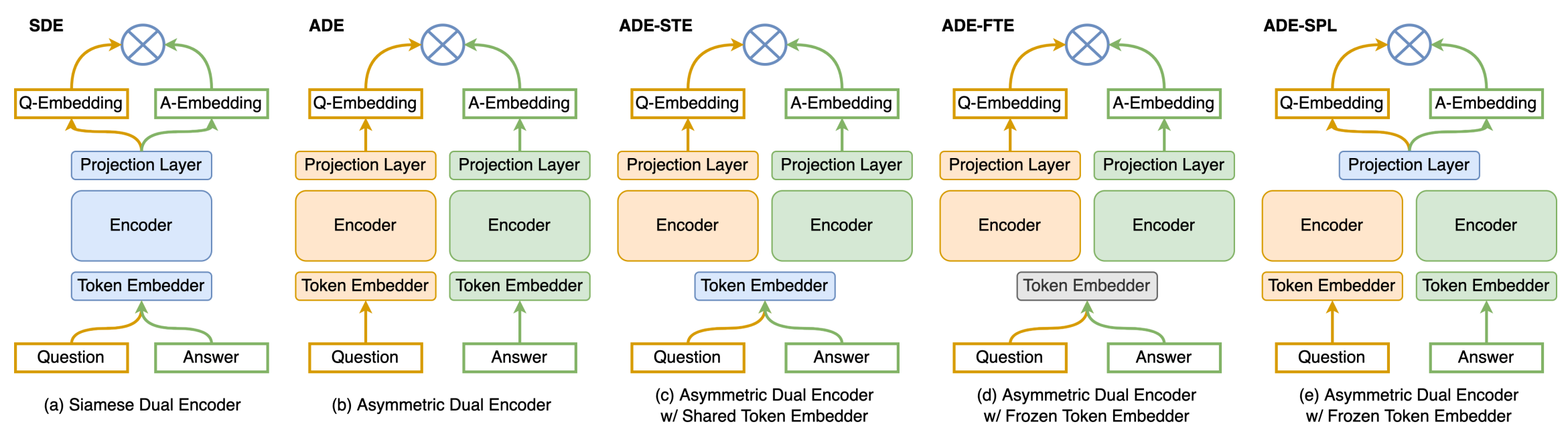
The study concluded that the Siamese Dual Encoders (SDEs) perform significantly better than Asymmetric Dual Encoders (ADEs) because ADEs tend to embed the two inputs into disjoint embedding spaces, which hurts the retrieval quality. They also found that ADE performance can be enhanced to be on par or even better than SDEs by sharing a projection layer between the two encoders (ADE-SPL). However, sharing the token embedders between the two towers (ADE-STE) or freezing the token embedders during training (ADE-FTE) only brings marginal improvements.
Enhancing Two Tower Model
In this section, we look at some of the proposals from different researchers for extending the Two Tower model. One common problem with the Two Tower model that this research works focus on is the lack of information interaction between the two towers. As we saw earlier, the Two Tower model trains the latent embeddings in both towers independently and without using any enriching information from the other tower. This limitation hinders the model’s performance.
Dual Augmented Two-Tower Model (DAT)
To model feature interactions between two towers, Yu et al.8 proposed augmenting the embedding input of each tower with a vector ($a_{u}$ and $a_{v}$ in the figure below) that captures historical positive interaction information from the other tower. $a_{u}$ and $a_{v}$ vectors get updated during the training process and are used to model the information interaction between the two towers by regarding them as the input feature of the two towers. This paper also proposes a new category alignment loss to handle the imbalance among different categories of items by transferring the knowledge learned from the category with a large amount of data to other categories. Later research showed that the gains achieved by the DAT model are still limited.
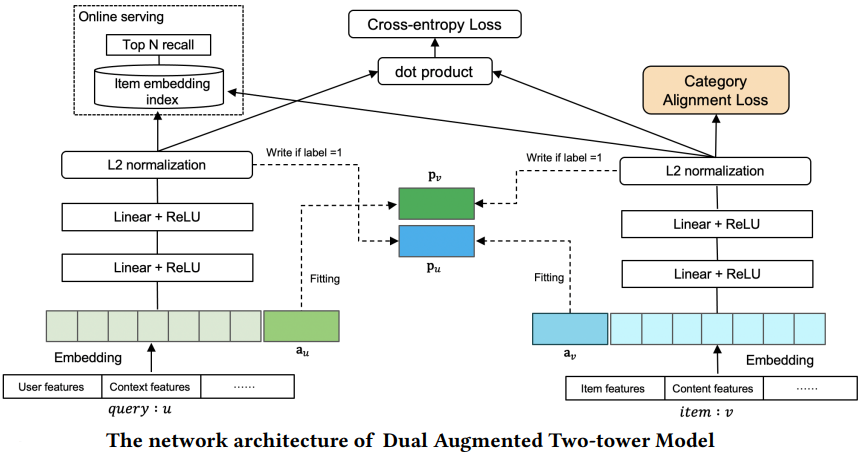
Interaction Enhanced Two Tower Model (IntTower)
The authors of this research design a two-tower model that emphasizes both information interactions and inference efficiency 9. Their proposed model consists of three new blocks, as mentioned below.
Light-SE Block
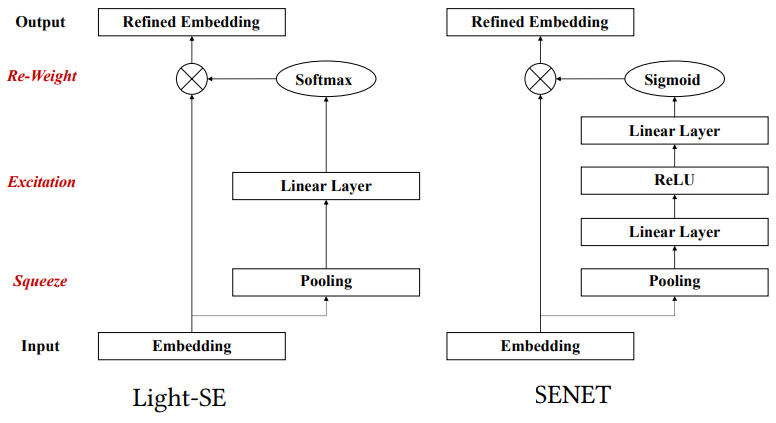
This module is used to identify the importance of different features and obtain refined feature representations in each tower. The design of this module is based on the SENET model proposed in the “Squeeze-and-Excitation Networks” paper 10. SENET is used in the computer vision domain to explicitly model the interdependencies between the image channels through feature recalibration, i.e. selectively emphasizing informative features and suppressing less useful ones. The basic structure of the SE building block is shown in the next figure.
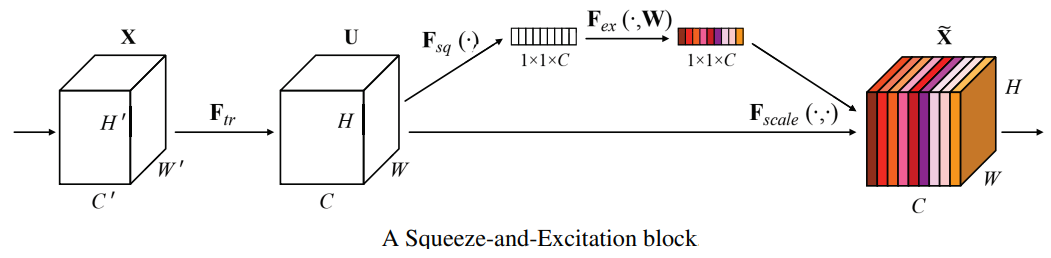
First, a squeeze operation aggregates the feature maps across spatial dimensions to produce a channel descriptor. An excitation operation then excites informative features by a self-gating mechanism based on channel dependence (similar to calculating attention weights). The final output of the block is obtained through a scaling step by rescaling the transformation output with the learned activations. The authors of the IntTower paper adopt a more lightweight approach with a single FC layer to obtain the feature importance. The following figure shows the SENET and Light-SE blocks side-by-side.
FE-Block
The purposed FE (Fine-grained and Early Feature Interaction) Block is inspired by the later interaction style of ColBERT. It performs fine-grained early feature interaction between multi-layer user representations and the last layer of item representation.
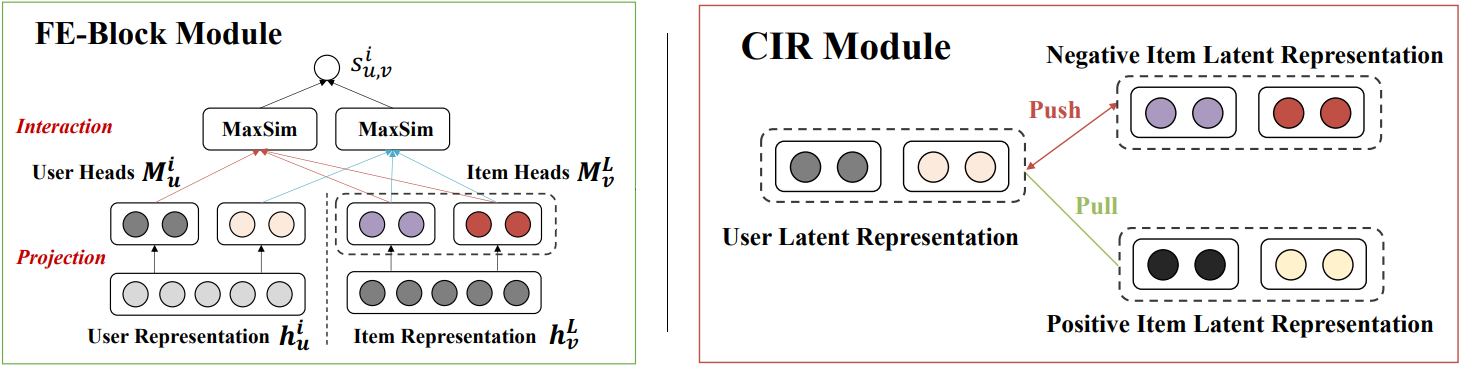
CIR Module
A Contrastive Interaction Regularization (CIR) module was also purposed to shorten the distance between a user and positive items using InfoNCE loss function 11. During training, this loss value is combined with the logloss between the model prediction scores and the true labels.
IntTower Model Architecture
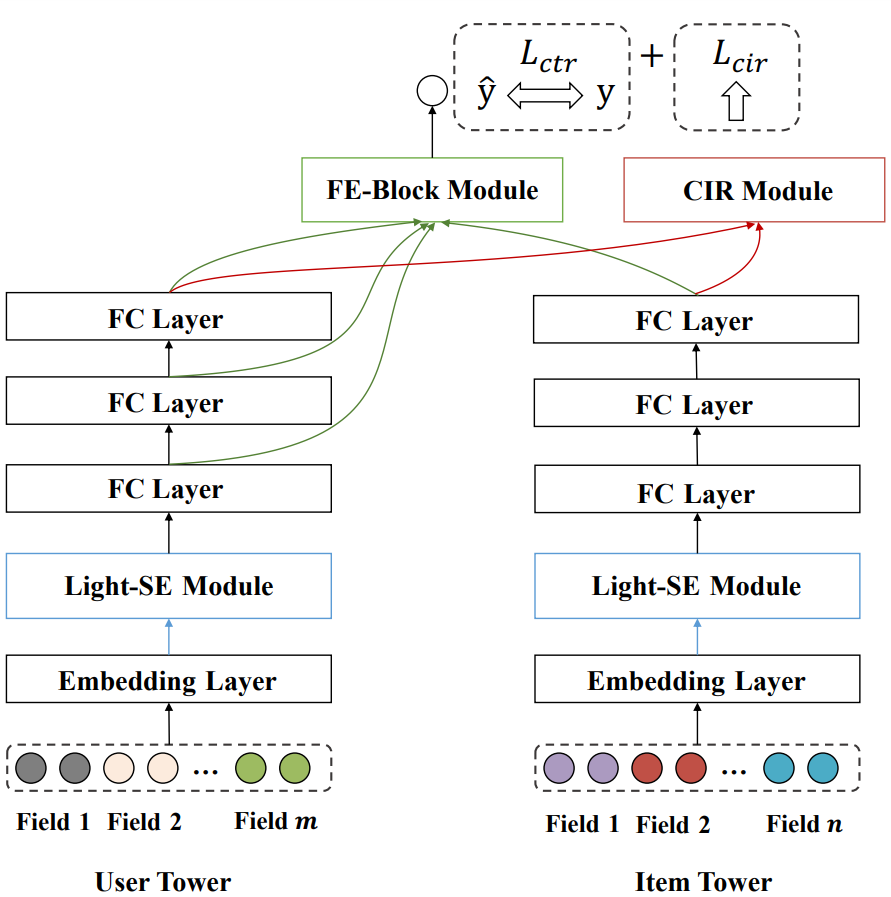
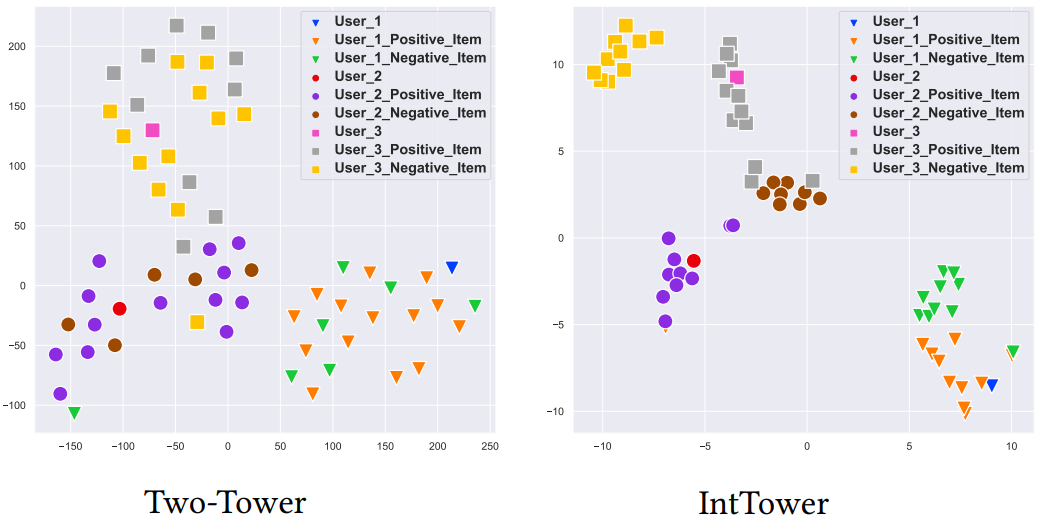
As shown in the figure above, the IntTower model architecture combines the three blocks described earlier. Through experimentation, the authors show that the IntTower model outperforms other pre-ranking algorithms (Logistic Regression, Two-Tower, DAT, COLD) and even performs comparably to some ranking algorithms (Wide&Deep, DeepFM, DCN, AutoInt). Compared with the Two Tower model, the increased parameters count and training time of IntTower are negligible and the serving latency is also acceptable. The authors also investigate the user and item representations generated by Two Tower and IntTower models by projecting them into 2-dimensions using t-SNE. As shown in the next figure, the IntTower representations have the user and positive items in the same cluster while negative items are far away from the user.
Other Alternatives to Two Tower Model
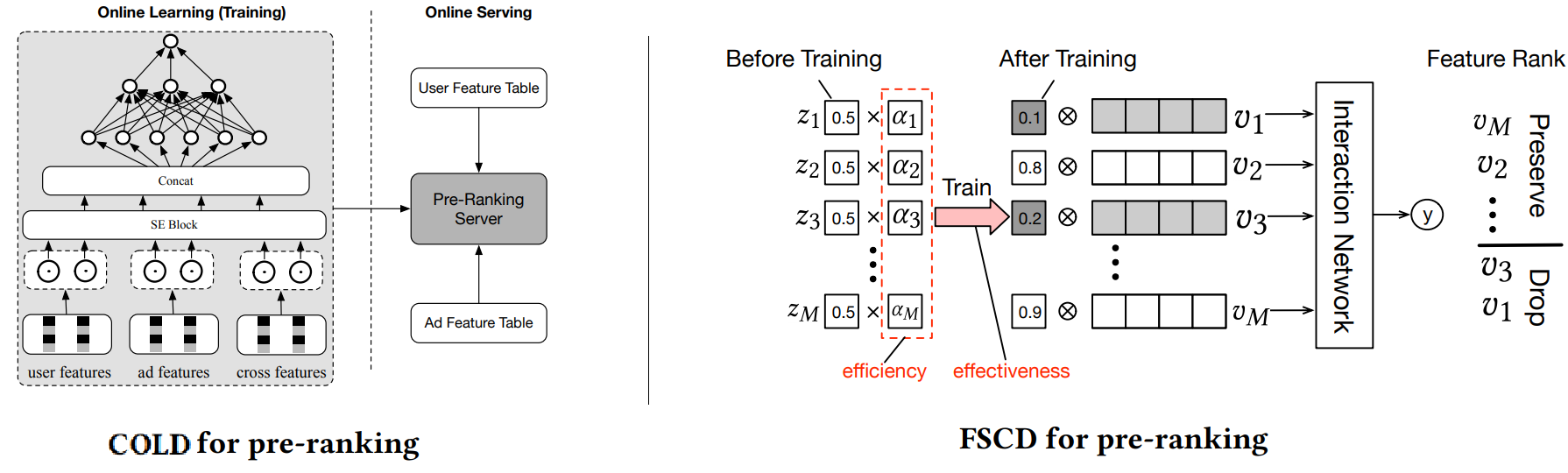
Apart from Two Tower models, there has been some research work with single-tower structures to fully model feature interactions and further improve prediction accuracy. However, due to the lack of a “user-item decoupling architecture” paradigm, these models have to employ several optimization tricks to alleviate efficiency degradations. For example, the COLD (Computing power cost-aware Online and Lightweight Deep pre-ranking system) model 3 performs offline feature selection experiments to find out a set of important features for the ranking algorithm that are optimal concerning metrics such as QPS (queries per second) and RT (return time). Similarly, FSCD (Feature Selection method based on feature Complexity and variational Dropout) model 12 uses learnable dropout parameters to perform feature-wise regularization such that the pre-ranking model is effectively inherited from that of the ranking model.
Conclusion
This article introduced the historical evolution of pre-ranking approaches in the context of cascade ranking-based systems. We learned how the balance of efficiency and effectiveness makes Two Tower models an excellent choice for several information retrieval use cases. We also explored several recent research proposals that combine ideas from related domains to enhance the Two Tower model. We wrapped up the article with a look at some of the available alternatives to the Two Tower model architecture.
References
-
Kohavi, R., Deng, A., Frasca, B., Walker, T., Xu, Y., & Pohlmann, N. (2013). Online controlled experiments at large scale. Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. ↩︎
-
Sumit Kumar. Recommender Systems for Modeling Feature Interactions under Sparse Settings. https://blog.reachsumit.com/posts/2022/11/sparse-recsys/ ↩︎
-
Wang, Zhe & Zhao, Liqin & Jiang, Biye & Zhou, Guorui & Zhu, Xiaoqiang & Gai, Kun. (2020). COLD: Towards the Next Generation of Pre-Ranking System. ↩︎ ↩︎ ↩︎
-
Huang, P., He, X., Gao, J., Deng, L., Acero, A., & Heck, L. (2013). Learning deep structured semantic models for web search using clickthrough data. Proceedings of the 22nd ACM international conference on Information & Knowledge Management. ↩︎
-
Khattab, O., & Zaharia, M.A. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. ↩︎
-
Dong, Z., Ni, J., Bikel, D. M., Alfonseca, E., Wang, Y., Qu, C., & Zitouni, I. (2022). Exploring Dual Encoder Architectures for Question Answering. ArXiv. /abs/2204.07120 ↩︎ ↩︎
-
Bromley, J., Bentz, J.W., Bottou, L., Guyon, I.M., LeCun, Y., Moore, C., Säckinger, E., & Shah, R. (1993). Signature Verification Using A “Siamese” Time Delay Neural Network. Int. J. Pattern Recognit. Artif. Intell., 7, 669-688. ↩︎
-
Yu, Y., Wang, W., Feng, Z., Xue, D., Meituan, & Beijing (2021). A Dual Augmented Two-tower Model for Online Large-scale Recommendation. ↩︎
-
Li, X., Chen, B., Guo, H., Li, J., Zhu, C., Long, X., Li, S., Wang, Y., Guo, W., Mao, L., Liu, J., Dong, Z., & Tang, R. (2022). IntTower: The Next Generation of Two-Tower Model for Pre-Ranking System. Proceedings of the 31st ACM International Conference on Information & Knowledge Management. ↩︎
-
Hu, J., Shen, L., Albanie, S., Sun, G., & Wu, E. (2017). Squeeze-and-Excitation Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42, 2011-2023. ↩︎
-
https://lilianweng.github.io/posts/2021-05-31-contrastive/#infonce ↩︎
-
Ma, X., Wang, P., Zhao, H., Liu, S., Zhao, C., Lin, W., Lee, K., Xu, J., & Zheng, B. (2021). Towards a Better Tradeoff between Effectiveness and Efficiency in Pre-Ranking: A Learnable Feature Selection based Approach. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. ↩︎
Related Content





Did you find this article helpful?