Positive and Negative Sampling Strategies for Representation Learning in Semantic Search

Introduction
Encoders for Learning Representations
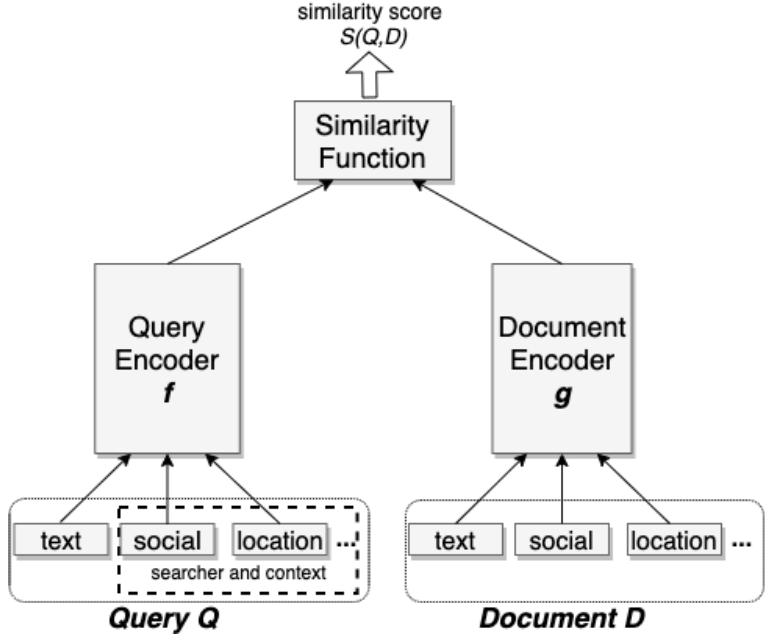
Information retrieval problems usually take a query as input and return the most relevant documents from a large corpus. For example, in open-domain question answering, a query represents a question, and documents represent evidence passages containing the answer. In Recommender systems, the query might represent a user query and documents could be a set of candidate items to recommend. A scoring function is commonly used in these approaches to quantify the relevance of a pair containing a query q and document d.
As explained in the previous post, these systems are often implemented in a cascade fashion where a less powerful but more efficient “retriever” algorithm (such as ElasticSearch, BM25, or Dual Encoder) first reduces the search space for candidates and then a more complex but powerful “reranker” algorithm (such as a Cross-Encoder) re-ranks the retrieved documents. To balance the efficiency and effectiveness tradeoff, the retriever model is focused on optimizing a high recall as otherwise the most relevant documents will not even be considered in the latter stage1. And, the reranker model focuses more on precision. This article will mainly focus on discussions around the dual-encoder-based dense retriever.
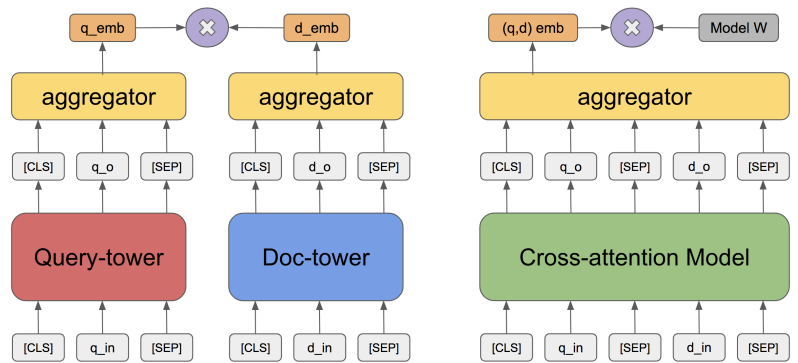
BM25 is a widely used approach that is based on token matching and TF-IDF weights. However, it lacks semantic context and can’t be optimized for a specific task. On the other hand, Dual-encoder is an embedding-based method that embeds queries and documents in the same space (aggregating just the [CLS] output) and uses a similarity measure, like the inner product, Euclidean L2 or cosine distance, to measure the similarity between learned representations for queries and documents. The model is usually trained to optimize binary cross entropy (BCE), hinge loss, or negative log-likelihood (NLL) loss.
Apart from using just the textual data for query and document towers, we can also add extra contextual information as input. For example, in Facebook Search2 the authors use character n-gram representations for text inputs due to its smaller vocabulary size and robustness to the out-of-vocabulary problem. Additionally, the authors used location signals, like city, region, country, and language for queries, and tagged locations for documents. They also leveraged embeddings generated via a separate model to embed users and entities based on their social graph. Adding location and social features gave their model’s recall an additional boost of 2.20% and 1.77% respectively.
Need for Effective Sampling
Sampling instances for such information retrieval systems is not straightforward. In systems with a large amount of data, it is infeasible to annotate all candidates for a given query. Annotators are usually given top-k candidates from a simplistic approach like BM25. So it is very likely to have a lot of unlabeled positive data3.
One approach to improve the effectiveness of the dual encoders is to also use negative examples to further emphasize the notion of similarity. It helps in separating the irrelevant pairs of queries and documents while keeping the distance smaller for relevant pairs. So, to train most of the existing dense retrieval models, we sample both positive and negative instances from the corpus. Research works, such as Qu et al.3, have shown that the retrieval model performance increases when the number of negatives is increased up to a certain point.
Calculating Contrastive Loss
Such models fall under the self-supervised learning category and are optimized by a contrastive objective in which a model is trained to maximize the scores of positive pairs and minimize the scores of negative ones. Past research shows that contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning approaches4. A contrastive loss is used to calculate the similarities of sample pairs in representation space. The target value in such loss functions doesn’t need to be fixed and it can be a data representation computed by the network on-the-fly during training5.
For example, given a query $q$ with an associated positive document $k_{+}$ and a pool of negative documents $(k_{i})_{i=1..K}$, the contrastive InfoNCE loss is defined as6:
$$ L(q, k_+) = -\frac{\exp\left(\frac{s(q, k_+)}{\tau}\right)}{\exp\left(\frac{s(q, k_+)}{\tau}\right) + \sum\limits_{i=1}^{K} \exp\left(\frac{s(q, k_i)}{\tau}\right)} $$
where $\tau$ is a temperature parameter. This loss encourages positive pairs to have high scores and negative pairs to have low scores. Similarly, for a given triplet $(q^{(i)}, d_+^{(i)}, d_-^{(i)})$, where $q^{(i)}$ is a query, $d_+^{(i)}$ and $d_-^{(i)}$ are the corresponding positive and negative documents, we can define the contrastive triplet loss as2:
$$ L=\sum\limits_{i=1}^{N} \max\left(0, D(q^{(i)}, d_+^{(i)}) - D(q^{(i)}, d^{(i)}_-) + m\right) $$
where $D(u,v)$ is a distance metric and $m$ is the margin enforced between positive and negative pairs, and N is the total number of triplets selected from the training set. This loss function separates positive and negative pairs by a distance margin. For a more comprehensive list of loss functions in contrastive learning, please refer to this post.
In the rest of the article, we will look at some of the most common approaches for sampling positive and negative instances.
How to Sample Negative Examples
For retrieval problems, usually, the positive examples are explicitly available while negative examples are to be sampled from a large corpus based on some strategy. Negative sampling is a key challenge during representation learning of a dense retriever. The first-stage retriever usually has to look through a large corpus to find the appropriate negative samples, whereas the reranker at a later stage can simply select the irrelevant examples from the previous retrieval stage to be the negative samples7. There are different sampling strategies based on heuristics or empirical results that have been adopted in industrial and academic projects.
Explicit Negatives
Some tasks naturally allow for a way to pick negative samples. For example: in Facebook Search, Huang et al.2 added non-clicked impressions, i.e. instances that were impressed but not clicked, as negatives.
Random Negatives
A simple approach to selecting negative examples is to randomly sample documents from the corpus for each query. In Facebook Search, Huang et al.2 also used random negative samples because they believed it approximates the recall optimization task. Through experiments, they found that the model trained using non-click impressions as negative has significantly worse model recall compared to using random negative. The authors hypothesized that the random documents can be completely irrelevant to the query and do not produce hard enough negative examples. So the resulting dataset would not be challenging enough for the model.
BM25 Negatives
Another way to sample negative documents is to take the top documents returned by BM25 which do not contain the answer, but still match the input query tokens. Zhan et al.8 hypothesized that BM25 biases the dense retriever to not retrieve documents with much query term overlapping, which is a distinct characteristic of these negative examples. Such behavior leads to optimization bias and harms retrieval performance.
Gold Negatives
For a given query q, all documents that are paired with other queries in the labeled data can be considered as negative documents for the query q. Karpukhin et al.9 used this approach but didn’t find significant gains over choosing random negatives.
In-batch Negatives
A more effective approach to picking gold negatives is to select gold documents of other queries in the same batch. So for a batch size B, each query can have up to B-1 negative documents. This is one of the most common approaches used to sample negatives for training dual encoders. Qu et al.3 showed that training bi-encoders with many in-batch negatives (batch size up to 4096) significantly improves the model’s effectiveness. Karpukhin et al.9 found that the choice of in-batch negatives – random, BM25, or gold – does not impact the top-k accuracy much when k ≥ 20. They also showed that while in-batch negatives are effective in learning representation, they are not always better than sparse methods like BM25 applied over the whole corpus.
While in-batch negatives can be memory-efficient to use (because we reuse the examples already loaded in a mini-batch), some research work shows that this sampling technique requires extremely large batch sizes to work well10. Xiong et al.7 argued that it is unlikely that in-batch negatives can provide meaningful samples. They hypothesized that because the majority of the corpus is only trivially related, and the batch size is much smaller than the corpus size, the probability of a random mini-batch containing meaningful negative is almost zero.
Cross-batch Negatives
Qu et al.3 proposed a cross-batch negative sampling method in a multi-GPU environment (shown at the bottom in the figure below). By using their approach, for a given query q, we sample in-batch negatives on the same GPU along with sampling negatives from all other GPUs. So for a setup with A number of GPUs and B batch size, we can sample up to $A \times B-1$ negatives for a given question. Their experiments showed improved results with negligible additional costs from using cross-batch negatives over the vanilla in-batch negative sampling method.
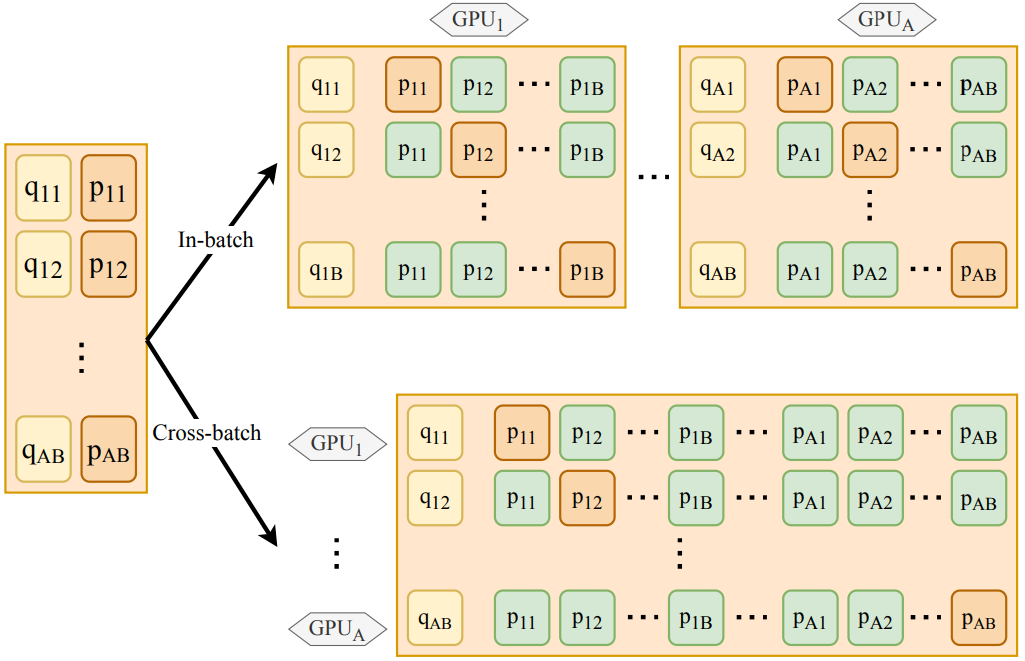
There have been several alternative approaches for sampling negatives across batches. Wu et al.11 proposed storing document representations from previous batches in a queue to be used as negative examples. While this allows for a smaller batch size to be used, it could also lead to a drop in performance when the network changes rapidly from the previous iteration to the next. He et al.5 proposed a related approach called MoCo (Momentum Contrast) that uses a queue of min-batches that stored representations generated by a separate network called the momentum encoder network. Meng et al.12 showed that the MoCo method is quite against noisy pairs, while the in-batch negatives method works better with queries of better quality. They also showed that MoCo’s generalization capability can be improved by using it along with data augmentation methods.
Approximate Nearest Neighbors
Another costly but well-performing sampling strategy was proposed by Xiong et al.7 who used asynchronous approximate nearest neighbors as negatives. After every few thousand steps of training, they used the current model to re-encode and re-index the documents in their corpus. Then they retrieved the top-k documents for the training queries and used them as negatives for the following training iterations until the next refresh. In other words, they picked negatives based on outdated model parameters. However, the near-state-of-the-art performance of their model comes at the cost of significantly higher training time. To tackle this, the authors implement an asynchronous index refresh that updates the ANN index once every few batches. Some recent work showed that the top documents retrieval approach of this method can be biased and unstable because of their lack of overlap with pre-retrieved negatives using random or BM25 methods and proposed an improved method called LTRe (Learning To Retrieve)8.
Hybrid
A lot of research work has chosen to combine some of the methods described above. For example, Karpukhin et al.9 achieved the best performance in their experiments by using a combination of gold passages from the same mini-batch and one BM25 negative passage. Similarly, Luan et al.13 used a combination of BM25 and random sampling to get negative pairs for training.
How to Sample Positive Examples
Supervised Setting
Explicit Positives
Under supervised settings, positive instances are explicitly available. These labels are usually task-specific and can be sampled intuitively from user activity logs. For example: in Facebook Search, Huang et al.2 added user-clicked results as likely being positive documents for the input search query. They also tried using impressed documents as positives but it didn’t provide any additional value.
Self-supervised/Unsupervised Setting
A lot of research work is based on training dense retrievers in a self-supervised or unsupervised fashion for various tasks. Contrastive Learning has been shown to lead to strong performance in these retrieval settings as well. The distinction between self-supervised and unsupervised learning in the existing literature is informal, but we will limit our discussion to their common idea of pretext tasks. The term “pretext” implies that the task being solved is not of genuine interest, but is solved only for the true purpose of learning a good data representation5. Some of the approaches listed below are also used to pre-train the retriever model14.
Inverse Cloze Task
While in the standard Cloze task, the goal is to predict masked-out text based on its context, Lee et al.14 proposed Inverse Cloze Task (ICT) that requires predicting the context given a sentence. It generates two mutually exclusive views of a document, first by randomly sampling a span of tokens from a segment of text while using the complement of the span as the second view. The two views are then used as a positive pair.
Recurring Span Retrieval
In Spider (Span-based unsupervised dense retriever), Ram et al.15 proposed a self-surprised method called recurring span retrieval for training unsupervised dense retrievers. They leverage recurring spans in different passages of the same document to create positive pairs. They also showed that this method combined with BM25 can train a retriever that sometimes outperforms supervised dense models.
Independent Cropping
Under this strategy, two contiguous spans of tokens from the same text are considered a positive pair.
Simple Text Augmentations
Simple data augmentations, such as random word deletion, replacement, or masking can also be used to create a positive pair6.
Others
Other approaches for creating positive pairs include using masked salient spans in REALM16, random cropping in Contriever6, neighboring text pieces in CPT17, and query and top-k BM25 passages in SPAR Λ18.
Hard Example Mining
Modern information retrieval tasks work with large and diverse datasets that usually contain an overwhelming number of easy examples and a small number of hard examples. Identifying and utilizing these hard examples can make the model training process more efficient and effective. Hard example mining is the process of selecting hard examples to train machine learning models. This problem has long been studied under the name, ‘Bootstrapping’. The key idea is to grow, or bootstrap, by selecting instances on which our model triggers a false alarm. So we adopt an iterative process that alternates between training a model using selected instances (that may include a random set of negative examples), and then selecting the new instances by removing the ’easy’ ones, and including an additional set on which that the trained model fails to identify correctly. For large and complex models, this process might be iterated only once19.
In this section, we will explore hard mining strategies to improve a retriever model’s ability to differentiate between similar documents. A commonly adopted strategy in this domain is to consider instances that are closer to the positive instances in the embedding space as hard negatives in training.
Hard Negative Mining
The training and inference processes for dual-encoder-based retrievers are usually inconsistent. During training, the retriever is given only a small candidate set for each question (usually 1 positive pair per question) to calculate the question-document similarity, while during inference it is required to identify a positive document for a given question out of millions of candidates. Using negative sampling methods, like cross-batch negatives, does help with reducing this vast discrepancy, but the model may still fail to learn effectively because the negatives might be too weak. Also, because fully annotating a large dataset can be prohibitive, there might also be a large number of unlabeled positives that might get picked as negative examples, leading to an increase in false positives by the model. Using reliable, hard negatives helps in alleviating such issues.
Top-ranked Negatives
A straightforward approach to picking hard negatives is to use the trained retriever to make inferences on negative samples and select the top-k ranked documents as negatives20. This approach can still suffer from false positives as a lot of negative samples could actually be unlabeled positive samples.
In-batch Hard Negatives
In Facebook Search2, the authors used the in-batch negatives to first get a set of candidate negative documents. Next, they used an approximate nearest neighbor (ANN) approach on the query and this set of negatives to find the negative closest to the input query. This negative was then used as the hard negative. In their experiments, they found that the optimal setting is at most two hard negatives per positive. Using more than two hard negatives had an adverse impact on the model quality.
Denoised Hard Negatives
To solve the false negatives issue, RocketQA3 proposed to utilize a well-trained cross-encoder to remove false negatives from top-k ranked documents. Compared to a dual encoder, a cross-encoder model is inefficient to be used for inference in real-time, but it is also a highly effective and robust method. So a cross-encoder can be used on the top-k ranked documents from a retriever and only keep the documents that are predicted to be negatives with high confidence. The final (denoised) set of negatives is more reliable and can be used as hard negatives.
ANCE
We saw earlier how Approximate nearest neighbor Negative Contrastive Learning (ANCE)7 can be used to sample negatives. The main drawback of this approach was that the inference is too expensive to compute per batch as it requires a forward pass on the entire corpus which is much bigger than the training batch. But it also means that the retrieved samples are global negatives from the entire corpus and can be considered hard negatives. They also show that the local, uninformative negative samples (with near zero gradients) can lead to diminishing gradient norms, large stochastic gradient variances, and slow learning convergence.
Caution: Note that we do not want all of the negative training instances to be hard negatives. Using only hard negatives will change the representativeness of the retrieval task training data, which might impose a non-trivial bias on the learned embeddings. For example, the model may hardly learn to retrieve if the negatives are too weak; it may be optimized in the wrong direction if the negative samples are biased8. In Facebook Search2, the authors found that models trained simply using hard negatives cannot outperform models trained with random negatives. Their experiments showed that blending random and hard negatives in training is advantageous. Increasing the ratio of easy-to-hard negatives continued the model improvement up to a 100:1 easy-to-hard ratio. They also compared sampling from different rank positions and found that using the hardest examples is not the best strategy, and sampling between ranks 101-500 achieved the best model recall.
Hard Positive Mining
While the majority of the literature focuses on bootstrapping (hard negative mining), some works also suggest mining hard positives. For example: In Facebook Search2 the authors mined potential target results for failed search sessions from searchers’ activity logs. They found that these hard positives improved the model’s effectiveness and these hard positives combined with other positive data (like clicks or impressions) can further improve the model recall.
Other Approaches
Data Augmentation
Data Augmentation is another approach commonly used to create additional positive and negative pairs for training. For example, RocketQA3 trains a cross-encoder and uses it on unlabeled data to make predictions. The positive and negative documents with high confidence scores are used to augment the training. They selected the top retrieved documents with scores less than 0.1 as negatives and those with scores higher than 0.9 as positives. They also showed that the model performance increases as the size of the augmented data increases.
In AugTriever21, the authors propose multiple unsupervised ways to extract salient spans from text documents to create pseudo-queries that can be used to create positive and negative pairs. For structured documents, they recommend utilizing structural heuristics (like title and anchor texts). For unstructured documents, they use approaches like BM25, dual encoder, and pre-trained language model to measure the salience between a document and various spans extracted from it.
Miscellaneous
In Learning To Retrieve (LTRe), Zhan et al.8 use a novel approach that doesn’t require any negative sampling. First, a pretrained document encoder to represent documents as embeddings, which are fixed throughout the training process. At each training step, a dense retrieval model outputs a batch of query representations. LTRe then uses them and performs full retrieval. Based on the retrieval results, it updates the model parameters such that queries are mapped close to the relevant documents and far from the irrelevant ones.
The methods listed above are taken from a wide survey of the NLP domain. Parallel to this, there is also a lot of work done in the computer vision domain by researchers to build positive and negative pairs for effective representation learning. For example, two independent data augmentations to the same image provide two “views”, that could be considered as a positive pair. There are also dependent transformations designed to reduce the correlation between views.
Summary
In this article, we looked at a wide range of methods to create positive and negative samples for representation learning. The article also explored the need for mining hard positive and negative samples. Through the literature survey, we learned that both easy and hard examples are important for training a retriever model. Some research work also shows that models that are optimized for recall can benefit from random negative sampling, while the models focused more on precision benefit from hard negatives2. These learnings can greatly help in designing search ranking systems that balance the effectiveness and efficiency tradeoffs.
References
-
Chang, W., Yu, F.X., Chang, Y., Yang, Y., & Kumar, S. (2020). Pre-training Tasks for Embedding-based Large-scale Retrieval. ArXiv, abs/2002.03932. ↩︎
-
Huang, J., Sharma, A., Sun, S., Xia, L., Zhang, D., Pronin, P., Padmanabhan, J., Ottaviano, G., & Yang, L. (2020). Embedding-based Retrieval in Facebook Search. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Qu, Y., Ding, Y., Liu, J., Liu, K., Ren, R., Zhao, X., Dong, D., Wu, H., & Wang, H. (2020). RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering. North American Chapter of the Association for Computational Linguistics. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Chen, T., Kornblith, S., Norouzi, M., & Hinton, G.E. (2020). A Simple Framework for Contrastive Learning of Visual Representations. ArXiv, abs/2002.05709. ↩︎
-
He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R.B. (2019). Momentum Contrast for Unsupervised Visual Representation Learning. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 9726-9735. ↩︎ ↩︎ ↩︎
-
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., & Grave, E. (2021). Towards Unsupervised Dense Information Retrieval with Contrastive Learning. ArXiv, abs/2112.09118. ↩︎ ↩︎ ↩︎
-
Xiong, L., Xiong, C., Li, Y., Tang, K., Liu, J., Bennett, P., Ahmed, J., & Overwijk, A. (2020). Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. ArXiv, abs/2007.00808. ↩︎ ↩︎ ↩︎ ↩︎
-
Zhan, J., Mao, J., Liu, Y., Zhang, M., & Ma, S. (2020). Learning To Retrieve: How to Train a Dense Retrieval Model Effectively and Efficiently. ArXiv, abs/2010.10469. ↩︎ ↩︎ ↩︎ ↩︎
-
Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L.Y., Edunov, S., Chen, D., & Yih, W. (2020). Dense Passage Retrieval for Open-Domain Question Answering. ArXiv, abs/2004.04906. ↩︎ ↩︎ ↩︎
-
Chen, T., Kornblith, S., Norouzi, M., & Hinton, G.E. (2020). A Simple Framework for Contrastive Learning of Visual Representations. ArXiv, abs/2002.05709. ↩︎
-
Wu, Z., Xiong, Y., Yu, S.X., & Lin, D. (2018). Unsupervised Feature Learning via Non-parametric Instance Discrimination. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3733-3742. ↩︎
-
Meng, R., Liu, Y., Yavuz, S., Agarwal, D., Tu, L., Yu, N., Zhang, J., Bhat, M., & Zhou, Y. (2022). AugTriever: Unsupervised Dense Retrieval by Scalable Data Augmentation. ArXiv. /abs/2212.08841 ↩︎
-
Luan, Y., Eisenstein, J., Toutanova, K., & Collins, M. (2020). Sparse, Dense, and Attentional Representations for Text Retrieval. Transactions of the Association for Computational Linguistics, 9, 329-345. ↩︎
-
Lee, K., Chang, M., & Toutanova, K. (2019). Latent Retrieval for Weakly Supervised Open Domain Question Answering. ArXiv, abs/1906.00300. ↩︎ ↩︎
-
Ram, O., Shachaf, G., Levy, O., Berant, J., & Globerson, A. (2021). Learning to Retrieve Passages without Supervision. ArXiv. /abs/2112.07708 ↩︎
-
Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M. (2020). Retrieval Augmented Language Model Pre-Training. International Conference on Machine Learning. ↩︎
-
Neelakantan, A., Xu, T.. Text and Code Embeddings by Contrastive Pre-Training. ArXiv. /abs/2201.10005 ↩︎
-
Chen, X., Lakhotia, K., Oğuz, B., Gupta, A., Lewis, P., Peshterliev, S., Mehdad, Y., Gupta, S., & Yih, W. (2021). Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One? Conference on Empirical Methods in Natural Language Processing. ↩︎
-
Shrivastava, A., Gupta, A.K., & Girshick, R.B. (2016). Training Region-Based Object Detectors with Online Hard Example Mining. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 761-769. ↩︎
-
Gillick, D., Kulkarni, S., Lansing, L., Presta, A., Baldridge, J., Ie, E., & Garcia-Olano, D. (2019). Learning Dense Representations for Entity Retrieval. ArXiv, abs/1909.10506. ↩︎
-
Meng, R., Liu, Y., Yavuz, S., Agarwal, D., Tu, L., Yu, N., Zhang, J., Bhat, M.M., & Zhou, Y. (2022). AugTriever: Unsupervised Dense Retrieval by Scalable Data Augmentation. ↩︎
Related Content





Did you find this article helpful?