Comparing NoSQL Models: A Guide for Selecting the Best-fitting Database Model

In the last article, I did a literature review defining the origin of SQL, NoSQL, and NewSQL. I also went over the important theorems and properties that could help in the categorization and comparison of the different types of databases. If you haven’t read that article yet, I highly recommend you to go over it: SQL vs NoSQL vs NewSQL: An In-depth Literature Review. In this article, we will build upon those concepts and learn how to categorize NoSQL databases based on the type of data we intend to store.
Tackling the Data Variety
Variety is one of defining aspects, the 7 Vs, of Big Data. It refers to the diverse, complex, and unstructured nature of the data generated by new channels and emerging technologies, such as social media, IoT, mobile devices, and online advertising. A majority of these processes generate semi-structured or unstructured data. This includes tabular data (databases), hierarchical data, documents, XML, emails, blogs, instant messaging, click streams, log files, data metering, images, audio, video, and information about share rates (stock ticker), financial transactions, etc 1.
NoSQL provides a simple and flexible technology for the storage and retrieval of such data. This new DBMS drops the structure, entity relationships, and most of the other principles of the ACID (Atomicity, Consistency, Isolation, Durability) model. Instead, it proposes a more flexible model named Basic Availability Soft State Eventual Consistency (BASE).
NoSQL Database Models
The most commonly employed distinction between NoSQL databases is the way they store and allow access to data. While Relational databases require all data to neatly fit into tables, NoSQL offers different database solutions for specific contexts without having to use a specific schema. The “one size fits all” approach of relational databases no longer applies.
According to the classification on the NoSQL database official website 2, there are 15 categories of NoSQL databases. This classification is based on the logical organization of the data (also called data models), meaning the way the data are stored in the database. Its query model specifies how to retrieve and update the data. There are hundreds of readily available NoSQL databases, and each has different use case scenarios. They are usually divided into four categories, according to their data model and storage: Key-Value Stores, Document Stores, Column Stores, and Graph databases.
Key-Value Stores
As the name suggests a key-value store consists of a set of key-value pairs with unique keys. The data is stored and accessed using keys and almost all queries are key lookup based. Key-value stores do not assume the structure of the stored data, meaning that both the key and the value can be of any structure and NoSQL has no information on the data; it just delivers the data based on the key.
If the use-case requires any assumptions about the structure of the stored data, it has to be implicitly encoded in the application logic (i.e. schema-on-read), and not explicitly defined through a data definition language (i.e. schema-on-write) 3. These stores do not support operations beyond the get-put operations-based CRUD (Create, Read, Update, Delete), and their model can be likened to a distributed hash table. They also usually do not support composite keys and secondary indexes. A logical data structure that can contain any number of key-value pairs is called a namespace.
Key-value stores commonly apply a hashing function to the key to obtain a specific node of the physical network where the value will be finally stored. To allow easy addition and/or removal of nodes, several databases take advantage of the concept of Consistent Hashing. Amazon’s DynamoDB made further improvements in this partitioning scheme by introducing virtual nodes. Similar to Consistent Hashing, some databases like Membase/CouchBase use Virtual Buckets or vBuckets to overcome the problem of redistributing keys when a node is added or removed.
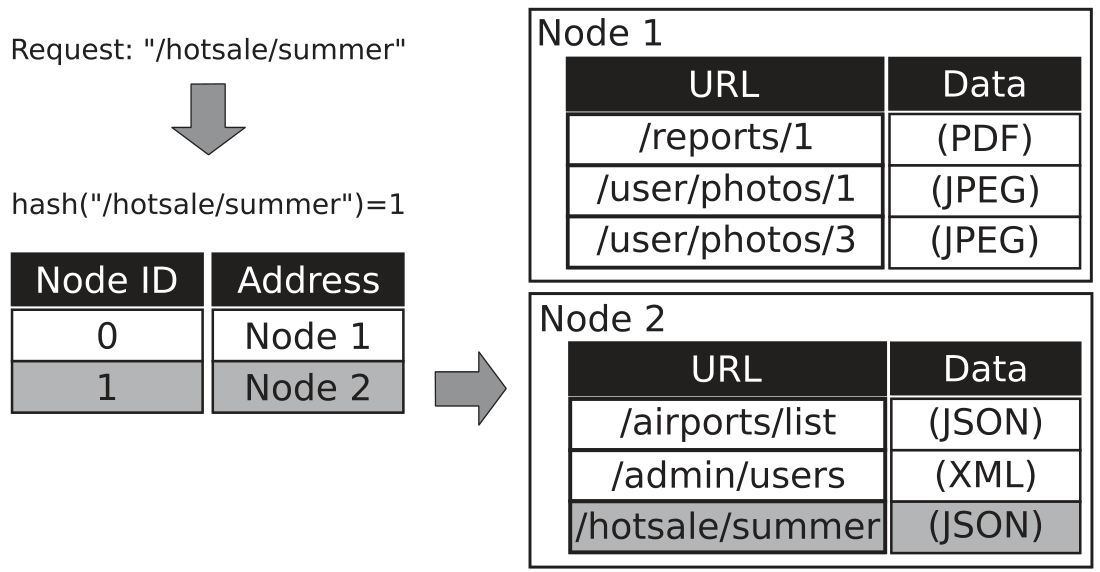
Figure: A simple key-value store example for serving static web content.
Key-value stores can be categorized into three types in terms of storage options: temporary, permanent, and hybrid stores. In temporary stores, all the data are stored in memory, hence the access to data is fast. However, data will be lost if the system is down. Permanent key-value stores ensure the high availability of data by storing the data on the hard disk but with the price of the lower speed of I/O operations on the hard disk. Hybrid approaches combine the best of both temporary and permanent types by storing the data into memory and then writing the input to the hard disk when a set of specified conditions are met 4. Some of the in-memory key-value systems are Redis, Ehcache, Aerospike, and Tarantool. Persistent key-value systems include RocksDB, and LevelDB 5.
Strengths of Key-Value Stores
- The simplicity of such a system makes it attractive in certain circumstances. For example, resource-efficient key-value stores are often applied in embedded systems or as high-performance in-process databases
- They are horizontally scalable. Partitioning and data querying is easy because of their simple abstraction.
- They provide low latency and high throughput. The time complexity of its data access is O(1)
- They can be optimized for reads or writes.
Weaknesses of Key-Value Stores
- They are not powerful enough if an application requires complex operations such as range querying.
- KV Stores needs to return the entire value when accessing a key because the stored data is schemaless.
- In-place updates are generally not supported.
- It is hard for these stores to support reporting, analytics, aggregation, or ordered values.
Example Applications of Key-value Stores
Key-value stores are generally good solutions if you have a simple application with only one kind of object, and you only need to look up objects based on one attribute 4. Some examples of use-cases for KV stores are listed below 6.
- Data storage with simple querying needs
- Profiles, user preferences
- Data from a cart of purchases
- Sensor data, logs
- Data cache for rarely updated data
- Large-scale sessions management for users
Document-Oriented Stores
Document stores extend the unstructured storage paradigm of key-value stores and make the values to be semi-structured, specifically attribute name/value pairs, called documents. A document, in this context, is a JSON or JSON-like object (such as XML, YAML, or BSON). This restriction brings flexibility in accessing the data because it is now possible to fetch either an entire document by its key or to only retrieve parts of the document. The document-oriented database still regards the document as a whole, instead of partitioning the document into many key/value pairs. This enables the documents of different structures to be put into the same set. The document-oriented database supports document index, including not only primary identifiers but also document properties 7. Also, unlike key-value stores, both keys and values are fully searchable in document databases. They also usually support complex keys along with secondary indexes.
Each document can store hundreds of attributes, and the number and type of attributes stored can vary from document to document (schema-free!). The attribute names are dynamically defined for each document at runtime, and values can be nested documents, or lists, as well as scalar values. Most of the databases available under this category provide data access typically over HTTP protocol using RESTful API or over Apache Thrift protocol for cross-language interoperability. A group of documents is called a collection. The documents within a collection are usually related to the same subject, such as employees, products, and so on.

Figure: A simple Document store example for customer data.
Document stores make it possible to add and delete value fields, modify certain fields, and query the database by fields. Queries can be done on any field using patterns, so, ranges, logical operators, wildcards, and more, can also be used in queries. The drawback is that for each type of query a new index needs to be created 8. According to db-engines 9, some highly ranked document-oriented systems include MongoDB, Couchbase, CouchDB, Realm, MarkLogic, OrientDB, RavenDB, PouchDB, and RethinkDB.
Strengths of Document Stores
- They tend to support more complex data models than key-value stores.
- They usually support multiple indexes and range querying.
- They support data access over RESTful API.
- Documents can be nested due to the schemaless nature of the store.
- They typically support low latency reads.
Weaknesses of Document Stores
- Joins are still not available within the database. A query requiring documents from two collections will require two separate queries.
- A lot of document stores have security concerns in regards to data leakage on web apps. However, this problem is prevalent among other NoSQL models as well.
Example Applications of Document Stores
A Document-oriented database is useful when the number of fields cannot be fully determined at application design time. Some examples of use-cases for document stores are as follows.
- Content Management Systems
- Real-time Web Analytics
- Products Catalog
- Blogs
- Analytical Platforms
Column-Oriented Stores
While the relational databases store and process the data with a row as the unit, column-oriented stores process and store the data with a column as the unit. A column-oriented store (also known as extensible record stores, wide-column stores, and column-family stores) stores each row by splitting it vertically and horizontally across the physical nodes of distributed systems. Each row can have one or more column families and is identified by a row key. Each column family can also act as a key to manipulate one or more columns. Technically a wide-column store is closer to a distributed multi-level sorted map (or a two-dimensional key-value store): the first-level keys identify rows that themselves consist of key-value pairs. The first-level keys are called row keys, the second-level keys are called column keys 3.
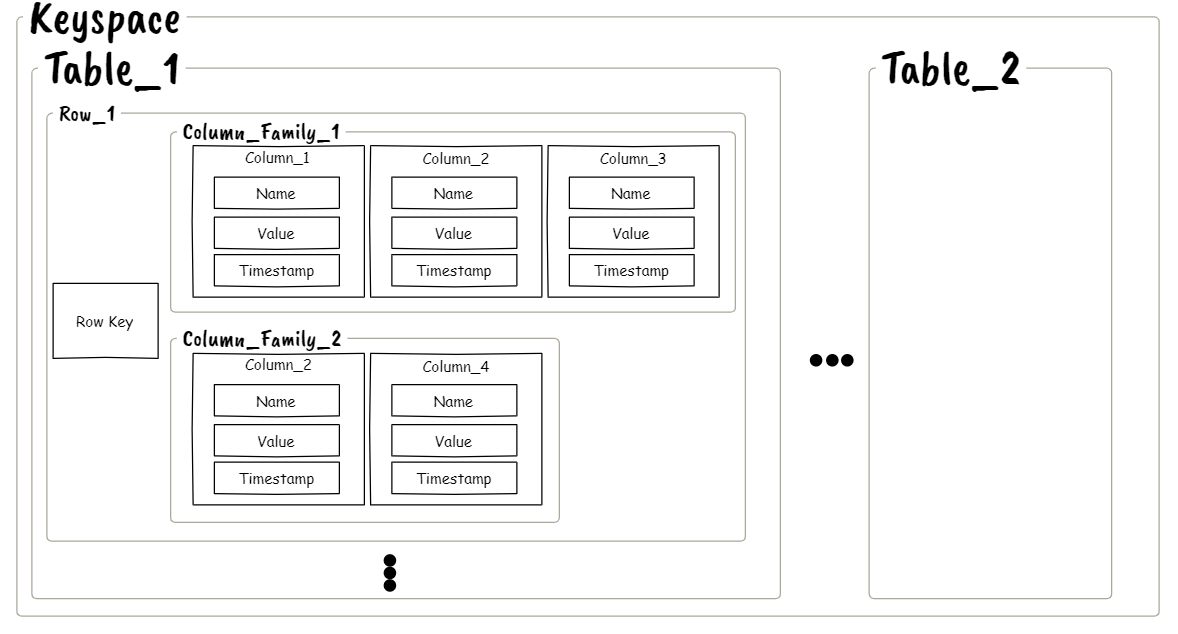
Figure: General structure for Wide-Column databases.
A Keyspace is used as the repository for the tables. The row key is similar to the key used in key-value systems for data manipulation. The set of all columns is partitioned into so-called column families to colocate columns on disks that are usually accessed together. Each column family acts as a key to manipulate one or more containing columns. Wide column stores are also called extensible record stores because they store data in records with the ability to hold very large numbers (billions) of columns (schema-free!). These column-wide data management systems are flexible enough to store the data of any format or type. The following figure represents a sample table in a wide-column datastore 4.
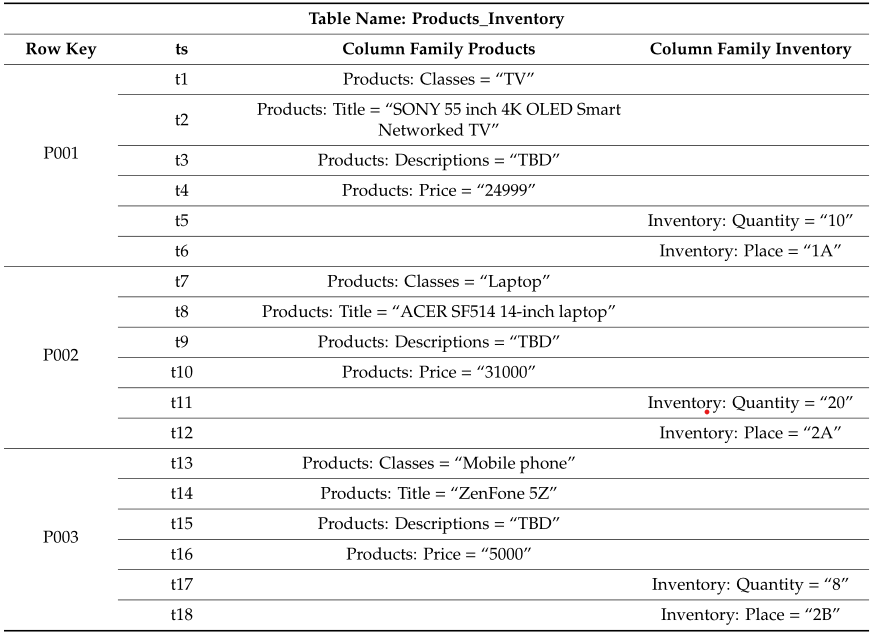
Figure: An example of a data table in a wide column store.
On disk, wide-column stores do not co-locate all data from each row, but instead values of the same column family and from the same row. Hence, an entity (a row) cannot be retrieved by one single lookup as in a document store but has to be joined together from the columns of all column families. However, this storage layout usually enables highly efficient data compression and makes retrieving only a portion of an entity very efficient. According to db-engines 10, some of the column-oriented systems that are ranked high include Cassandra, HBase, Google Cloud Bigtable, Accumulo, and ScyllaDB.
Strengths of Column-Oriented Stores
- Wide Column or Column Families databases store data by columns and do not impose a rigid scheme on user data. This means that some rows may or may not have columns of a certain type.
- Since data stored by column have the same data type, compression algorithms can be used to decrease the required space.
- Because there is no column key without a corresponding value, null values can be stored without any space overhead.
- It is also possible to do functional partitioning per column so that columns that are frequently accessed are placed in the same physical location.
- The column-oriented database is so scalable that the increase in data size will not result in decreased processing speed. So it is well-suited for processing a huge amount of data.
- They have better querying capabilities than the key-value stores due to the usage of row-level and column-level keys.
- Wide-column stores allow different access levels for different columns.
Weaknesses of Column-Oriented Stores
- Complexity in the development of such databases is considerably high.
- The application domain of Wide Column databases is limited to particular problems: data to be stored need to be structured and potentially reach the order of petabytes, but the search can only be done through the primary key, i.e., the ID of the row. Queries on certain columns are not possible as this would imply having an index on the entire dataset or traversing it 8.
- Referential integrity and joins are not supported.
- They are much less efficient when processing many columns simultaneously.
- Designing an effective indexing schema is difficult and time-consuming. Even then, the said schema would still not be as effective as simple relational database schemas.
Example Applications of Column-Oriented Stores
These stores are very efficient (low latency and load times!) when an aggregate needs to be computed over many rows but only for a notably smaller subset of all columns of data. They also work well when new values of a column are supplied for all rows at once, because that column data can be written efficiently and replace old column data without touching any other columns for the rows.
- Search Optimization
- Processing of structured data and Business Intelligence (BI)
- A high number of fast writes and basic analyses in real-time (Cassandra)
- Can be a good analysis store for semi-structured data
- Event Logging
Graph-Oriented Stores
Graph-oriented systems are based on graph theory that represents the objects as nodes of the graph and their relationships as the edges. In graph-oriented systems, the main focus is on the relationships, which naturally represent data and their relationships. This reduces the overhead of joins that involves the merging of columns from one or more tables. Instead of joins, each node possesses a record list of the relationships that it holds with the other nodes, eliminating the need for foreign keys and join operations 11. The graph-oriented systems are widely used in applications that embody complex relationships such as recommendation systems and social networking applications. Graph databases help us to implement graph processing requirements in the same query language level as we use for fetching graph data without the extra layer of abstraction for graph nodes and edges. This means less overhead for graph-related processing and more flexibility and performance.
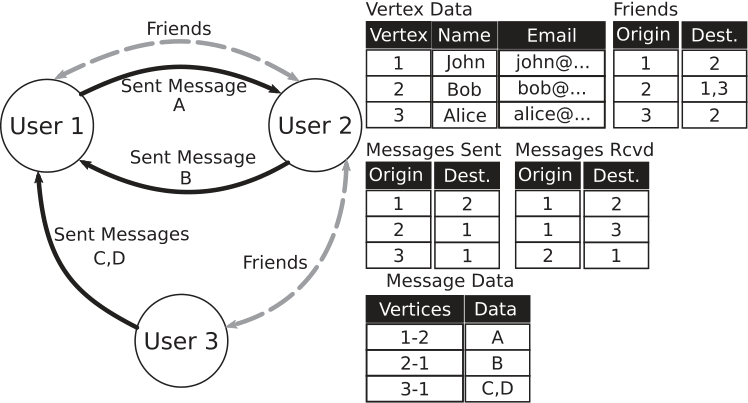
Figure: Example of vertex representation in a Graph-oriented database.
The above figure shows an example where users in a system may have friendship relationships (i.e., undirected edges) and send messages to each other (i.e., directed edges). Undirected edges are commutative and can be stored once, whereas directed edges are often stored in two different structures to provide faster access for queries in different directions. Additionally, vertices and edges have specific properties associated with them, and thereby, these properties must be stored in separate structures. According to db-engines 12, some of the graph-oriented systems that are ranked high include Neo4j, JanusGraph, TigerGraph, Dgraph, Giraph, Nebula Graph, and FlockDB.
Strengths of Graph-Oriented Stores
- They provide support for graph-based algorithms and queries. For example, deep traversals in graph databased systems are faster than relational databases.
- Graph-based stores allow for very fast execution of complex pattern-matching queries.
- They also allow for a compact representation of the data, basing its implementation on bitmaps.
- Most of them are transactional.
Weaknesses of Graph-Oriented Stores
- Distributed graph processing is challenging. Additionally, a partitioning strategy is difficult to express in source code because the structure of the graph (unlike lists or hashes) is not known a priori. This is one of the greatest pitfalls in the application of MapReduce-based frameworks in graph processing 8.
- Similar to partitioning, computing locality is also challenging. Traversal algorithms generate a significant communication overhead when the vertices are located in different computing nodes.
- Most graph-based stores do not have a declarative language.
Example Applications of Graph-Oriented Stores
- Generating recommendations
- Business Intelligence (BI)
- Semantic Web, Social networks analysis
- Geospatial Data, geolocation
- Genealogy, Web of things, Routing Services
- Authentication and authorization systems
- Fraud detection in financial services
Other NoSQL Stores
So far we have seen the four major categories of NoSQL database models. NoSQL website defines 11 other categories: Multi-model databases, Object databases, Grid/Cloud databases, XML databases, Multidimensional databases, Multi-value databases, Event Sourcing databases, Time Series databases, Scientific/Specialized databases, Others, and Unresolved and Uncategorized. The following table summarizes the suitable data processing feature for each of these databases 13.
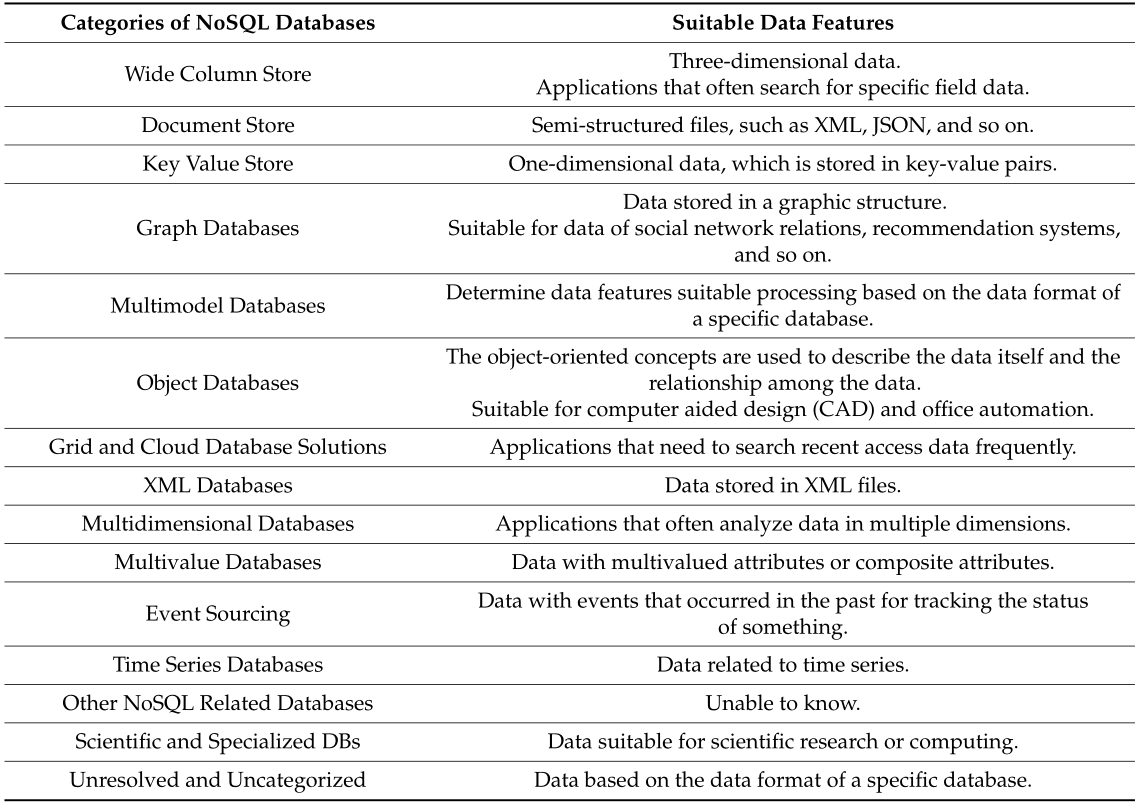
Figure: Summary of suitable data features for NoSQL databases.
Comparing NoSQL Database Models
Within the family of NoSQL databases, different systems handle size, data model, and query complexity differently. Big data requires NoSQL database solutions to address velocity and variety of data more than data volume. This notion comes from the belief that 90% of web-based companies will likely never rise to the volume levels implied by NoSQL 4. The following figure plots the different NoSQL data stores on the data volume vs. modeling complexity dimensions. There is a tradeoff between size and complexity, as can be noticed from the figure.
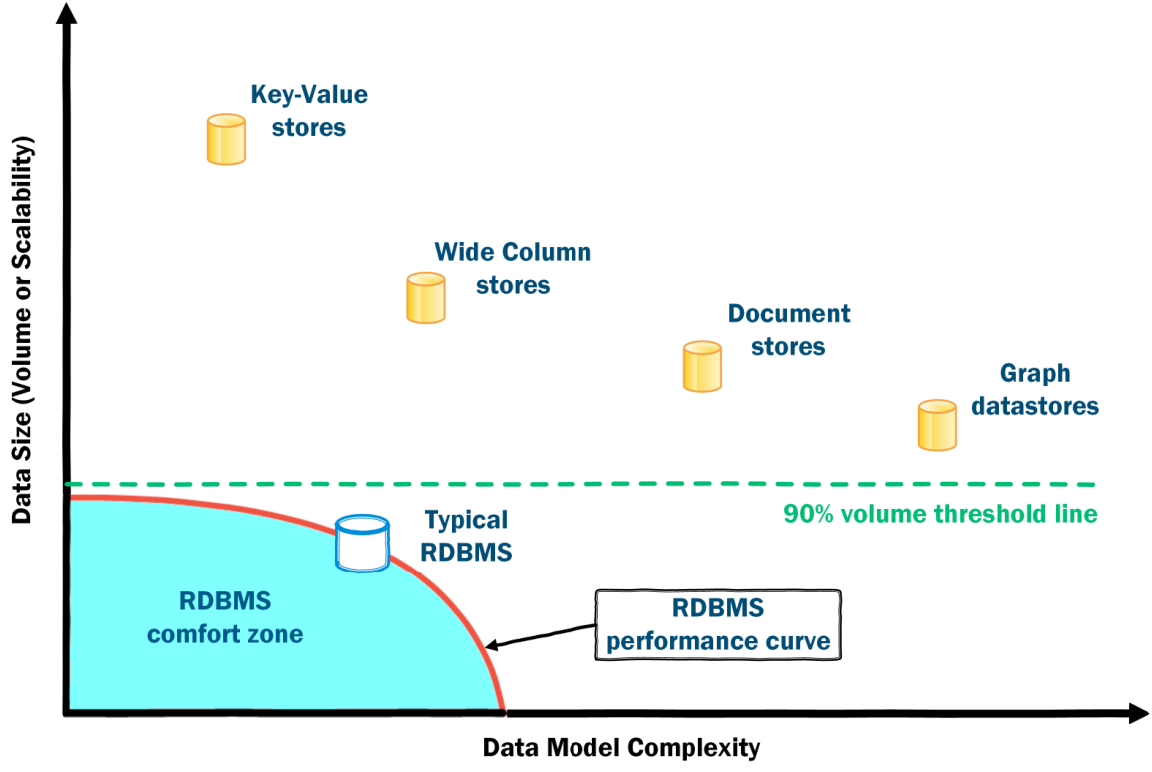
Figure: NoSQL solutions; complexity vs size.
Further, these NoSQL stores can also be compared based on non-functional requirements as shown below 14.
| Data Store Type | Performance | Scalability | Flexibility | Complexity |
|---|---|---|---|---|
| Key-value store | high | high | high | none |
| Column store | high | high | moderate | low |
| Document store | high | variable (high) | high | low |
| Graph store | variable | variable | high | high |
Summary
The most commonly employed distinction between NoSQL databases is the way they store and allow access to data. Understanding the storage model characteristics of the NoSQL databases can help individuals or organizations in selecting the most appropriate class of databases for specific data feature requirements. This article explored the four most popular NoSQL data storage models. We looked at strengths, weaknesses, and specific application domains for each of those database models, along with a basic comparison among them.
What’s Next
In the next article, we will look at the most popular database examples from each of the NoSQL models explained above. We will compare those individual databases against each other on functional and non-functional requirements. That comparison will further help the users in selecting the most appropriate database for their specific data application requirements.
References
-
Alexandru, Adriana & Alexandru, Cristina & Coardos, Dora & Tudora, Eleonora. (2016). Big data: Concepts, Technologies and Applications in the Public Sector. International Journal of Computer, Electrical, Automation, Control and Information Engineering. 10. 1629-1635. ↩︎
-
NoSQL Databases. Available online: http://nosql-database.org/ ↩︎
-
Gessert, Felix & Wingerath, Wolfram & Friedrich, Steffen & Ritter, Norbert. (2017). NoSQL database systems: a survey and decision guidance. Computer Science - Research and Development. 32. 10.1007/s00450-016-0334-3 ↩︎ ↩︎
-
Khazaei, Hamzeh & Fokaefs, Marios & Zareian, Saeed & Beigi, Nasim & Ramprasad, Brian & Shtern, Mark & Gaikwad, Purwa & Litoiu, Marin. (2015). How do I choose the right NoSQL solution? A comprehensive theoretical and experimental survey. Journal of Big Data and Information Analytics (BDIA). 2. 10.3934/bdia.2016004. ↩︎ ↩︎ ↩︎ ↩︎
-
DB-Engines Ranking of Key-value Stores. Available online: https://db-engines.com/en/ranking/key-value+store ↩︎
-
Hajoui, Omar & Dehbi, Rachid & Talea, Mohamed & Ibn Batouta, Zouhair. (2015). An advanced comparative study of the most promising NoSQL and NewSQL databases with a multi-criteria analysis method. 81. 579-588. ↩︎
-
Han, Jing, E. Haihong, Guan Le and Jian Du. “Survey on NoSQL database.” 2011 6th International Conference on Pervasive Computing and Applications (2011): 363-366. ↩︎
-
Corbellini, Alejandro & Mateos, Cristian & Zunino, Alejandro & Godoy, Daniela & Schiaffino, Silvia. (2017). Persisting big data: The NoSQL landscape. Information Systems. 63. 1-23. 10.1016/j.is.2016.07.009. ↩︎ ↩︎ ↩︎
-
DB-Engines Ranking of Document Stores. Available online: https://db-engines.com/en/ranking/document+store ↩︎
-
DB-Engines Ranking of Wide-Column Stores. Available online: https://db-engines.com/en/ranking/wide+column+store ↩︎
-
Chaudhry, Natalia & Yousaf, Muhammad. (2020). Architectural assessment of NoSQL and NewSQL systems. Distributed and Parallel Databases. 38. 10.1007/s10619-020-07310-1. ↩︎
-
DB-Engines Ranking of Graph DBMS. Available online: https://db-engines.com/en/ranking/graph+dbms ↩︎
-
Chen, & Lee,. (2019). An Introduction of NoSQL Databases Based on Their Categories and Application Industries. Algorithms. 12. 106. 10.3390/a12050106. ↩︎
-
Kotecha, Bansari H., and Hetal Joshiyara. “A Survey of Non-Relational Databases with Big Data.” International Journal on Recent and Innovation Trends in Computing and Communication 5.11 (2017): 143-148. ↩︎
Related Content


Did you find this article helpful?