SQL vs NoSQL vs NewSQL: An In-depth Literature Review

SQL Databases Origin
The concept of Relational Databases was originally developed in the 1970s by IBM 1. They are also known as SQL (Structured Query Language) databases, named after the query language used for managing data in Relational Database Management Systems (RDBMS). Over multiple years of research and development, an unmatched level of reliability, stability, and strong mechanisms to store and query data have been baked into Relational Databases. They have been the storage of choice for a majority of transactional data management applications such as banking, airline reservation, online e-commerce, and supply chain management applications.
Relations in Relational Databases
Relational Databases model the data to be stored as a collection of relations. A relation is a two-dimensional, normalized table to organize data. Each relation is composed of two parts: relation schema and relation instances. Relation schema includes the name of the relation, names of the attributes in the relation, along with their domain. Relation instances refer to the data records stored in the relation at a specific time. The following table gives an example of a relation 2.
| SID: Char(5) | Name: Char(10) | Telephone: Char(11) | Birthday: Date (dd/mm/yy) |
|---|---|---|---|
| S0001 | Alice | 05-65976597 | 10/4/1994 |
| S0002 | Dora | 06-45714571 | 15/5/1995 |
| S0003 | Ella | 07-57865869 | 20/6/1996 |
| S0004 | Kevin | 06-57995611 | 22/7/1997 |
Here “Students” is the relation; SID, name, telephone, and birthday are the names of the attributes; domain for Birthday is Date, and the relation has four data records stored.
Characteristics of Relational Databases
- Mature Ecosystem: Relational databases are well known for reliability, stability, and support achieved through decades of development.
- Support for Vertical Scaling: They can be scaled vertically to handle growing data volume by beefing up the existing server.
- Fixed Schema: They enforce strict structure (schema) constraints on the data to be stored, and provide powerful mechanisms to store and query this structured data.
- Constraints: As part of an RDB design, integrity constraints are used to check the correctness of the data input into the database. Integrity constraints not only prevent authorized users from storing illegal data into the database but also avoid data inconsistency between relations. The four common kinds of integrity constraints are: Primary Key constraints, Domain constraints, Entity integrity constraints, and Referential integrity constraints. RDBMS uses a relational model which has a relationship between tables using foreign keys, primary keys, and indexes. Because of this, fetching and storing of data becomes faster than the older Navigational models that RDBMS replaced 3.
- Support for Transactions: RDBs especially shine when it comes to managing transactions. The concept of a transaction was first proposed by Jim Gray in 1970 4, and it represents a work unit in a database system that contains a set of operations. For a transaction to behave in a safe manner it should exhibit four main properties: atomicity, consistency, isolation, and durability (ACID).
ACID Properties
This set of properties, known as ACID, increases the complexity of database systems 5, but also guarantees strong consistency and serializability.
- Atomicity: a guarantee that all of the operations of a transaction will be completed as a whole or none at all
- Consistency: a guarantee that the saved data will always be valid and the database will be consistent both before and after the transaction
- Integrity: a guarantee that the different transactions will not interfere with each other
- Durability: a guarantee that the changes of a successful transaction will persist permanently in the database even if a system failure occurs
Relational databases are ACID-compliant and hence simplify the work of the developer by guaranteeing that every operation will leave the database in a consistent state.
The Rise of NoSQL Databases
Big Data Era
In recent years, the amount of useful data in some application areas has become so vast that it cannot be stored or processed by traditional database solutions. With the launch of Web 2.0, a large amount of valuable business data started being generated. This data can be structured or unstructured and can come from multiple sources. Social networks, products viewed in virtual stores, information read by sensors, GPS signals from mobile devices, lP addresses, cookies, bar codes, etc. are examples of this phenomenon commonly referred to as Big Data 6.
Shortcomings of Relational Databases
Big Data significantly changed the way organizations viewed data. The data volume, accumulation speed, and various data types required operating in ways that Relational databases were not quite designed for. A popular survey suggested that 37.5% of leading companies were unable to analyze big data 7. Some of the major shortcomings that Relational databases exhibited are as follows.
- Scalability: Most SQL-oriented databases do not support distributed data processing and storage, making it a challenge to work with data of high volume, therefore, resulting in a need for a server with exceptional computing capabilities to handle the large data volume, which is an expensive undesirable solution.
- Flexibility: Big Data systems are primarily unstructured in nature, which meant that the need for a predefined structure of the data, i.e. explicitly defining a schema for the data being stored became difficult. Not all data could be fit into tables, so custom solutions targeting the new data models were required.
- Complexity: Database performance often decreases significantly since joins and transactions are costly in distributed environments.
- Others: Servers based on SQL standards are now prone to memory footprint, security risks, and performance issues 8.
All in all, this does not mean RDBMSs have become obsolete, but rather they have been designed with other requirements in mind and work well when extreme scalability is not required.
Introducing NoSQL databases
Traditional databases could not cope with the generation of massive amounts of information by different devices, including GPS information, RFIDs, IP addresses, unique Identifiers, data and metadata about the devices, sensor data, and historical data. A class of novel data storage systems able to cope with Big Data has subsumed under the term NoSQL databases.
NoSQL Properties
The major properties of NoSQL databases are as follows 9 10.
- Highly and Easily Scalable: NoSQL databases are designed to expand horizontally, meaning that you scale out by adding more machines into your pool of resources, while still being able to run CRUD operations over many servers.
- Sharding: Data can also be distributed across nodes in a non-overlapping way; this technique is known as Sharding, and the locations of the stored data are managed by metadata.
- Replication: To provision scaling, a lot of NoSQL databases are designed under a “let it crash” philosophy, where nodes are allowed to crash and their replicas are always ready to receive requests. NoSQL databases mostly support master-slave replication or peer-to-peer replication, making it easier for NoSQL databases to ensure high availability.
- No-Sharing Architecture: They are based on ‘No Sharing Architecture’ in which neither memory nor storage is shared. This enables each node to operate independently. The scaling thus becomes very convenient as new nodes can be easily added or removed from the system to meet the data processing requirement.
- Flexible Schema: The data to be stored in NoSQL databases do not need to conform to a strict schema. This also enables the ability to dynamically add new attributes to data records.
- Less expensive to maintain: The scalability of NoSQL databases allows the database admins to make use of pay-as-you-go pricing models of cloud-based database service providers. NoSQL databases can run on low specs devices.
- Integrated Caching: In general, as NoSQL databases are designed to be distributed, the location of the data in the cluster is leveraged to improve network usage, usually by caching remote data, and making queries to those nodes located closer in the network topology. This mechanism is often referred to as location awareness or data affinity.
- No Support for Joins: In general, NoSQL databases do not use a relational database model, and do not support SQL join operations or have very limited support for it. So the related data needs to be stored together to improve the speed of data access.
- Others: Unlike most RDBs that require a fee to purchase, most NoSQL databases are open source and free to download. NoSQL databases often have easy-to-use APIs as well.
Past researches, such as Stonebraker et al. 11, have argued that the main reasons to move to NoSQL databases are performance and flexibility. Performance is mainly focused on sharing and management of distributed data (i.e. dealing with “Big Data”), while flexibility relates to the semi-structured or unstructured data that may arise on the web.
Most Suited Applications for NoSQL
NoSQL is primarily suited 12 for applications with:
- No need for ACID properties
- Flexible Schema
- No constraints and validation to be executed in database
- Temporary data
- Different data types
- High data volume
Limitations of NoSQL Databases
- NoSQL databases are open-source which is its greatest strength but at the same time, it can be considered its greatest weakness because there are not many defined standards for NoSQL databases; so, no two NoSQL databases are equal.
- Tools like GUI mode, management console, etc. to access the database are not widely available in the market.
- Joins and transactions are costly operations for NoSQL databases.
- Most NoSQL databases do not support ACID properties, hence data consistency remains a fundamental challenge for NoSQL.
- Due to a lack of standardization, the design and query languages for NoSQL databases vary widely. This results in a steeper learning curve for NoSQL databases.
- Despite being designed with horizontal scaling in mind, not all NoSQL databases are good at automating the process of sharding.
The NewSQL Paradigm
NewSQL is a class of modern relational database management systems that aim to combine the best of SQL and NoSQL databases. NoSQL databases seek to provide the same scalable performance as NoSQL systems for online transaction processing(OLTP) read-write workloads while still maintaining the ACID guarantees of a traditional database system. Basically, it is a combination of NoSQL (Scalable) properties with Relational (ACID) Properties 13. Example systems in this category are NuoDB, VoltDB, Google Spanner, and Clustrix.
Characteristics of NewSQL Databases
- Distributed: NewSQL databases are relational databases supporting share-nothing architecture, sharding, automatic replication, and distributed transaction processing, i.e., providing ACID guarantees even across shards.
- Schemas: NewSQL databases support fixed schemas as well as schema-free databases.
- ACID-compliant: NewSQL systems preserve the ACID properties of relational databases.
- SQL Support: NewSQL databases support SQL but query complexity is very high. They also support SQL extensions.
- RAM Support: NewSQL gives high performance by keeping all data in RAM and enabling in-memory computations.
- Data Affinity: Scalability is provided by employing partitioning and replication in such a way that queries generally do not have to communicate between multiple machines. They get the required information from a single host.
Application of NewSQL: Google Spanner
Google’s Spanner is a globally distributed database system created at Google that supports distributed transactions, designed as a replacement to Megastore, a BigTable-based storage. It is a database that performs sharding of data that is a horizontal partition of data and it is spread across many Paxos state machines. Paxos state machines are used to solve consensus which is the process of agreeing upon one result when there are multiple participants. The datacenters are spread all over the world. The databases should be available globally. So for this purpose replication is used. The replication isn’t completely random. It considers the geographic locality and what kind of data is required more frequently.
Spanner works dynamically. It reshards and migrates data automatically for the purpose of load balancing. For achieving low latency and high availability most applications would probably replicate data over three or five datacenters in one geographic region. Spanner is useful when applications want strong consistency and are distributed over a large area. Spanner performs versioning of the data and stores the time stamp which is the same as the commit time. Unrequired data can be deleted with proper policies for handling old data. Spanner is very useful for OLTP concerning Big Data. It also uses SQL query language.
SQL vs NoSQL vs NewSQL database comparison
| Distinguishing Feature | SQL | NoSQL | NewSQL |
|---|---|---|---|
| Relational | Yes | No | Yes |
| ACID | Yes | No | Yes |
| SQL | Yes | No | Yes |
| OLTP | Not fully Supported | Supported | Fully Supported |
| Horizontal Scaling | No | Yes | Yes |
| Query Complexity | Low | High | Very High |
| Distributed | No | Yes | Yes |
Transactional Properties and Theorems
Now we turn our attention to some fundamental properties and theorems that will lay the foundations for understanding the key differentiating core philosophies among the different database implementations.
ACID Properties
We discussed ACID properties earlier on in this article. ACID is a combination of four properties namely Atomicity, Consistency, Isolation, and Durability. These transactional properties of the database guarantee the reliability of transactions 14.
The CAP Theorem
The CAP Theorem, also known as Brewer’s theorem was presented by Eric Brewer in 2000 and later proven by Gilbert and Lynch 15, is one of the truly influential impossibility results in the field of distributed computing, because it places an ultimate upper bound on what can be accomplished by a distributed system 6. It states that it is impossible for a distributed computer system to simultaneously provide all three of the following guarantees:
- Consistency (C): Reads and writes are always executed atomically and are strictly consistent (linearizable). Put differently, all clients have the same view on the data at all times.
- Availability (A): All clients can always find at least one copy of the requested data, even if some of the machines in a cluster are down. Put differently, it is a guarantee that every request receives a response about whether it succeeded or failed.
- Partition Tolerance (P): The system can continue operating normally in the presence of network partitions. These occur if two or more “islands” of network nodes arise that (temporarily or permanently) cannot connect to each other due to network failures.
Eric Brewer conjectured that at any given moment in time only two out of the three mentioned characteristics can be guaranteed, concluding that only distributed systems accomplishing the following combinations can be created: AP (Availability-Partition Tolerance), CP (Consistency-Partition Tolerance), or AC (Availability-Consistency). Most of the databases fall in the “AP” (eventual consistent systems) or the “CP” group because resigning P (Partition Tolerance) in a distributed system means assuming that the underlying network will never drop packages or disconnect, which is not feasible. Some systems usually are available and consistent, but fail completely when there is a partition (CA), for example, single-node relational database systems.
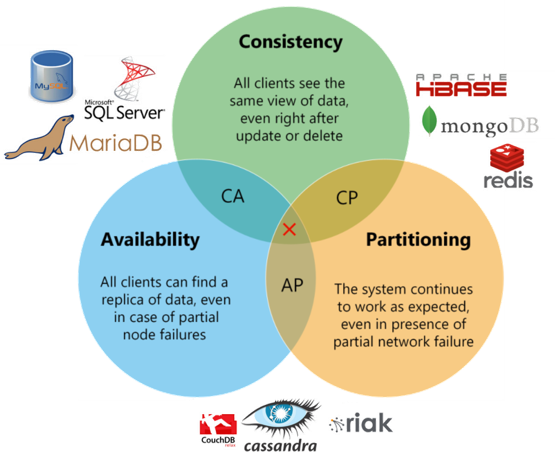
Figure: CAP theorem with databases that “choose” CA, CP, and AP [^18]
BASE Properties
Many of the NoSQL databases have loosened up the requirements on Consistency to achieve better Availability and Partitioning. This resulted in systems known as the BASE (Basically Available, Soft-state, Eventually consistent). The idea behind the systems implementing this concept is to allow partial failures instead of full system failure, which leads to a perception of greater system availability.
- Basically Available: Basically available ensures the availability of data. It means that there will always be a guaranteed response to each request. Some NoSQL DBs typically keep several copies of specific data on different servers, which allows the DB system to respond to all queries even if a few of the servers fail.
- Soft-state: Soft state means the system may change as it switches from one state to another even without any input, i.e. the data can be volatile, stored, and recovered easily and can be regenerated, unlike the hard state of the system in which the predictable inputs produce the predictable outputs. This soft state is due to the concept of eventual consistency in which the state of the system may become consistent after some time even without input.
- Eventually consistent: Eventually consistent means that the consistency is achieved after some indeterminate time because after a write operation, the replicas need to be synchronized. Therefore, strict consistency is difficult to ensure.
The design of BASE systems, and in particular BASE NoSQL databases, allows certain operations to be performed leaving the replicas (i.e., copies of the data) in an inconsistent state. ACID principles are used when data reliability and consistency are important because the focus is on consistency and availability. Whereas BASE principles are used when data viability and speed are important because the focus is on focuses on availability and partition tolerance 16.
Figure: Big Data characteristics and NoSQL System features
PACELC Theorem
It is important to note that the CAP Theorem actually does not state anything on normal operation; it merely tells us whether a system favors availability or consistency in the face of a network partition. The CAP theorem assumes a failure model that allows arbitrary messages to be dropped, reordered, or delayed indefinitely. This lack of the CAP Theorem is addressed in an article by Daniel Abadi 17 in which he points out that the CAP Theorem fails to capture the trade-off between latency and consistency during normal operation. He formulates PACELC which unifies both trade-offs and thus portrays the design space of distributed systems more accurately. From PACELC, we learn that in the case of a Partition, there is an Availability-Consistency trade-off; Else, i.e. in normal operation, there is a Latency-Consistency trade-off.
This classification basically offers two possible choices for the partition scenario (A/C) and also two for normal operation (L/C) and thus appears more fine-grained than the CAP classification. However, many systems cannot be assigned exclusively to one single PACELC class and one of the four PACELC classes, namely PC/EL, can hardly be assigned to any system 18.
BASIC Properties
SQL databases use ACID, which is the strongest consistency level, while NoSQL databases use BASE, which is a weak consistency model. Some NewSQL databases 19 support a consistency level between ACID and BASE, called BASIC (Basic Availability, Scalability, Instant Consistency) 20.
- Basic Availability: The system always responds to read/write queries.
- Scalability: Scalability allows for adding more resources if the workload is increased.
- Instant Consistency: Instant consistency, a better consistency level than eventual consistency, ensures that if a write and read operation is carried out consecutively, then the result returned by a read operation must be the same as written by a write operation.
Summary
SQL Databases, also known as RDBMS (Relational Database Management Systems) are the most common and traditional approach to database solutions. SQL solves problems ranging from fast write-oriented transactions to scan-intensive deep analytics. SQL allows users to apply their knowledge across systems and provides support for third-party add-ons and tools because it is standardized. The data is stored in a structured way in form of tables or Relations. With the advent of Big Data, however, the structured approach falls short to serve the needs of Big Data systems which are primarily unstructured in nature. Increasing the capacity of SQL although allows a huge amount of data to be managed, it does not really count as a solution to Big Data needs, which expects a fast response and quick scalability.
To solve this problem a new kind of Database system called NoSQL was introduced to provide the scalability and unstructured platform for Big Data applications. The data structures used by NoSQL databases (e.g. key-value, graph, or document) differ slightly from those used by default in relational databases, making some operations faster in NoSQL and others faster in relational databases. NoSQL stands for Not Only SQL. It is also horizontally Scalable as opposed to vertical scaling in RDBMS.
NoSQL was introduced to us for resolving scalability issues but consistency issues after scalability moved us from NoSQL to NewSQL. NoSQL provided great promises to be a perfect database system for Big Data applications; it however falls short because of some major drawbacks like NoSQL does not guarantee ACID properties (Atomicity, Consistency, Isolation, and Durability) of SQL systems. It is also not compatible with earlier versions of the database. This is where NewSQL comes into the picture. NewSQL is the latest development in the world of database systems, and it is basically a Relational Database with the scalability properties of NoSQL.
What’s Next
I hope you found this database technologies review to be useful. In the next few articles, I will compare different NoSQL data models on several criteria, then I will compare the most popular databases from each NoSQL model, followed by explaining structured approaches for picking the best database for your use-case.
References
-
Don Chamberlin : “SQL”, IBM Almaden Research Center, San Jose, CA ↩︎
-
Chen, J.-K.; Lee, W.-Z. An Introduction of NoSQL Databases Based on Their Categories and Application Industries. Algorithms 2019, 12, 106. ↩︎
-
Binani, Sneha & Gutti, Ajinkya & Upadhyay, Shivam. (2016). SQL vs. NoSQL vs. NewSQL- A Comparative Study. Communications on Applied Electronics. 6. 43-46. 10.5120/cae2016652418. ↩︎
-
Jim Gray, Andreas Reuter, Transaction Processing: Concepts and Techniques, 1st ed. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1992 ↩︎
-
Corbellini, Alejandro & Mateos, Cristian & Zunino, Alejandro & Godoy, Daniela & Schiaffino, Silvia. (2017). Persisting big data: The NoSQL landscape. Information Systems. 63. 1-23. 10.1016/j.is.2016.07.009. ↩︎
-
Gessert, Felix & Wingerath, Wolfram & Friedrich, Steffen & Ritter, Norbert. (2017). NoSQL database systems: a survey and decision guidance. Computer Science - Research and Development. 32. 10.1007/s00450-016-0334-3. ↩︎ ↩︎
-
S. J. Veloso, 2015, Data Analytics Topic: Big Data [Online]. ↩︎
-
Venkatraman, S., Fahd, K., Kaspi, S., & Venkatraman, R. (2016). SQL Versus NoSQL Movement with Big Data Analytics. International Journal of Information Technology and Computer Science, 8, 59-66. ↩︎
-
Kotecha, Bansari H., and Hetal Joshiyara. “A Survey of Non-Relational Databases with Big Data.” International Journal on Recent and Innovation Trends in Computing and Communication 5.11 (2017): 143-148. ↩︎
-
Hajoui, Omar & Dehbi, Rachid & Talea, Mohamed & Ibn Batouta, Zouhair. (2015). An advanced comparative study of the most promising NoSQL and NewSQL databases with a multi-criteria analysis method. 81. 579-588. ↩︎
-
Stonebraker M (2010) Sql databases v. nosql databases. Commun ACM. 53(4):10–11 ↩︎
-
Khasawneh, Tariq & Alsahlee, Mahmoud & Safieh, Ali. (2020). SQL, NewSQL, and NOSQL Databases: A Comparative Survey. 013-021. 10.1109/ICICS49469.2020.239513. ↩︎
-
Chandra, Umesh. (2017). A Comparative Study On: Nosql, Newsql And Polygot Persistence. International Journal Of Soft Computing and Engineering (IJSE). 7. ↩︎
-
Chaudhry, Natalia & Yousaf, Muhammad. (2020). Architectural assessment of NoSQL and NewSQL systems. Distributed and Parallel Databases. 38. 10.1007/s10619-020-07310-1. ↩︎
-
Gilbert S, Lynch N (2002) Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services. SIGACT News 33(2):51–59 ↩︎
-
Khazaei, Hamzeh & Fokaefs, Marios & Zareian, Saeed & Beigi, Nasim & Ramprasad, Brian & Shtern, Mark & Gaikwad, Purwa & Litoiu, Marin. (2015). How do I choose the right NoSQL solution? A comprehensive theoretical and experimental survey. Journal of Big Data and Information Analytics (BDIA). 2. 10.3934/bdia.2016004. ↩︎
-
Abadi D (2012) Consistency tradeoffs in modern distributed data- base system design: cap is only part of the story. Computer 45(2):37–42 ↩︎
-
Lourenço, João & Cabral, Bruno & Carreiro, Paulo & Vieira, Marco & Bernardino, Jorge. (2015). Choosing the right NoSQL database for the job: a quality attribute evaluation. Journal of Big Data. 2. 18. 10.1186/s40537-015-0025-0. ↩︎
-
Yuan, Li-Yan & Wu, Lengdong & You, Jia-Huai & Shanghai, Yan & Software, Shifang. (2015). A Demonstration of Rubato DB: A Highly Scalable NewSQL Database System for OLTP and Big Data Applications. ↩︎
-
Wu, Lengdong & Yuan, Li-Yan & You, Jia-Huai. (2014). BASIC: An alternative to BASE for large-scale data management system. Proceedings - 2014 IEEE International Conference on Big Data, IEEE Big Data 2014. 10.1109/BigData.2014.7004206. ↩︎
Related Content


Did you find this article helpful?