Twitter's For You Recommendation Algorithm

Twitter Releases “The Algorithm”
Last week, Twitter released a lot of details about the recommendation algorithm that powers their For You feed. The release included an announcement, two new GitHub repositories (main repo, ml repo), and an accompanying post on the engineering blog. Their release also includes some model configs, hyperparameters, input feature descriptions, feature weights, combined score calculation formula, etc. that are immensely valuable for ML practitioners. This article gives an overview of the end-to-end machine learning components made public by Twitter.
Today marks a new era of transparency for Twitter. 🧵
— Engineering (@XEng) March 31, 2023
We’re sharing much of the source code that powers our platform with the world. Visit our blog to learn more about this initiative: https://t.co/hTHVpuMDz8
The Algorithm
At a broad level, we can think of Twitter’s For You timeline generation as the sequence of following steps that are also common to large-scale recommendation systems.
graph LR;
A(Data Sourcing) --> B(Candidate Generation)
B --> C(Ranking)
C --> D(Heuristics & Filtering)
D --> E(Mixing)
We will look at each of these components one by one. Note that while Twitter has shared a lot of information on the code and algorithms for most of these steps, they haven’t still shared details about components such as input data processing, model configs, serving infrastructure, source code for modules like Candidate Generation, Trust & Safety, Ads, etc.
Data Sourcing
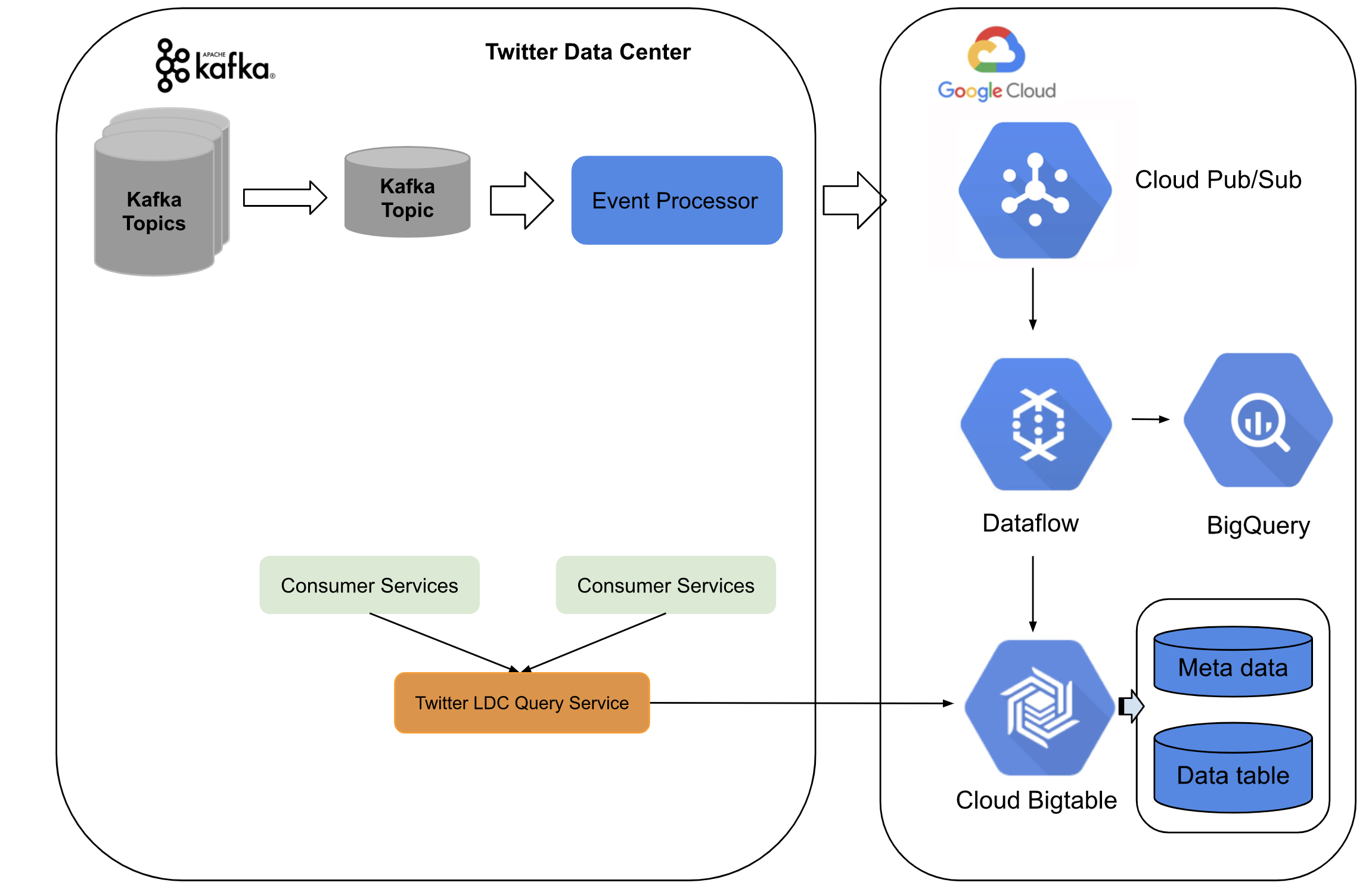
Twitter has previously shared details about its data infrastructure in another blog. Twitter processes close to 500 million daily tweets, and 400 billion real-time events. The event data is sourced from various platforms, storage systems, and distributed databases. The user engagement data is collected from various real-time streams, server, and client-side logs, etc. They also utilize various proprietary tools such as Scalding for batch processing, Heron for streaming, and TSAR (TimeSeries AggregatoR) for processing temporal signals. In their recent redesign (see figure below) proposal1 they built an on-premise event processor along with deduplication and BigTable storage on the Google Cloud Platform (GCP). Note that Twitter exactly specified any data schema or preprocessing applied to the data for the recommender system.
Candidate Generation
The job of the candidate generation module is to select 1500 most relevant tweets from various sources. The first half of these candidates are from the people that you follow (in-network tweets), while the other half is from the people who you do not follow (out-of-network tweets).
In-Network Tweets
Most of the in-network tweets are sourced from Twitter’s RealGraph framework (originally deployed in 20122). RealGraph framework uses a directed, weighted graph to model users (tweeps) as nodes. An edge from source to target node indicates that the source user follows the target user or the target user is in the source user’s contact book, or the source user recently interacted with the target user. Each type of edge has its own set of features represented by weights, such as days since edge creation, days since last interaction, number of common friends, explicit and implicit engagement statistics, etc. Similarly, nodes have features such as the number of retweets in the last week, number of followers, demographics, PageRank on the follow graph, etc.
Note that Twitter has also shared the implementation details of its PageRank algorithm called TweepCred. A logistic regression model is trained on all of these features to predict interaction in a future time window. Note that the graph itself is updated daily in batch mode. In their announcement, Twitter also mentioned that the logistic regression model was trained several years ago and is in the process of being redesigned.
Out-of-Network Tweets
Social Graph
For some of the out-of-network tweets, the retrieval process uses a graph processing engine called GraphJet3. GraphJet maintains a dynamic (real-time), undirected, bipartite graph between users and tweets in memory on a single server (no partitioning!) through clever edge encoding and dynamic memory allocation schemes. The nodes in the graph represent the users and the tweets, while the edges represent the actions (favorite, tweet, retweet, reply, click, etc.) within a rolling temporal window. To ensure the efficient growth of the graph structure, GraphJet maintains a list of temporally-ordered index segments such that only the latest segment can be written into (see the figure below).
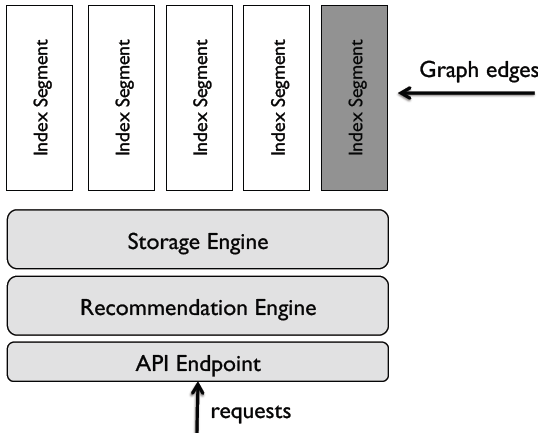
A SALSA (Stochastic Approach for Link-Structure Analysis) random walk over this graph is done to get the tweets that a might be interested in (for example, tweets that the user’s connection recently engaged with). A seed set of user nodes called the circle of trust (personalized PageRank), is used for cold users or users with no recent engagement history. Similar to RealGraph, a logistic regression model is used to predict the probability of engagement. GraphJet is implemented in Java, and powers about 15% of tweets in the For You feed.
Embedding-based Semantic Spaces
The majority of out-of-network tweets are retrieved through embedding-based methods described below.
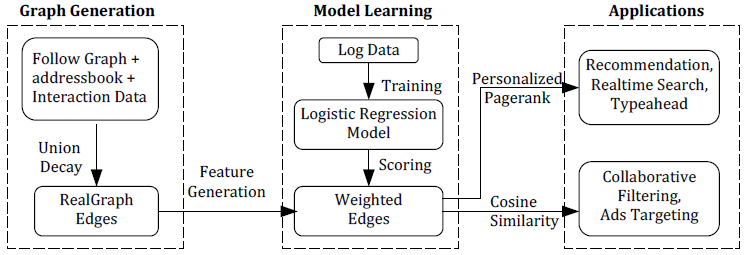
SimClusters
Twitter has used its SimClusters4 embedding space to identify 145,000 communities that are either based on a common theme (such as “machine learning”, or “K-pop”), or social relationships (such as users who went to the same school). Using SimClusters, Twitter has a representation layer where both users and content are mapped in the same space. First, using a user-user graph (based on follow relationship) k number of possible overlapping communities are discovered. While this can be technically done using a sparse non-negative matrix factorization (NMF) technique, Twitter devised a custom matrix factorization technique (called Sparse Binary Factorization or SBF) that can also scale for large graphs. Next, an item representation can be calculated using a simple aggregation, such as an exponentially time-decayed average, over the representations of all the users who engaged with that item (see the figure below).
Twitter retrieves out-of-network tweets from these clusters by simply identifying the tweets that have the highest dot-product value with the interest representations, along with an item-based collaborative filtering technique. A high similarity score means that the corresponding tweet will be associated more with that community.
TwHIN
Twitter uses its knowledge graph embeddings, called TwHIN (Twitter’s Heterogeneous Information Network) embeddings5, for candidate generation and also as features for ranking and prediction tasks. These are pretrained generalizable embeddings applicable to users, tweets, advertisements, etc. These embeddings are learned from disparate network data (heterogeneous relationships) to capture a diverse set of signals, such as social signals, content or advertisement engagement signals, etc while simultaneously addressing data sparsity. For the learning process, Twitter uses positive and negative triplets (source entity, edge type, target entity) with contrastive loss and the training objective to find entity representations that effectively predict which other entities are directly linked by a certain relation. Twitter has released the source code for training TwHIN embeddings here.
At this end of candidate retrieval, we have 1500 tweets ready to be ranked for the user’s For You feed.
Ranking
Light Ranking
A simple and efficient logistic-regression-based light ranker is used for ranking both in-network and out-of-network tweets. Twitter’s core retrieval system (called EarlyBird6) builds and maintains inverted indexes required to perform the real-time search and retrieval of tweets. Instead of relying on the full social graph, In earlier iterations, EarlyBird utilized Bloom Filter to compress relevant social graph information for each user. Apart from being space-efficient, this implementation also enabled constant-time set-membership operations. The logistic regression model uses various static and real-time features listed here. Twitter notes that “the current model was last trained several years ago, and uses some very strange features.” and they are working on training a new model.
The source code for this light ranking is released here, along with the details about input features(in-network, out-of-network), feature weights, and time decay used by the model. It is mentioned that EarlyBird ranks a lesser number of tweets than heavy ranker, but the exact order and counts corresponding to light ranker execution are not specified.
Heavy Ranking
Twitter uses MaskNet7 to perform computationally costlier ranking for the 1500 retrieved tweets. Similar to a lot of other rankers in the Click-Through Rate (CTR) estimation domain, MaskNet emphasizes effectively capturing the high-order feature interactions in an explicit manner similar to the earlier Deep & Cross Network (DCN). MaskNet introduces a basic building block called a MaskBlock that contains three components: an “instance-guided mask”, a feed-forward hidden layer, and a layer normalization module. The instance-guided mask performs element-wise product on feature embeddings and feed-forward layers to highlight the global context information. Twitter uses the parallel MaskNet variant (~48M parameters) where multiple MaskBlocks on feature embeddings are applied in parallel (similar to MMoE design).
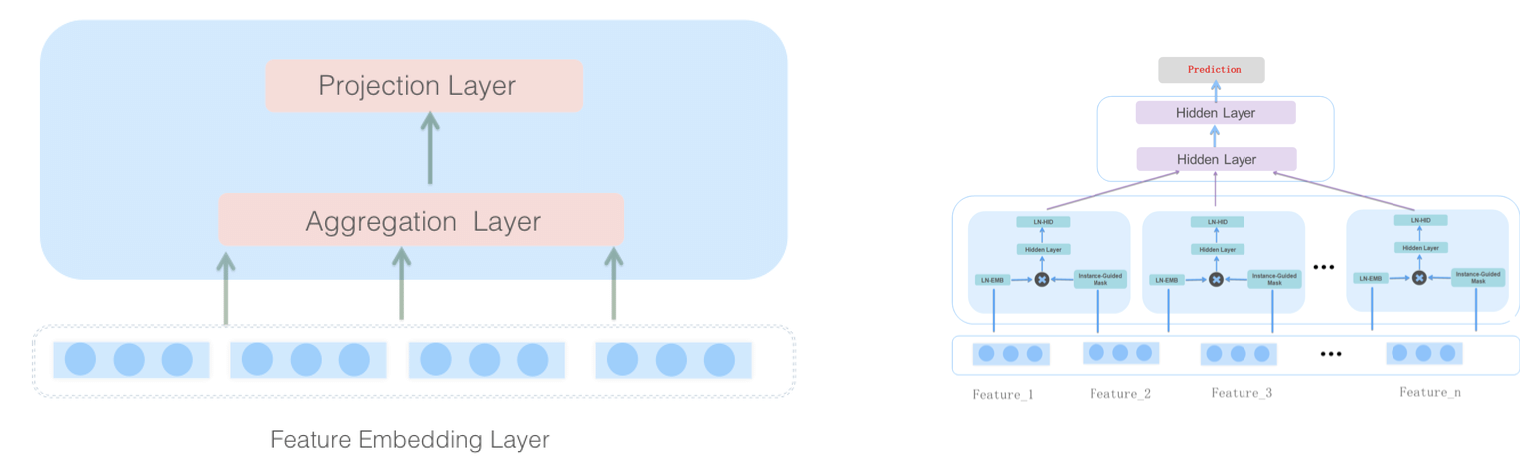
Twitter has released its source code for MaskNet implementation here, along with model hyperparameters, and the details of aggregate, non-aggregate, and embedding input features used by the model.
MaskNet outputs 10 different probabilities, and the final score calculation is calculated by weighing the output probabilities as shown below. These weights are hard coded and were likely fixed after a lot of A/B testing.
$$ Combined Score = P(favorite) \times 0.5 + max(P(good click and reply or like), P(good click and stay for at least 2 minutes)) \times 11 + P(negative reaction) \times -74 + P(author profile clicked and profile engaged) \times 12 + P(reply) \times 27 + P(reply and author engaged) \times 75 + P(report) \times -369 + P(retweet) * 1 + P(watch half the video) \times 0.005 $$
Heuristics & Filtering
Twitter applies a lot of heuristics and filters on the ranked list of tweets to create a balanced and diverse For You feed. The following list contains some prominent examples.
- The Visibility Filtering module removes various spam along with the tweet from accounts you have blocked or muted.
- Remove out-of-network competitor URL tweets. (code reference)
- Infuse diversity by applying a penalty to too many consecutive tweets from the same author. (code reference)
- Lower the relevance score for tweets with the author or engaged audience for whom the user had given negative feedback in the past. (code reference)
- Remove out-of-network tweets that do not have a second-degree connection. (code reference)
- Boost Twitter Blue Verified authors by a factor of 4.0 for in-network tweets and 2.0 for out-of-network tweets. (code reference)
Mixing
As the last step, the Home Mixer system blends together non-tweet content like ads, promotions, follow recommendations, etc. to the list of ranked and filtered tweets. The output of this step is the final feed that gets sent and displayed on the end-user device.
Summary
Twitter has open-sourced a majority of its recommendation algorithm. It offers an exciting opportunity for researchers, industry practitioners, and RecSys enthusiasts to take a close look at how Twitter computes the recommended feed for the For You page. This article described Twitter’s end-to-end recommender system along with relevant literature and code references.
References
-
Processing billions of events in real time at Twitter. Lu Zhang, Chukwudiuto Malife, 22 October 2021. https://blog.twitter.com/engineering/en_us/topics/infrastructure/2021/processing-billions-of-events-in-real-time-at-twitter- ↩︎
-
Kamath, K.Y., Sharma, A., Wang, D., & Yin, Z. (2014). RealGraph: User Interaction Prediction at Twitter. ↩︎
-
Sharma, A., Jiang, J., Bommannavar, P., Larson, B., & Lin, J.J. (2016). GraphJet: Real-Time Content Recommendations at Twitter. Proc. VLDB Endow., 9, 1281-1292. ↩︎
-
Satuluri, V., Wu, Y., Zheng, X., Qian, Y., Wichers, B., Dai, Q., Tang, G.M., Jiang, J., & Lin, J.J. (2020). SimClusters: Community-Based Representations for Heterogeneous Recommendations at Twitter. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ↩︎
-
El-Kishky, A., Markovich, T., Park, S., Verma, C.K., Kim, B., Eskander, R., Malkov, Y., Portman, F., Samaniego, S., Xiao, Y., & Haghighi, A. (2022). TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ↩︎
-
Busch, M., Gade, K., Larson, B., Lok, P., Luckenbill, S.B., & Lin, J.J. (2012). Earlybird: Real-Time Search at Twitter. 2012 IEEE 28th International Conference on Data Engineering, 1360-1369. ↩︎
-
Wang, Z., She, Q., & Zhang, J. (2021). MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask. ArXiv, abs/2102.07619. ↩︎
Related Content





Did you find this article helpful?