Next Gen Recommender Systems: Real-time reranking on mobile devices

Introduction
In the age of information overload, recommender systems have become an indispensable tool in our digital lives to help catalog online content. A lot of large-scale recommender systems today are deployed as a cascade ranking architecture 1. Under such “cloud-to-edge” frameworks, a mobile client initiates a paging request to a cloud server when a user triggers a recommendation scenario, for example by opening their mobile app. And recommendation models on the server side retrieve and return a ranked list of items to be displayed to the user. Often these recommendations are computed in advance on the cloud server.
An exciting line of research has recently started exploring the potential of extending this recommendation computation to edge devices. This article is intended to help understand the need and advantage of computing real-time recommendations on mobile devices. We will also look at the system design and implementation of some of the commercial recommender systems that are built on this idea and are serving billions of users.
Why should we compute real-time recommendations on edge devices?
Shortcomings of the existing system
Due to network bandwidth and latency constraints, the server usually sends a batch of items and a pagination mechanism is implemented on the client. The server only sends the next batch when a recommendation event is triggered on the client, for example, when the user scrolls to the end of the current page. This means that the system is not designed to respond in real time to changing user behavior and interests, and it leads to the following shortcomings.
- Delays in getting system feedback: If a user makes her interests known earlier on, for example, by positively interacting with the first few videos in the recommended feed, the recommender system on the server can’t respond to this feedback until the next batch of videos is requested by the client. Depending on the architecture, it may even take tens of seconds or minutes for the recommender system on the server to process and respond to the newly collected user feedback because the new signals can only be processed at the server end. Also, some of the real-time client-specific features such as network conditions are not available to the cloud model in real-time.
- Delays in adapting to user interests: If the user interacts with an item on the current page, for example, by leaving positive feedback on a video, it is impossible to adjust the order of the remaining content of the batch, even if there are some videos that closely match the new known user interest.
Factors promoting device-side computations
Several other factors help push the idea of cost-effective computation of recommendations on edge devices as mentioned below.
- On short-video platforms like TikTok, Instagram Reels, and YouTube Shorts, the user usually watches a diverse set of short videos in a short period that belong to different topics. In such an environment, real-time user interest is constantly changing. Device-side modeling can help reduce the latency in responding quickly to perceived user interests.
- Computing power on mobile phones has increased exponentially in recent years. For instance, the TI-84 calculator developed by Texas Instruments in 2004 is 350 times faster than Apollo computers and had 32 times more RAM and 14,500 times more ROM 2.
- On-device engines like PyTorch Mobile, Google’s TFLite, and Apple’s CoreML for DNN model inference and even training have also started to gain popularity.
- Hardware-efficient neural network architectures like MobileNets, and model compression techniques based on network pruning or quantization have made it possible to optimize computation for on-device inference.
- Deploying models on the device helps to reduce server congestion.
- It is prohibitive to train the recommender algorithm at the server with embedded personalized behavior sequences for every user.
- Personalized client-side models help to unbias the server-side recommender algorithms from long-tailed users or items. It is common to have discrepancies between training and test data distributions that make the global model not optimal for each user.
- On-device training approaches like Federated Learning also help resolve some of the privacy concerns around using real-time client-specific signals.
Challenges
- Data for individual users is often insufficient and sparse to be able to train or fine-tune a model local to the edge device. Few-shot learning also has a higher generalization error and hence a higher likelihood of failing to realize the desired personalization.
- Learning from on-device data often suffers from local optimization in the long term and can lead to overfitting for individual users.
- To respect the mobile data plans and battery consumption on the user device, the models have to be kept small in size and simple to compute with.
- Updating an on-device model is often constrained by factors like Wi-Fi availability and current battery level as well.
In the on-device learning section, we will look at some of the solutions to handle the first two challenges mentioned above. Whereas in the on-device inference section, we will see some model optimizations and versioning methods to deal with the last two challenges.
Device-side computation paradigms
We can think of the majority of the prior work done in on-edge recommender systems as belonging to one of the two categories below.
- On-device Inference: In this strategy, the server sends the pre-trained model(s) to the device, and the device uses this model to run inference. This method saves communication latency between client and server while being able to capture real-time user behavior and system feedback.
- On-device Learning: A lot of the work done in this category belongs to the Federated recommender systems. This strategy aggregates the on-device trained information from multiple devices and then trains a centralized model on the server. This method overcomes some of the privacy concerns regarding user data usage. Later this article will introduce some alternatives to the federated recommender systems paradigm that do on-device learning.
Next, we will look at the design philosophy and architecture choices of some industrial large-scale examples of mobile recommender systems paradigms currently serving billions of users.
On-Device Inference
Kuaishou’s Short Video Recommendation on Mobile Devices
Chinese social network app, Kuaishou, released a paper describing an on-device inference framework used in their billion-user scale short video application 3. They developed an on-device ranking model that used users’ real-time feedback of watched videos and client-specific real-time features. Their system can react immediately to users’ implicit or explicit feedback to make appropriate ordering adjustments to remaining candidate videos.

On the cloud side, we have a traditional recommender system along with a Mobile Ranking Model Training module that uses the input features generated from the access logs from user devices and trains a ranking model. This trained model is exported to TFLite format periodically and sent to the user device for deployment. While responding to the initial paging request, the server also sends the item features for the recommended candidates along with the candidate videos. The client uses these features along with the client-specific features (watched videos and corresponding feedback along with real-time features like network signal) for inference using the on-device ranking model.
What input features are used?
The server-side model primarily focuses on modeling users’ long-term interests and uses a lot of ID features (user id, video id, crossing features), users’ watch history, etc. The following table shows the features used by the on-device reranking model. Apart from these, the model also used some engineered cross features such as time since last impression, pXTR, and impression position diffs between with preceding historical item. Note that the server-side features are not used in the on-device model because the offline experiments showed that their information has already been distilled into the predictions from the server model.
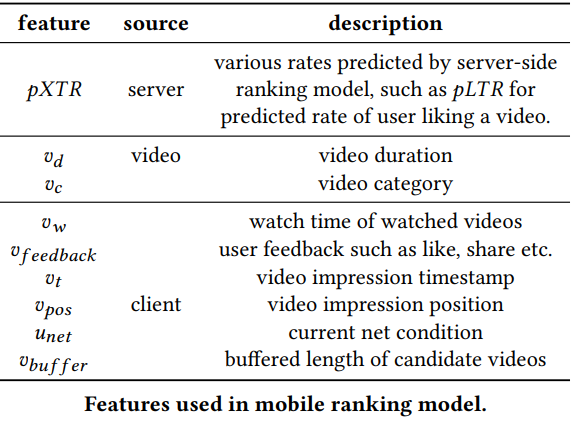
When is the on-device reranking triggered?
Kuaishou’s interface allows for only one video to occupy the current screen space. At each user swipe, the client system performs reranking with the remaining candidate videos and inserts the top-ranked candidate video at the next position.
Model Architecture
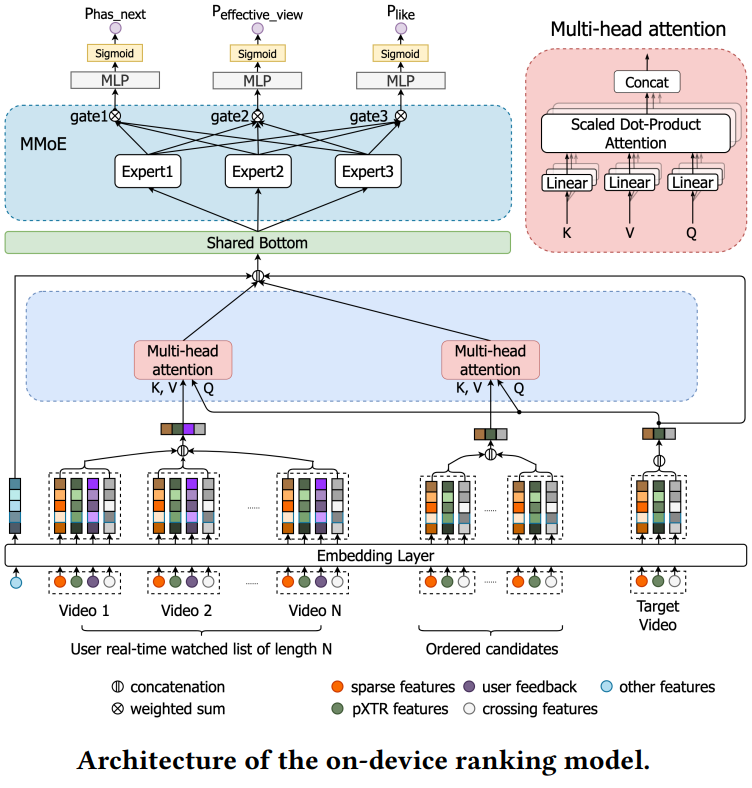
Their model also considers interaction among candidate videos. The watch history sequence is modeled using a multi-head attention (MHA) mechanism with Q projected from candidate item features and K, V projected from watch history sequence features. Only one candidate video is considered at a time. Outputs of the two MHA modules are concatenated with target features and other features and passed to a Multi-gate Mixture of Experts (MMoE) to calculate probabilities of the user continuing to watch the next video, watching the video for longer than a threshold like 3 seconds, and liking the video. The loss function is defined as the sum of log losses of each target averaged by the number of training samples. They also proposed a novel beam search strategy to further optimize evaluating all candidates in the target list.
Results
Kuaishou deployed this architecture in production to serve over a billion users, and improved effective view, like, and follow by 1.28%, 8.22%, and 13.6% respectively. Their studies also show that each inference had an average cost of 120 ms on the Android platform and 50 ms on the iOS platform. The increase in CPU and memory usage was about 2% each on Android and 0.5% and 1.5% respectively on the iOS platform.
Taobao’s EdgeRec
EdgeRec 4 was one of the earliest on-device inference-based recommender systems. It was fully deployed in Alibaba’s Taobao application and served billions of users. Through real-time computing on edge devices, EdgeRec can capture users’ diverse interests in real-time and adjust recommendation results accordingly without making any additional requests to the cloud server.
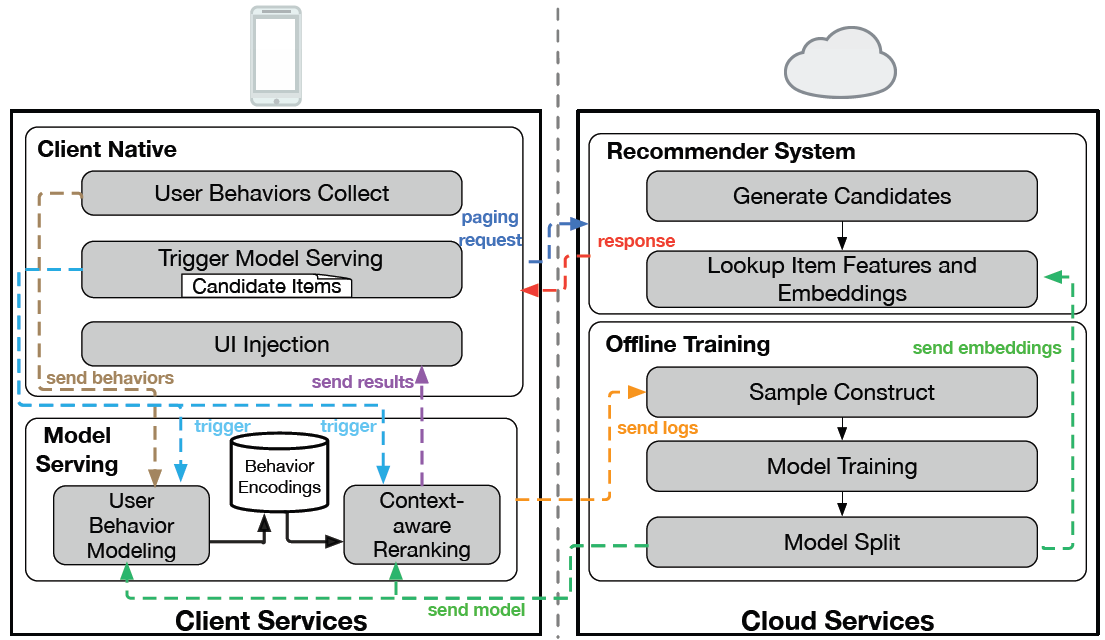
As shown above, the Client Native module collects user behavior logs (e.g. browsing and click records) and triggers model serving. It also initiates the paging request to the server and stores the features returned from the server along with the corresponding candidate items. It also updates the UI upon receiving the reranked list from the on-device model. The cloud server also uses a versioning strategy to keep the updated model synchronized with the edge devices.
What input features are used?
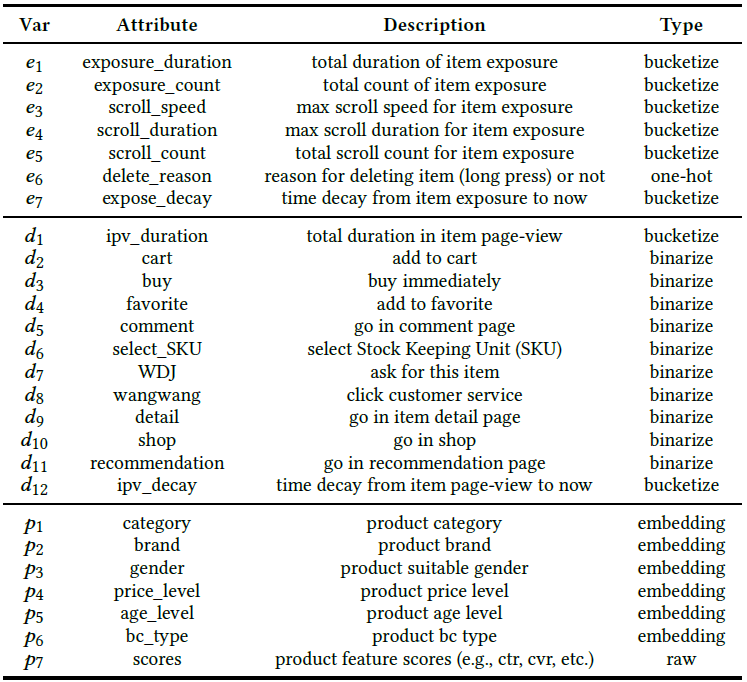
The figure above shows the collection of features used in EdgeRec. Variables $e_{1}$ to $e_{7}$ are “Item Exposure User Action” features used in the server-side recommender system that describes how the user behaves upon exposure to an item. Variables $d_{1}$ to $d_{12}$ are “Item Page-View User Action” features used in the mobile side model that describes how the user behaves on the item detail page after clicking an item. Variables $p_{1}$ to $p_{7}$ are the item features.
When is the on-device reranking triggered?
EdgeRec system sets the following three trigger points for invoking reranking of “unseen” candidate items: (1) the user clicks an item, (2) the user deletes an item (i.e. long press) and (3) k items have been exposed without being clicked.
Model Architecture
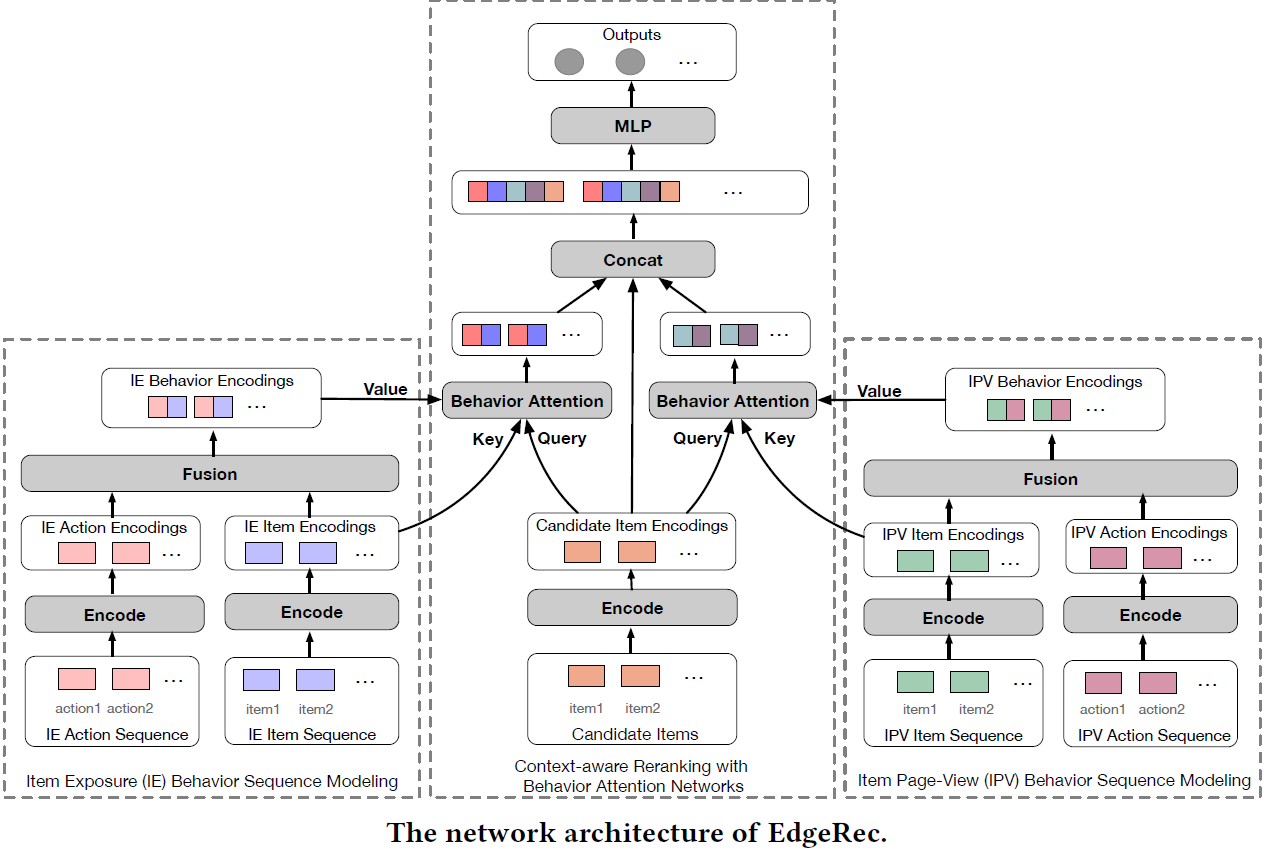
As shown in the figure above, EdgeRec models “Item Exposure Behavior Sequence” and “Item Page-View Behavior Sequence” separately because the item clicks are more sparse than the item exposures. A simple GRU layer is used as the Encoder. The context-aware reranking module uses the attention technique to automatically find parts of user behavior context that are relevant to ranking the encoded candidate items. This behavior attention also employs Item Exposure (IE) and Item Page-View (IPV) contexts.
Results
Using EdgeRec Taobao was able to achieve up to an additional 1.6% views, 7.2% click-through rate, 8.9% clicks, and 10.9% purchase amount in an online A/B experiment. The delay time for capturing user behavior was reduced from 1 minute to 300 ms. On average, the on-device model size was around 3 MB.
On-device Learning
Due to data heterogeneity, cloud models trained over the global data are non-optimal to individual users’ local data distribution. To deal with model personalization, on-device learning is a great solution. However, as explained earlier in the “challenges” section, user data on local devices is often very small and sparse which leads to overfitting and loss of generalization. In this section, we will mainly focus on solutions that can help fix this problem.
Device-Cloud Collaborative Learning (DCCL) framework
As mentioned earlier, a lot of work done under the on-device learning paradigm belongs to the Federated Recommender Systems. Under these systems, on-device learning is used to compute gradients over the local data which are then aggregated over multiple devices and used to update a central model’s parameters by approaches like federated averaging (FedAvg), etc. For example, Qi et al.5 by applying Federated Learning and differential privacy for news recommendation use case, and Lin et al.6 accounted for storage, power, and network bandwidth to distribute gradient computation among user devices and cloud servers. This centralized cloud model-based traditional approach follows the “model-over-data” paradigm. One limitation of federated learning is that it assumes the data never leaves the user device, and hence there is no concept of global data. Such a scenario is unlikely in modern recommender systems because most user data has already been uploaded to the cloud and the cloud server still does a majority of personalization computations.
In DCCL Yao et al.7 proposed an alternative “model-over-models” paradigm to model the collaboration between the device and the cloud. Under this framework, the cloud model is frozen and the edge devices use patch learning method 8 to learn the parameters of a trainable patch function using sparse local samples. These patches are then sent to the server where the cloud model uses a distillation process with these patches as meaningful priors to optimize the cloud model.
Collaborative learning with Data Augmentation (CoDA)
Gu et al. proposed a device-cloud collaborative learning framework called CoDA where the edge model also receives extra samples from the cloud’s global pool of data to augment their local dataset for training the on-device model. The edge device also maintains a personalized sample classifier for further filtering out some of the samples received from the cloud. Global models are trained with all users’ data but do inferences over each user’s local data. CoDA attempts to address this data discrepancy so that the model can be made optimal for each user. In the CoDA framework, an on-device model is trained with both local data and the augmentation data received from the server.
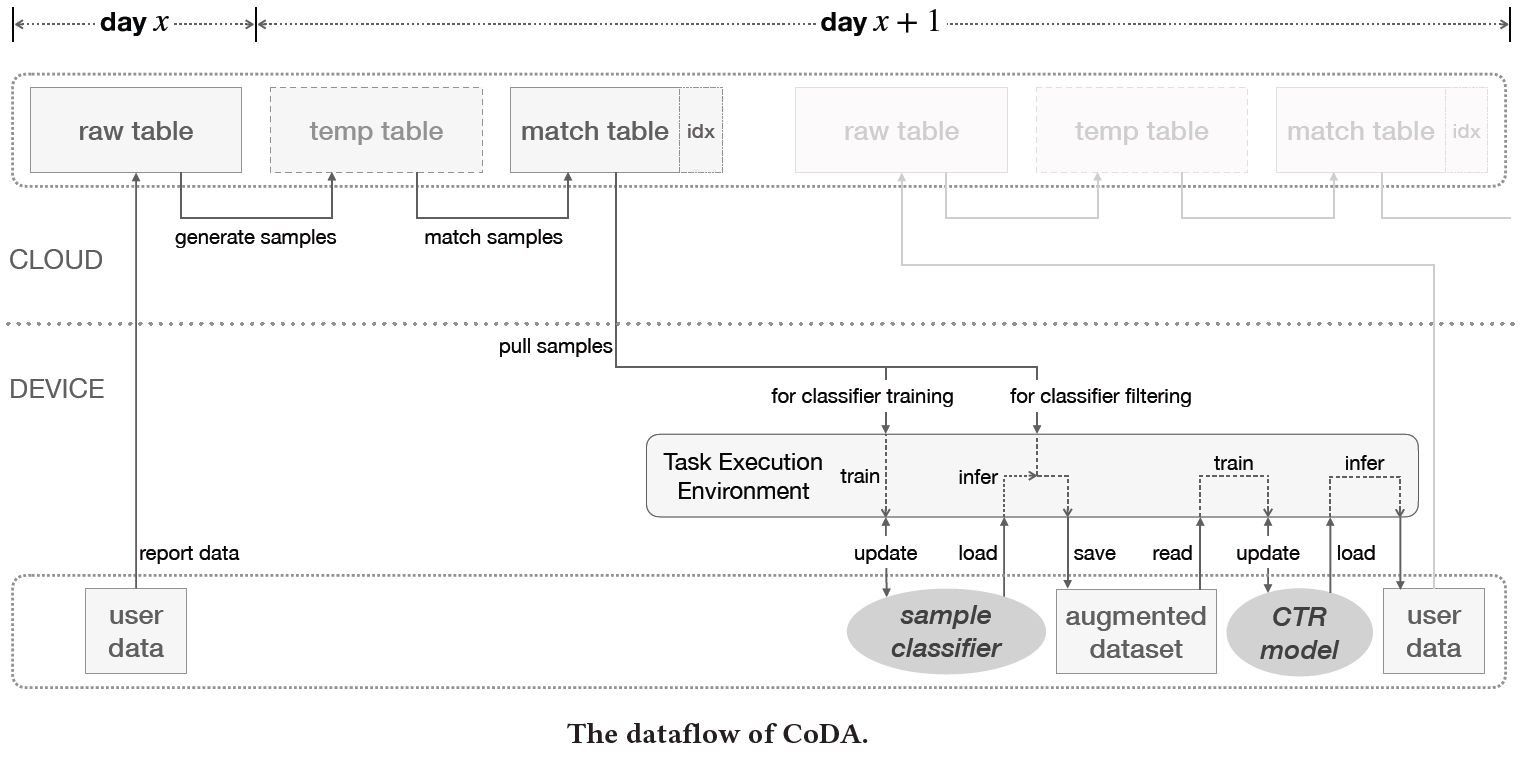
The cloud server uses a K nearest-neighbor (KNN) method on user feature vectors to find samples similar to the current user behavior. The server then desensitizes and anonymizes these samples before sending them to the end user’s device. The user device uses this augmented data and the local data for training and evaluating a personalized binary classifier. This classifier is trained to identify local samples from the combined data, and the augmentation samples with high scores (i.e. false positives) are considered close enough to be used for the on-device reranking model. The remaining augmentation data is dropped. Both classification and reranking inference tasks use models based on Deep Interest Network architecture 9.
Summary
This article explained the shortcomings of a cloud server model trained on global data for serving personalized recommendations. It introduced on-device inference and on-device learning paradigms which aim to timely capture rich user behavior and respond to users’ changing demands in real time. We also looked at system design choices and implementation details of some exemplar systems from different industrial applications that have served recommendations to billions of users.
References
-
Two Tower Model Architecture: Current State and Promising Extensions. Cascade Ranking System: https://blog.reachsumit.com/posts/2023/03/two-tower-model/#cascade-ranking-system ↩︎
-
Your smartphone is millions of times more powerful than the Apollo 11 guidance computers. https://www.zmescience.com/science/news-science/smartphone-power-compared-to-apollo-432/ ↩︎
-
Gong, X., Feng, Q., Zhang, Y., Qin, J., Ding, W., Li, B., & Jiang, P. (2022). Real-time Short Video Recommendation on Mobile Devices. Proceedings of the 31st ACM International Conference on Information & Knowledge Management. ↩︎
-
Gong, Yu & Jiang, Ziwen & Zhao, Kaiqi & Liu, Qingwen & Ou, Wenwu. (2020). EdgeRec: Recommender System on Edge in Mobile Taobao. ↩︎
-
Qi, Tao & Wu, Fangzhao & Wu, Chuhan & Huang, Yongfeng & Xie, Xing. (2020). Privacy-Preserving News Recommendation Model Training via Federated Learning. ↩︎
-
Lin, Yujie & Ren, Pengjie & Chen, Zhumin & Ren, Zhaochun & Yu, Dongxiao & Ma, Jun & Rijke, Maarten & Cheng, Xiuzhen. (2020). Meta Matrix Factorization for Federated Rating Predictions. 981-990. 10.1145/3397271.3401081. ↩︎
-
Yao, Jiangchao & Wang, Feng & Jia, Kunyang & Han, Bo & Zhou, Jingren & Yang, Hongxia. (2021). Device-Cloud Collaborative Learning for Recommendation. ↩︎
-
Yuan, F., He, X., Karatzoglou, A., & Zhang, L. (2020). Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. ↩︎
-
Zhou, Guorui & Gai, Kun & Zhu, Xiaoqiang & Song, Chenru & Fan, Ying & Zhu, Han & Ma, Xiao & Yan, Yanghui & Jin, Junqi & Li, Han. (2018). Deep Interest Network for Click-Through Rate Prediction. 1059-1068. 10.1145/3219819.3219823. ↩︎
Related Content





Did you find this article helpful?