Zero and Few Shot Text Retrieval and Ranking Using Large Language Models

Introduction
Text retrieval and ranking simply refers to the task of finding a ranked list of the most relevant documents or passages out of a large text collection given a user query. Many Information Retrieval (IR) applications such as search ranking, open-domain question answering, fact verification, etc. use text retrievers to find the text that fulfills users’ information needs. This article gives a brief overview of a standard text ranking workflow and then introduces several recently proposed ideas to utilize large language models to enhance the text ranking task.
Syntactic vs Semantic Approaches
Some of the most common methods used in these applications are based on keyword matching, sophisticated dense representations, or a hybrid of the two. BM25 is one simple term-matching-based scoring function that was proposed decades ago1, but is still immensely popular in the IR domain. BM25 only uses the terms common to both the query and the document and isn’t able to recognize synonyms and distinguish between ambiguous words2. Still, a lot of studies in the field have proven BM25 to be a really strong baseline3.
Neural information retrieval, on the other hand, captures and compares the semantics of queries and documents. Dense representation-based neural retrieval models usually take the form of either a bi-encoder network (aka “dual encoder”4, “two tower network”, “Siamese network”, “DSSM”) or a cross-encoder network.
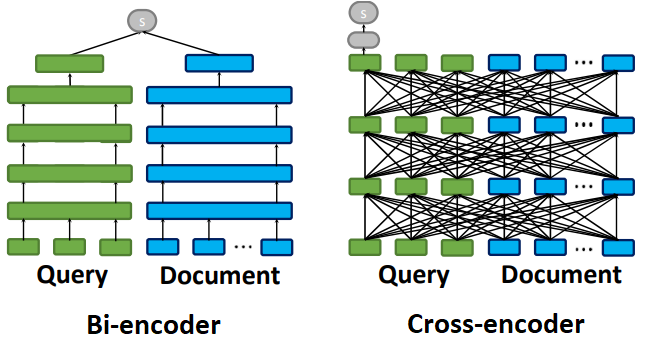
A bi-encoder network independently learns latent representations for query and document inputs and interacts them only at the final layer to calculate a similarity function, such as dot-product, cosine, MaxSim5, or Euclidian distance, on them. After offline training, the document encoder is often frozen and an indexing solution like FAISS is used to fetch document embeddings in real-time during inference. Their efficiency has made bi-encoder a really popular choice for production environments, even though the late interaction makes the model less effective. To read more about the Two-tower models’ usage in the recommender systems domain and some potential architectural extensions, please refer to this article.
A cross-encoder network takes a query and a document vector as the input and calculates the relevance scores as the maximum inner product over it. Cross-Encoders achieve higher performance than bi-encoders due to rich interactions, however, they do not scale well for large datasets6. To evaluate these dense retrieval models, metrics like accuracy, mean rank, and mean reciprocal rank (MRR) are used if the relevance score is binary, otherwise, metrics like discounted cumulative gain (DCG) and normalized DCG (nDCG) are used if a graded relevance score is used.
Cascade Ranking Pipeline
While designing end-to-end retrieval systems, we often have to balance the tradeoff between effectiveness and efficiency. As mentioned earlier, while a cross-encoder can be highly effective, its time complexity can be prohibitive for most real-time production use cases that work with large-scale document collections. A bi-encoder model can be much more efficient but doesn’t usually have the same level of accuracy as the cross-encoders.
To address this tradeoff, a cascading ranking pipeline is adopted where increasingly complex ranking functions progressively prune and refine the set of candidate documents to minimize retrieval latency and maximize result set quality7. In a semantic search pipeline, a relatively simpler algorithm like Elasticsearch, BM25, bi-encoder, or a combination may be used to retrieve the top-n (e.g. 100, 1000) candidate documents followed by a more complex algorithm like cross-encoder to re-rank these candidates. Often modern IR systems use multi-stage re-ranking, for example, by using a bi-encoder followed by a cheap cross-encoder, followed by a more expensive cross-encoder model for the final re-ranking of the top candidates8.
As an example, open-domain question-answering (ODQA) workflow is usually implemented as a two-stage pipeline: 1) given a question, a context retriever selects relevant passages and 2) a question-answering model, also known as a reader, answers the given question based on the retrieved passages9. This decoupling also allows for independent advancements of the two models.
Zero and Few Shot Settings
A significant challenge in developing neural retrievers is the lack of domain-specific training data. Low-resource target domains lack labeled training data. Manually constructing high-quality datasets is often costly and takes a lot of time. It could be especially difficult for retrieval applications as they require queries from real users. There are a few general-purpose datasets like MS MARCO and Natural Questions, but they do not always generalize well for out-of-domain uses and are often not available under a commercial license. Additionally, the original paper that introduced the BEIR IR benchmark showed that the performance of dense retrievers severely degrades under a domain shift (i.e. the shift in data distribution), often performing worse than traditional models such as BM25. This paper also showed that dense retrievers require a large amount of training data to work well10.
Hence zero-shot and few-shot adaptions of effective retrieval and ranking models do not necessarily produce generalizations that are fully compatible with the target domain, leading to severe degradation when the source and target domains differ drastically9 11. To address this, a recent line of research work has started using generative large language models (LLMs) to do zero-shot or few-shot domain adaptions of retrieval and ranking models. One reason for the popularity of these LLMs has been their capability to produce better performance from smaller quantities of labeled data12. A lot of the research work focuses on prompting LLMs with instructions for the task and a few examples in natural language to generate synthetic examples to finetune task-specific models.
In the next section, we will take a look at some of the most recent and prominent research proposals on using LLMs to help retrievers and rankers with target domain adaption.
Using LLMs for Zero or Few Shot Domain Adaption
InPars
In Inquisitive Parrots for Search (InPars), Bonifacio et al.13 used LLMs to generate synthetic data for IR tasks in a few-shot manner under minimal supervision. This data is then used to finetune a neural reranker model that is used to rerank search results in a pipeline comprised of a BM25 retriever followed by a neural monoT5 reranker. For the reranker, they tried a monoT5 model with 220M and also one with 3B parameters.
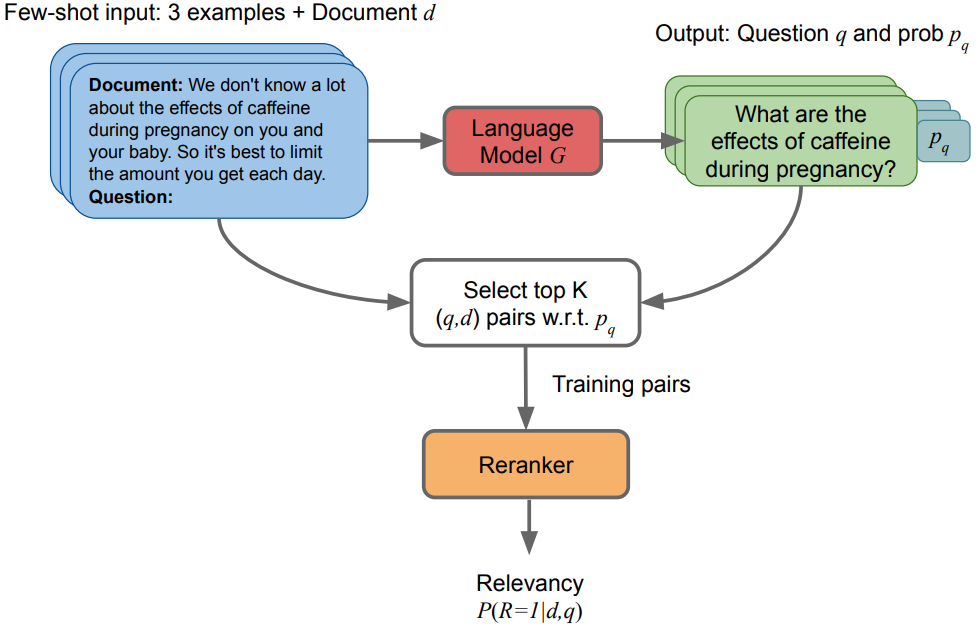
The training set consists of query, positive, and negative document triplets. Given a collection of documents, 100,000 documents are randomly sampled. Documents with less than 300 characters are discarded and a new document is sampled instead. GPT-3 Curie model is used as the LLM that generates one question corresponding to each of the sampled documents based on greedy decoding (temperature = 0).
They experimented with two prompting strategies:
- Vanilla prompting, which uses 3 randomly chosen pairs of the document and relevant question from the MS MARCO dataset as shown on the left in the following diagram (
{document_text}is replaced with the sampled document and the LLM generates a question one token at a time) - Guided by Bad Questions (GBQ), that uses a strategy similar to Vanilla but the corresponding question from MS MARCO is marked as a “bad” question while a manually created example is marked a “good” question. This was done to encourage the model to produce more contextual-aware questions than the one from MS MARCO. Only the good questions are used to create the question-document positive pair.
Negative examples were sampled from the top candidates returned by the BM25 method that weren’t relevant documents. Only top-k generated examples (sorted by log probability output of the LLM) were used to finetune the reranker model.

The Vanilla prompting strategy worked better for two out of the five tested datasets while GBQ performed better for the other three. On the target domain, the retrieval model finetuned solely on the synthetic examples outperformed BM25 and self-supervised dense method baselines. While models finetuned on both supervised and synthetic data achieved better results than models finetuned only on the supervised data. The code, model, and data for InPars are available on GitHub.
Promptagator 🐊
In Prompt-base Query Generation for Retriever (Promptagator 🐊), Dai et al.14 argued that different retrieval tasks have very different search intents (like retrieving entities, finding evidence, etc.). So they proposed a few-shot setting for dense retrievers where each task comes with a short description and a few annotated examples to clearly illustrate the search intents. Their proposed method “Promptagator” relies solely on a few (2 to 8) in-domain relevant query-document examples from the target tasks without using any query-document pairs from other tasks or datasets.
The authors used the following instruction prompt:
$$ (e_{doc}(d_{1}), e_{query}(q1), …, e_{doc}(d_{k}), e_{query}(qk), e_{doc}(d)) $$
where $e_{doc}(d)$ and $e_{query}(q)$ are one of the k-pairs of the task-specific document and query descriptions respectively, and $d$ is a new document. They ran the prompt on all documents from the corpus and created a large set of synthetic examples using a FLAN-137B LLM. During prompt engineering, they used 2 to 8 examples depending on the input length limit of FLAN and generated 8 questions per document using sampling decoding (temperature=0.7).
The quality of generated queries was further improved by ensuring “round-trip consistency”, i.e. the query should retrieve its source passage. To do this consistency filtering, they first trained an initial retriever using only the synthetic query and document pairs. Then the kept query only if the corresponding document occurs among top-K (the used K=1) passages returned in the prediction by the same retriever. This seemingly counter-intuitive approach worked well in their experiments.
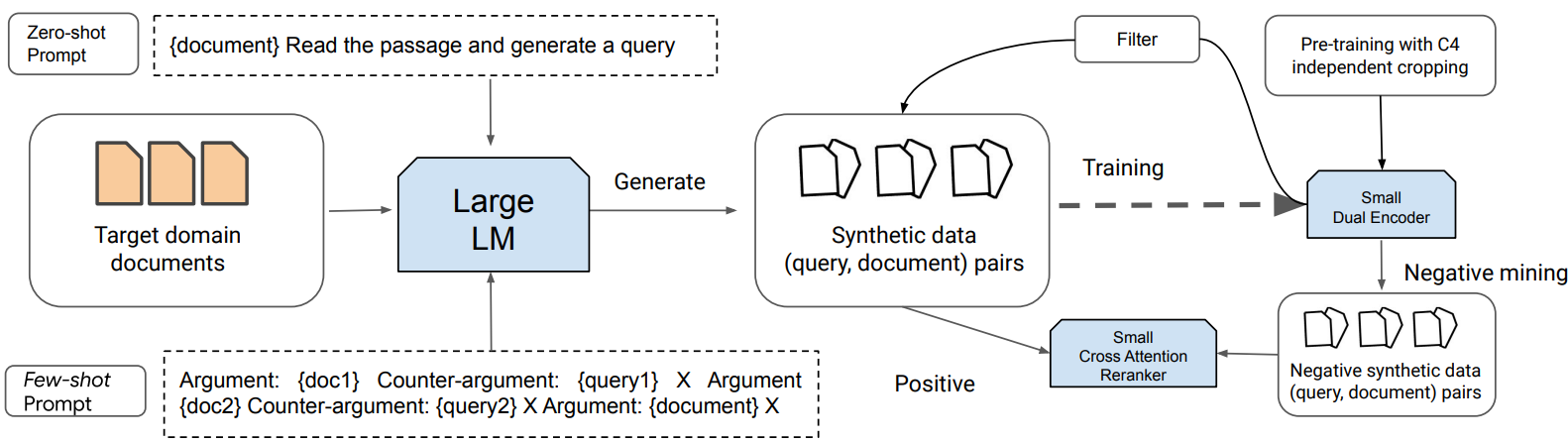
Finally, they trained a retriever (a dual encoder) followed by a cross-attention reranker on the filtered data. The dual encoder was a GTR initialized from a T5-110M network that was pretrained on the C4 dataset using independent cropping (using two random crops from the same document as positive pairs and in-batch negatives) with cross-entropy loss. This dual encoder was then finetuned using synthetic data. After this training is done, the same model is used to perform the consistency filtering mentioned before.
The reranker component was proposed in the Promptagator++ variant and was trained using negative data sampled from the retriever step and the positive synthetic data. They also tested a zero-shot approach for query generation where the following prompt was used irrespective of the task: '{d} Read the passage and generate a query.'. In their experiments, Promptagator outperformed ColBERTv2 and SPLADEv2 on all tested retrieval tasks.
UPR
In Unsupervised Passage Re-ranker (UPR), Sachan et al.15 proposed a fully unsupervised pipeline consisting of a retriever and a reranker that can outperform supervised dense retrieval models (like DPR4) alone. They applied UPR to a zero-shot question generation task where given a question, the retriever fetches the most relevant passages and reranker reorders these passages such that a passage with the correct answer is ranked as highly as possible.
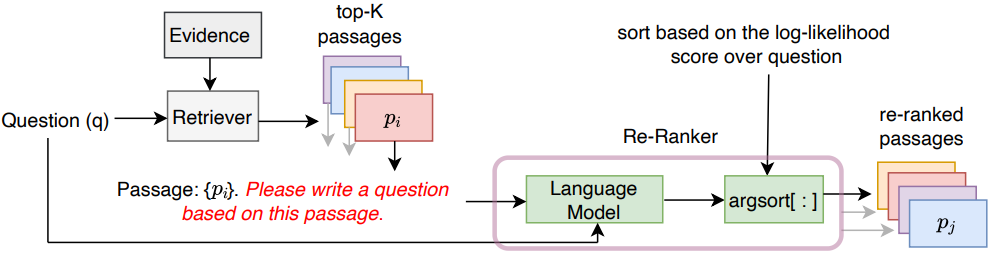
The retriever could be based on any unsupervised method like BM25, Contriever16, or MSS17, the only requirement is that the retriever provides the K most relevant passages. For the reranker, they experimented with off-the-shelf T5-lm-adapt, T0, and GPT-neo models. The rerankers were given the following prompt in a zero-shot manner: 'Passage: {p}. Please write a question based on this passage.'. The reranking score is computed as $p(z_{i}|q)$ for each passage $z_{i}$ and a query $q$. The paper shows that this relevancy score can be approximated by computing the average log-likelihood of the question conditioned on the passage, i.e. $log p(q|z)$.
In their experiments, UPR is shown to improve both unsupervised and supervised retrieval tasks in terms of top-20 passage retrieval accuracy. However, due to the LLM usage in their pipeline, UPR also suffers from high latency issues with a complexity directly proportional to the product of question and passage tokens and the number of layers in LLM. The code, data, and model checkpoints for UPR are available on GitHub.
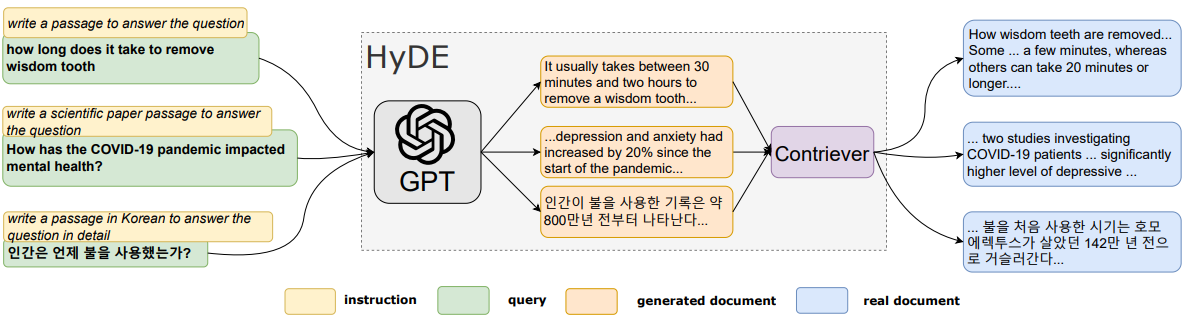
HyDE
In Hypothetical Document Embeddings (HyDE), Gao et al. 18 proposed a novel zero-shot dense retrieval method. Given a query, they first zero-shot instruct an instruction-following language model (InstructGPT) to generate a synthetic (“hypothetical”) document. Next, they use an unsupervised contrastively learned encoder (like a Contriever) to encode this hypothetical document into an embedding vector. Finally, they use a nearest-neighbor approach to fetch similar real documents based on vector similarity in corpus embedding space. The assumption here is that the bottleneck layer in the encoder filters out factual errors and incorrect details in the hypothetical document. In their experiments, HyDE outperformed the state-of-the-art unsupervised Contriever method and also performed comparably to finetuned retrievers on various tasks. The code for the HyDE method is available on GitHub.
GenRead
In Generate-then-Read (GenRead), Yu et al.19 replace the retriever in the traditional retrieve-then-read QA pipeline with a LLM generator model to create a generate-then-read pipeline instead. Their approach does not require any external world or domain knowledge. They generate a synthetic document using an InstructGPT LLM given the input query and then use the reader model on the generated document to produce the final answer. Using multiple datasets, they show that the LLM-generated document is more likely to contain correct answers than the top retrieved document, which justifies the use of the generator in this context.
Under a zero-shot setting, the generator uses a prompt like: Generate a background document to answer the given question. {question placeholder} and the reader does zero-shot reading comprehension with a prompt like: Refer to the passage below and answer the following question. Passage: {background placeholder} Question: {question placeholder}. A supervised setting with a reader model like FiD (Fusion-in-Decoder) was shown to provide better performance than a zero-shot setting. The code and generated documents for GenRead are available on GitHub.

To improve recall performance, the authors propose a clustering-based prompt method that introduces variance and diversity in generated documents. They do offline K-Means clustering on GPT-3 embeddings of a corpus of query-document pairs. At inference, a fixed number of documents are sampled from each of these clusters and given to the reader model. Their experiments showed that the GenRead model outperformed zero-shot retrieve-then-read pipeline models that used the Google search engine to get relevant contextual documents. A major limitation of this method is that the LLM model needs retraining to update the latest external world or domain knowledge.
InPars-v2
The authors of InPars released an update, called InPars-v220, where they swapped GPT-3 LLM with the open-source GPT-J (6B) model. For prompting the LLM, they only used the GBQ strategy proposed in InPars-v1. Similar to the v1 proposal they sampled 100K documents from the corpus and generated one synthetic query per document. However, instead of filtering them to top-10K pairs with the highest log probabilities of generation like the v1 method, they used a relevancy score calculated by a monoT5 (3B) model finetuned on MS MARCO, to keep the top-10K pairs. Compared to InPars-v1, this model showed better performance on a majority of the tested datasets. The code, finetuned model, and synthetic data for InPars-v2 are available on GitHub.
InPars-Light
In InPars-Light Boytsov et al.21 did a reproducibility study of InPars and also proposed some cost-effective improvements. Instead of the proprietary GPT-3, they chose to use the open-source LLM models BLOOM and GPT-J, and instead of using a MonoT5 (220M/3B), they experimented with MiniLM (30M), ERNIEv2 (335M) and DeBERTAv3 (435M) reranker models. For prompting the LLM, they used the ‘vanilla’ strategy proposed in the InPars paper. For consistency checking they used the same approach as used in the Promptagator model but with K value set to 3. They also pretrained the reranker on all-domain data. Through experiments, they showed that for a good ranking output, they only needed to rerank 100 candidates as opposed to 1000 in InPars.
UDAPDR
In Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers (UDAPDR), Falcon et al.22 used a two-stage LLM pipeline (one powerful and expensive LLM followed by a smaller and cheaper LLM) to generate synthetic queries in zero-shot settings. These queries are used to finetune a reranker model. This reranker is then distilled into a single efficient retriever.
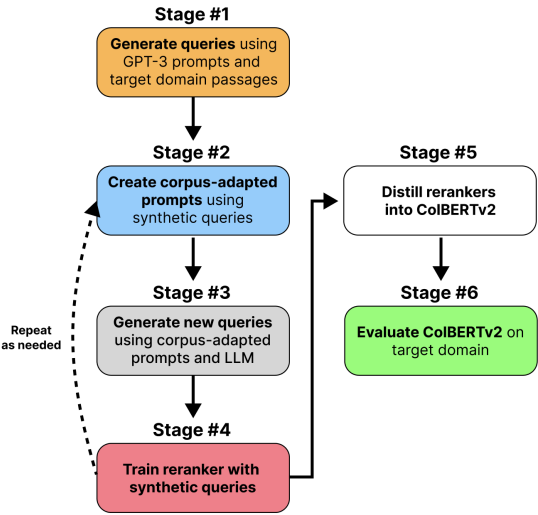
This approach requires access to in-domain passages (but no in-domain queries or labels are required). These passages and LLM-prompting is used to generate a large number of synthetic queries. These passages are first fed to a GPT-3 text-davinci-002 model, using five prompting strategies as shown below. Note that the first two prompts are the same as the InPars paper and the other three zero-short strategies are taken from another recent paper.

The generated synthetic query and document pairs are then used to populate the following prompt template. This prompt is used to generate a good query for a new passage through a smaller LLM (they used the FLAN-T5 XXL model). While the first LLM was given a few (X = 5 to 100) sampled passages (to generate 5X synthetic queries), this smaller LLM is given a much large sampled set (10K to 100K) of passages.
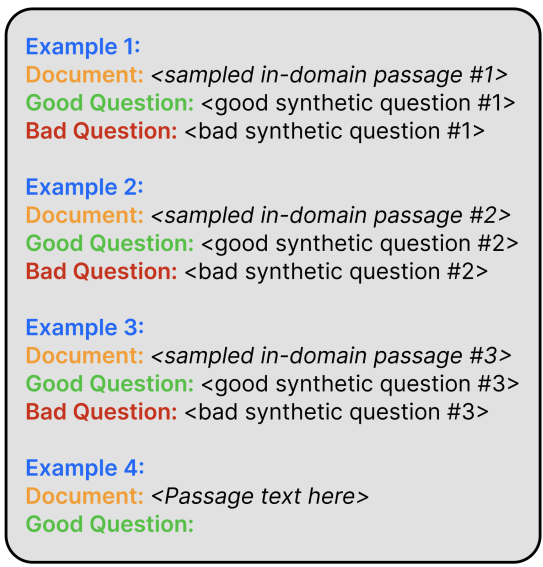
Similar to earlier work, consistency filtering is applied. UDAPDR uses a zero-shot ColBERTv2 model for this purpose and keeps the synthetic query only if it returns its gold passage within the top-20 results. Finally, a DeBERTaV3-Large reranker trained using this filtered synthetic data is distilled into a ColBERTv2 retriever model. Their experiments showed good zero-shot results in long-tail domains. One drawback of this approach is that it requires a substantial number of passages from the target domain. The code and synthetic data for UDAPDR is available on GitHub.
DataGen
In DataGen, Dua et al.9 proposed a taxonomy for dataset shift and showed that zero-shot adaptions do not work well in cases where the target domain distribution is very far from the source domain. To fix this, they prompted a Pathways Language Model (PaLM) in few-shot settings to generate a query given a passage. They prompted the model with After reading the article, <<context>> the doctor said <<sentence>>. for PubMed articles. They replaced “doctor” with engineer, journalist, and poster for StackOverflow, DailyMail, and Reddit target corpora respectively. They filtered out the questions that repeated the passage verbatim or had a 75% or more word overlap with it. Then they used both supervised and synthetic data to train their retriever model.
Summary
Similar to a majority of NLP tasks, information retrieval has recently witnessed a revolution due to large pretrained transformer models. The ability of these models to understand task instructions specified in natural language and then perform well on tasks in a zero-shot or few-shot manner has unlocked a world of possibilities and exciting solutions. This article reviewed some very recent proposals from the research community to boost text retrieval and ranking tasks using LLMs.
References
-
Robertson, Stephen. (2004). Understanding Inverse Document Frequency: On Theoretical Arguments for IDF. Journal of Documentation - J DOC. 60. 503-520. 10.1108/00220410410560582. ↩︎
-
Wang, K., Thakur, N., Reimers, N., & Gurevych, I. (2021). GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval. North American Chapter of the Association for Computational Linguistics. ↩︎
-
Ma, X., Sun, K., Pradeep, R., & Lin, J.J. (2021). A Replication Study of Dense Passage Retriever. ArXiv, abs/2104.05740. ↩︎
-
Karpukhin, Vladimir & Oğuz, Barlas & Min, Sewon & Wu, Ledell & Edunov, Sergey & Chen, Danqi & Yih, Wen-tau. (2020). Dense Passage Retrieval for Open-Domain Question Answering. ↩︎ ↩︎
-
Khattab, O., & Zaharia, M.A. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. ↩︎
-
SBERT. Cross-Encoders. https://www.sbert.net/examples/applications/cross-encoder/README.html ↩︎
-
Wang, L., Lin, J.J., & Metzler, D. (2011). A cascade ranking model for efficient ranked retrieval. Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ↩︎
-
Zhou, G., & Devlin, J. (2021). Multi-Vector Attention Models for Deep Re-ranking. Conference on Empirical Methods in Natural Language Processing. ↩︎
-
Dua, D., Strubell, E., Singh, S., & Verga, P. (2022). To Adapt or to Annotate: Challenges and Interventions for Domain Adaptation in Open-Domain Question Answering. ArXiv, abs/2212.10381. ↩︎ ↩︎ ↩︎
-
Thakur, N., Reimers, N., Ruckl’e, A., Srivastava, A., & Gurevych, I. (2021). BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models. ArXiv, abs/2104.08663. ↩︎
-
Improving Zero-Shot Ranking with Vespa Hybrid Search. https://blog.vespa.ai/improving-zero-shot-ranking-with-vespa/ ↩︎
-
Scao, T.L. et al. (2022). BLOOM: A 176B-Parameter Open-Access Multilingual Language Model. ArXiv, abs/2211.05100. ↩︎
-
Bonifacio, L.H., Abonizio, H.Q., Fadaee, M., & Nogueira, R. (2022). InPars: Data Augmentation for Information Retrieval using Large Language Models. ArXiv, abs/2202.05144. ↩︎
-
Dai, Z., Zhao, V., Ma, J., Luan, Y., Ni, J., Lu, J., Bakalov, A., Guu, K., Hall, K.B., & Chang, M. (2022). Promptagator: Few-shot Dense Retrieval From 8 Examples. ArXiv, abs/2209.11755. ↩︎
-
Sachan, D.S., Lewis, M., Joshi, M., Aghajanyan, A., Yih, W., Pineau, J., & Zettlemoyer, L. (2022). Improving Passage Retrieval with Zero-Shot Question Generation. Conference on Empirical Methods in Natural Language Processing. ↩︎
-
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., & Grave, E. (2021). Unsupervised Dense Information Retrieval with Contrastive Learning. ↩︎
-
Sachan, D.S., Reddy, S., Hamilton, W., Dyer, C., & Yogatama, D. (2021). End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering. ArXiv, abs/2106.05346. ↩︎
-
Gao, Luyu & Ma, Xueguang & Lin, Jimmy & Callan, Jamie. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. 10.48550/arXiv.2212.10496. ↩︎
-
Yu, W., Iter, D., Wang, S., Xu, Y., Ju, M., Sanyal, S., Zhu, C., Zeng, M., & Jiang, M. (2022). Generate rather than Retrieve: Large Language Models are Strong Context Generators. ArXiv, abs/2209.10063. ↩︎
-
Jeronymo, V., Bonifacio, L.H., Abonizio, H.Q., Fadaee, M., Lotufo, R.D., Zavrel, J., & Nogueira, R. (2023). InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval. ArXiv, abs/2301.01820. ↩︎
-
Boytsov, L., Patel, P., Sourabh, V., Nisar, R., Kundu, S., Ramanathan, R., & Nyberg, E. (2023). InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers. ArXiv, abs/2301.02998. ↩︎
-
Saad-Falcon, J., Khattab, O., Santhanam, K., Florian, R., Franz, M., Roukos, S., Sil, A., Sultan, M., & Potts, C. (2023). UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers. ArXiv, abs/2303.00807. ↩︎
Related Content





Did you find this article helpful?