Towards Empathetic Dialogue Systems

Recognizing feelings in the conversation partner and replying empathetically is a trivial skill for humans. But how can we infuse empathy into responses generated by a conversational dialogue agent or any of the text generation algorithm in Natural Language Processing? In this article, I will describe what empathy means through the lens of various academic disciplines and then do an in-depth review of the prior and current state-of-the-art NLU systems that can simulate empathy.
Empathy and its Linguistic Origin
The word empathy has a rather interesting linguistic history. In 1909, this word was first introduced in English by psychologist Edward Titchener as a translation of the German word Einfühlung, which means “feeling into” or “in-feeling”. The German word itself was adapted from the Ancient Greek word “ἐμπάθεια” or “empátheia” meaning “in passion” (from Greek ’en pathos’). Einfühlung first appeared in Robert Vischer’s 1873 Ph.D. dissertation, where Vischer used it to describe the human ability to enter into a piece of art or literature and feel the emotions of its creator1. Even though in modern Greek, the word empátheia has an opposite meaning, a strong negative feeling or prejudice against someone; the English word empathy does not carry those negative connotations.
The modern-day usage of the word empathy pertains to the range of psychological capacities that play a central role in establishing humans as social and moral animals. It enables us to “put ourselves into someone else’s shoes”. Before the introduction of “empathy” in the English language, the word sympathy was used to describe a related phenomenon of understanding others’ feelings2. However, empathy is used as a broader concept to address a phenomenon of not just understanding someone’s emotions and but also viscerally feeling them.
The Importance of Empathy
Theodor Lipps was a German philosopher who posited the theory that empathy should be understood as the primary epistemic means for gaining knowledge of other minds. While this theory has been a topic of contentious debate in the field of philosophy, the study and scientific exploration of empathy as a social science phenomenon have been less critical. There are two major focus areas involving empathy in social science. The first one treats empathy as a cognitive phenomenon and attempts to measure the accuracy of one’s abilities to recognize others’ personality, attitude, and moral traits. It concerns with the factors that affect empathy. For example, do age, gender, upbringing, family history, relationships impact empathy in a person3? The second focus area treats empathy as a rather emotional phenomenon and finds means to measure empathy and other perceptual factors that trigger empathetic responses. The interdisciplinary field of neuroscience, on the other hand, researches into the processes that neurologically enable a person to feel what another is feeling4.
Empathy enhances social functioning5. The ability to understand and share feelings of other people around us enables us to also understand their present and future mental state and actions. It can even encourage prosocial behaviors by motivating humans to act altruistically towards kin, mates and, allies6 7. In their book “Empathy Reconsidered: New Directions in Psychotherapy”, Arthur Bohart and Leslie Greenberg, explored the role that empathy plays in psychotherapy8. Their work propounded that all forms of psychotherapy are effective as a result of empathetic processes, and made the case for ensuring that psychotherapists are empathetically engaging with their clients. Other researches have shown the positive impact of empathy in mental healthcare, nursing, and even primary care. Researchers Stewart Mercer and William Reynolds highlighted the importance of empathy in the quality of primary care, in their paper titled “Empathy and quality of care”9. There are a substantial number of similar studies that show a wide range of applications of empathy in healthcare.
What does Empathy Mean for NLP?
Natural Language Processing has proved to be an exceedingly viable tool to bridge the conversational gap between humans and machines. Various industries are now using conversational AI assistants (or chatbots) to improve their customer service. Not only these artificial conversational agents can understand users’ intent and respond to them, but they are also increasingly becoming capable of understanding users’ emotions. NLP researchers are looking into ways to infuse the human trait of empathy into conversational agents to create more empathetic end-user experience.
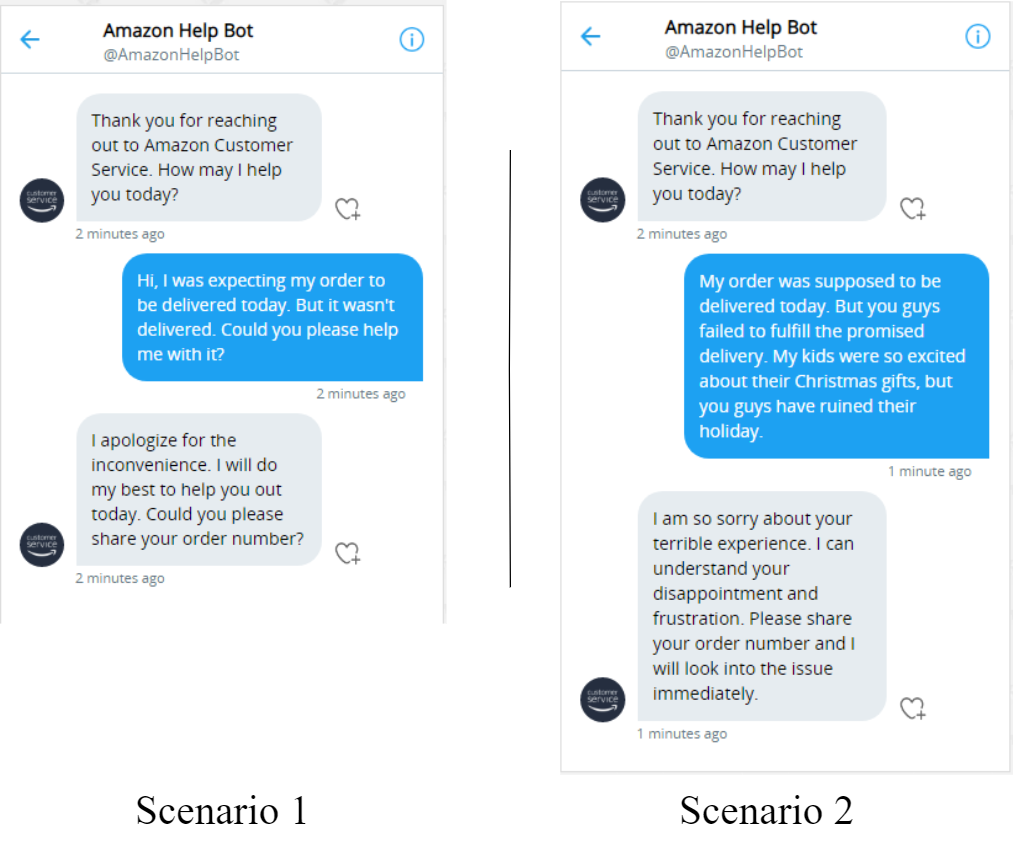
As an example, consider the following two scenarios where an Amazon customer reaches out to a customer service bot to complain about their order not being delivered on time. The choice of words used by the customer in the two scenarios convey differently charged emotions. Compared to scenario 1, the customer sounds more distressed in scenario 2. An optimal response from the bot in the second scenario should not feel like an off-the-shelf template response. An ideal response may start with first acknowledging the understanding of the customer’s frustration and displaying empathy to subdue their negatively charged emotions. A compassionate choice of words in the response can not only alleviate some of the customer annoyance, but it may also help in better customer retention in the long run.
NLP Research on Empathy
Early Works
The topics of identifying and generating empathy in natural langue processing haven’t seen as explosive research growth and application as topics like sentiment analysis. Perhaps the earliest work in identifying empathy in text data was done by Xiao et al., 201210, when they developed an N-gram language model-based maximum likelihood strategy to classify empathetic vs non-empathetic utterances from a dataset of clinical trial studies on substance use by college students. In 2015, Gibson et al.11 proposed computation of features based upon psycholinguistic norms, and in 2017, Khanpour et al.12 used a simple combination of Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM) networks to identify empathetic messages in online health communities. It’s worth highlighting that most of these researches used datasets that weren’t publicly available to the NLP community.
In 2018, Buechel et al.13 published their research which they claimed to be the first gold-standard for empathy prediction. Their paper looked at a more nuanced form of empathy that was based on psychology and included empathic concern, and personal distress. Also, the empathy ratings in their dataset were provided by writers instead of other annotators. They used Ridge regression, simple feed-forward neural nets, and CNN for their empathy prediction tasks on newswire articles. In somewhat related research, Perez-Rosas et al.14 looked into behavioral counseling and proposed a quantitative approach to understand the dynamics of counseling interactions and counselor empathy during motivational interviewing. They first identified linguistic and acoustic empathy markers and used those along with raw features to train classifiers that were able to predict counselor empathy.
Some of the other prominent researches are listed below:
Zara The Supergirl
Zara was an Empathetic Personality Recognition System created by Fung, Dey et al.15. Their research showed an interactive dialogue system that did sentiment analysis, emotion recognition, facial and speech recognition to extract user emotions in a human-robot conversational setup. They deployed their virtual robot as a webapp where users can interact with an animated cartoon character, Zara. You can watch their demo video on YouTube and also interact with their online webapp.
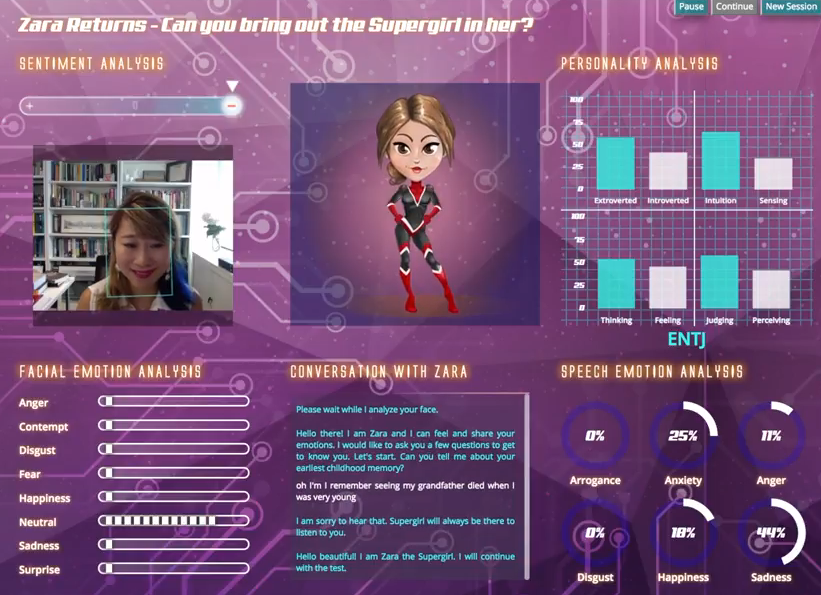
Zara assesses a user’s personality by asking a series of questions, along with the follow-up inquiries, on different topics like the user’s childhood memory, last vacation, challenges at work, etc. It uses OpenSmile and Kaldi to perform emotion recognition from user audio, keyword matches from a pool of positive and negative emotion lexicons to perform sentiment analysis, and then uses these results to calculate the scores in four personality dimensions - extroversion, intuitive, judging, perceiving.
Nora the Empathetic Psychologist
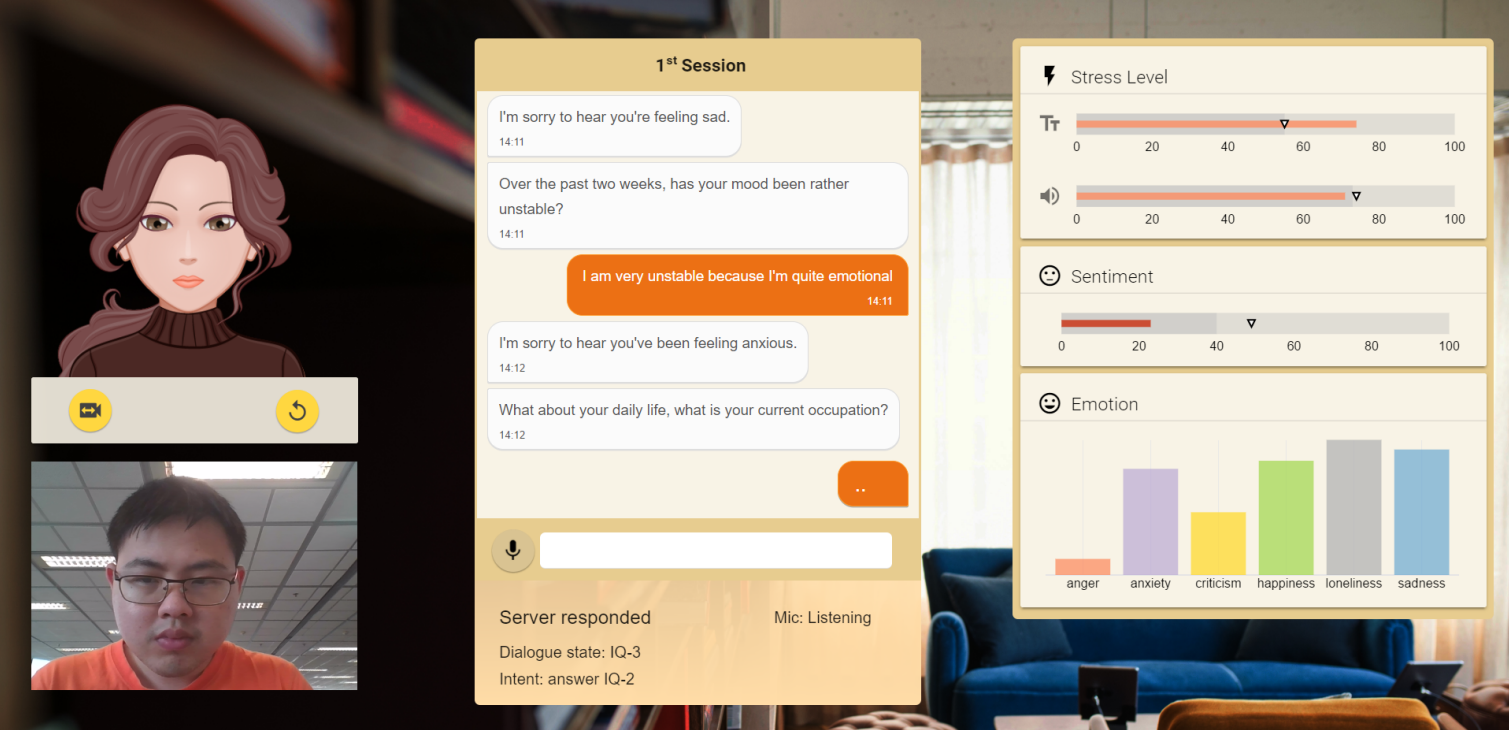
Similar to Zara, researchers Winata, Kampman et al.16 crated a virtual psychologist, an empathetic dialogue system named Nora, that could mimic a conversation with a psychologist. Nora employed a natural language understanding (NLU) module to classify user intent and slots, a dialogue management module to evaluate NLU output and manage dialog turns, and a language generation module to respond to the user. A simple CNN was used to detect stress, personality, sentiment, and six different emotions from audio.
Real-Time Speech Emotion and Sentiment Recognition for Interactive Dialogue Systems
Bertero, Siddique et al.17 also used a CNN-based approach to recognize emotion and sentiment from raw audio data in real-time to enable an empathetic conversational dialogue system. They used the Kaldi speech recognition toolkit to train deep neural network hidden Markov models (DNN-HMMs) that used the raw audio together with encode-decode parallel audio and outperformed the SVM baseline. Their work avoided any feature engineering to enable real-time speech processing.
Generating Emotionally Flexible Responses
One of the first studies into large-scale empathetic response generation was done by Zhou, Huang et al.18 in their Emotional Chatting Machine (ECM) proposal. They used a sequence-to-sequence model with GRU units to generate a response from a given input (post). While prior art, such as Ghosh et al. 201719, used to mimic the emotion inferred from the input, the authors of this paper put forth the idea that a way to give the chatbot a personality is to let it choose an emotion category for the response. However, there could be multiple emotion categories, such as sympathy, anger, happiness, etc., that could be infused in the response under different scenarios. So their work focused on enabling flexible emotional interaction between a post and a response.
![ECM Architecture]](/img/posts/generating-empathetic-responses/ecm.png)
They learn a vector representation for each category of emotion and feed this vector, along with word embeddings of the input and context output from the encoder, to the decoder. Some of the earlier psychological studies show that the emotional responses are dynamic and short-lived, so the authors create an internal memory containing a state for each of the emotional categories and at each step, the emotional state decays by a certain amount indicating that some of the emotion has been expressed. And finally, the authors provision an external memory at the decoder, which assigns generation probability for the output word to be either an emotional word (such as lovely, awesome, etc.) or a generic word (such as a person, day, etc.).
Using “natural labels” to generate an emotional response
Lack of large-scale labeled training data is a major challenge towards building empathetic natural language processing agents. Zhou and Wang, 201820 took an interesting approach to collect a large-scale emotional text dataset. They gathered Twitter conversations that included emojis in the response and assumed the emoji to be the natural label conveying the underlying emotions of the sentence. If a response contains more than one emoji, then the one with the highest occurrence (in response or in the corpus) is considered to be the label. They then trained a few variations of conditional variational autoencoder (CVAE) to automatically generate the emotional responses.
Using GAN to generate emotionally diverse responses
Generative Adversarial Nets (GANs) often suffer from problems like poor quality, lack of diversity, and mode collapse when used for text generation. But Wang and Wan, 201821 proposed a novel GAN framework, named SentiGAN, which could generate a variety of high-quality texts of different sentiment labels. For example, assuming that the goal is to generate texts with k types of sentiments(i.e. k sentiment labels), their architecture proposed training k generators simultaneously without supervision. Using a new penalty based objective each generator would be aimed at generating diversified example of a specific sentiment label. They also used a state-of-the-art sentiment classifier to guide the generation of sentimental texts. Their architecture also included one multi-class discriminator, which could make generators more focused on generating their own examples of specific sentiment labels, and stay away from other types of sentiments.
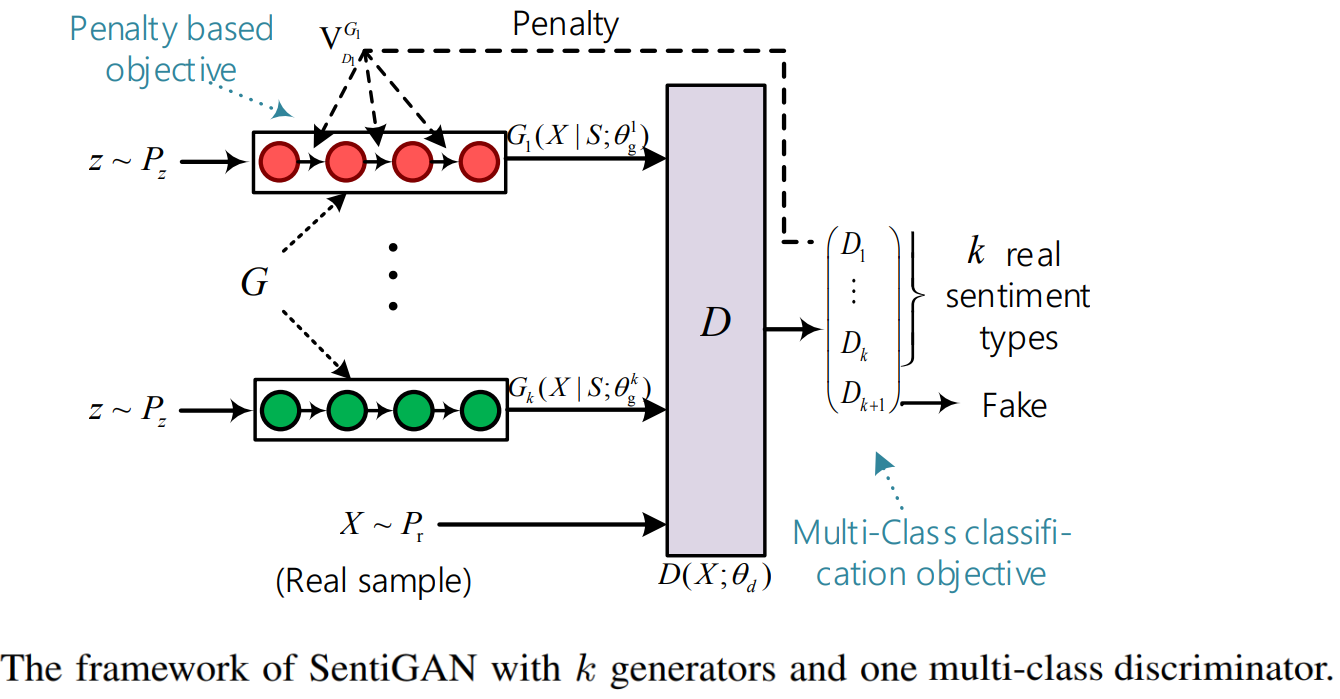
The goal of the discriminator is to distinguish between fake texts (texts generated by generators) and real texts with k sentiment types as much as possible. Along with using a well-performed sentiment classifier as evaluators to verify the sentiment accuracy of the generated texts, they also evaluated several other metrics (i.e., fluency, novelty, diversity, intelligibility) to measure the quality of generated texts from different aspects. Their work was mostly focused on generating short sentences (length ≤ 15 words) of two sentiment types (positive and negative).
A Dual-decoder framework to generate a response with given sentiment
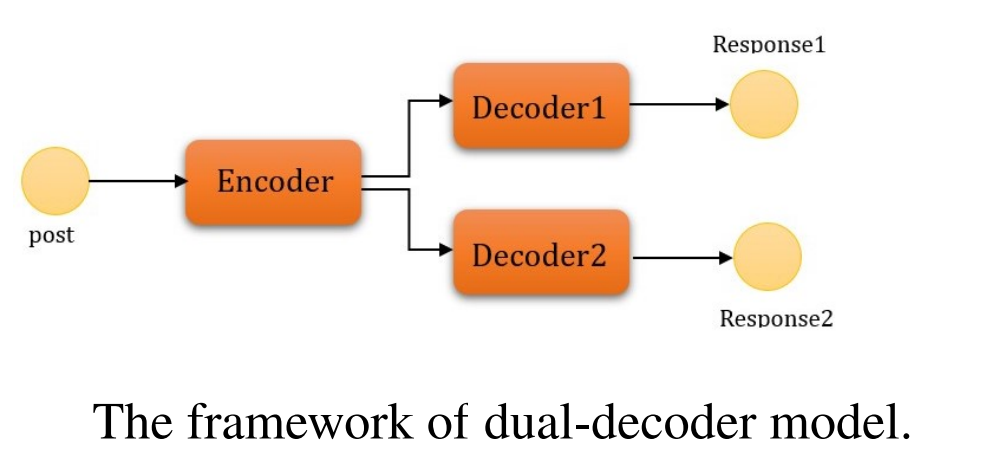
Another variation of the idea to generate a response with a fixed target emotion is seen in Xiuyu and Yunfang, 201922. They construct a new conversation dataset in the form of (post, resp1, resp2), where two responses contain opposite sentiment, positive and negative. And then used an architecture with one encoder and two sentiment decoders that could generate emotionally diverse responses.
Using Reinforcement Learning to reward future emotional states
While all of the prior work focused on either conditioning the output on a given emotion,or inferring based on the current emotion from the user’s input. Shin et al.22 instead proposed a “Sentiment Look-ahead” approach which models the user’s future emotional state. They evaluated three different Reinforcement learning strategies with a reward function that provided a higher reward to the generative model when the generated utterance improves the user’s sentiment. This improvement is calculated based upon the three different reward functions that aim to predict the user sentiment for the response to be positive or an improvement or directly uses the actual sentiment for the next user turn. They use a seq-to-seq GRU-based model and dot product attention for modeling policy and use the MIXER algorithm for policy learning.
Formalizing Empathy Generation: A new dataset from Facebook AI Research
Perhaps the first research to formally define the empathetic response generation was done by Rashkin, Smith, et al. 201923. They released a novel empathetic dialogue dataset, EMPATHETICDIALOGUES, which contains 24,850 conversations about a situation description, gathered from 810 different participants. Each conversation is grounded in a situation, which one participant writes about in association with a given emotion label out of, close to evenly distributed, 32 total emotion labels. This data was explicitly collected with instructions to be empathetic, in a one-on-one setting.
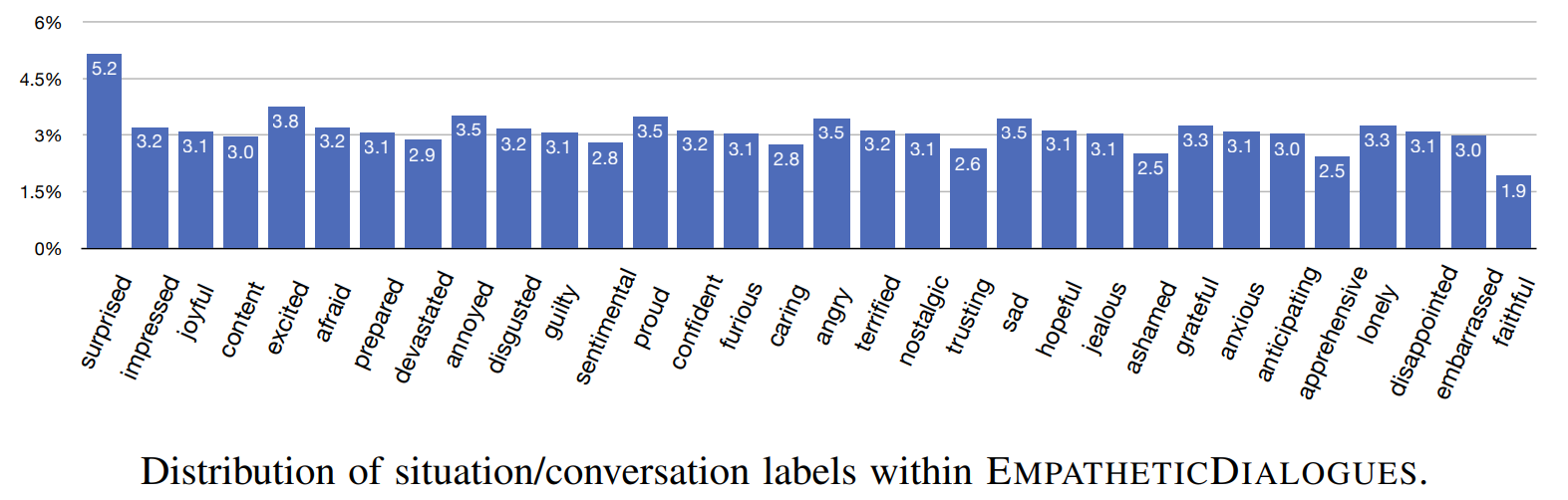
Through experiments with Transformer based models, they showed that fine-tuning a dialogue agent on their dataset results in better performance on a novel empathetic dialogue task. They conducted their experiments in two settings: Retrieval- the model was given a large set of candidate responses and it picks the “best” one, Generation- a full Transformer architecture was trained to minimize the negative log-likelihood of the target sequence and predict a sequence of words. They also proposed multiple schemes to augment the pretraining process by incorporating an external pre-trained classifier’s signal to nudge the training to include this emotion information and yield better performance. For example, in a multi-task setup, an encoded context representation could be passed to an emotion classifier and a decoder to generate a response. The encoder could then be trained with gradients from both output branches. Similarly, the output from the classifier could either be concatenated with the input or the output of the encoder.
Maximizing Positive Arousal
Lubis et al. 201824 built a system mainly focused on maximizing positive emotion elicitation from the user. Their definition of emotion is based on the circumplex model of affect (valence vs. arousal). They built a model by extending the hierarchical recurrent encoder-decoder (HRED) architecture proposed by Serban et al. 201625. Original HRED consists of a sequence-to-sequence architecture having an utterance encoder, a dialogue encoder, and an utterance decoder. This research incorporated an emotion encoder (RNN with GRU cells) into the network to capture the emotional context of a dialogue to produce an affect-sensitive response through an Emotion-sensitive HRED (Emo-HRED). The emotion encoder is placed in the same hierarchy as the dialogue encoder, capturing emotion information at the dialogue-turn level, and maintaining the emotion context history throughout the dialogue-turn.
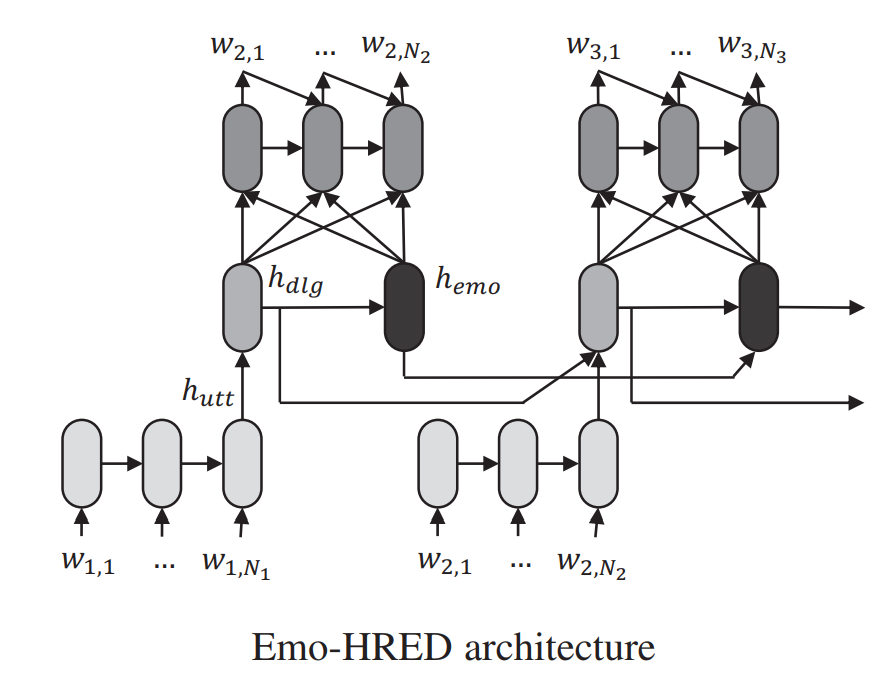
After reading the input sequence, the dialogue turn is encoded into utterance representation which is then fed into the dialogue encoder to model the sequence of dialogue turns into dialogue context. The dialogue context is then fed into the emotion encoder, which will then be used to model the emotional context. The generation process of the response is conditioned by the concatenation of the dialogue and emotional contexts. Finally, the network is trained using the positive emotion eliciting data. Because of the lack of availability of a large-scale and reliable dataset, the authors proposed selective fine-tuning of the Emo-HRED, limiting the parameter updates to the emotion encoder and utterance decoder only.
Current State-of-the-Art Research on Empathetic Response Generation
The sheer pace of progress in NLP makes it difficult to keep track of current state-of-the-art researches. And, often it is difficult to pin-down one research work as the current state-of-the-art, simply because there might be some other research that shows improvement in certain but not all of the shared metrics or different research work might have used completely different dataset for training and evaluation. However, the following two recent papers stand out for the quality of their results for empathetic response generation in dialogue systems on empathetic-dialogues dataset23.
MoEL: Mixture of Empathetic Listeners
The authors of this research (Lin et al., 2019)26 argue that prior researches made assumptions such as- understanding the emotional state of the user is enough for the model to implicitly learn how to respond appropriately without any additional inductive bias. However, this assumption may lead to generic response outputs from the single decoder that is learning to produce all emotions. Some of the other works assume that the emotion to condition the generation on is given as input, which may not always be true.
There could be multiple emotions present in different turns. Hence a dialogue state embedding is also incorporated along with word embedding and standard positional embedding to produce context embedding. This idea was originally proposed by Wolf et al., 201927.

Similar to the prior art, MoEL first encodes the dialogue context and uses it to recognize the emotional state (out of n possible states). But this architecture contains n decoders, called listeners, which are optimized to react to each context emotion. There is another listener, called meta-listener, that is trained along with other listeners and learns to softly combine the output states of all decoders according to the emotional classification distribution. This idea of having independent specialized experts (Listeners) was originally inspired by Shazeer et al. (2017)28.
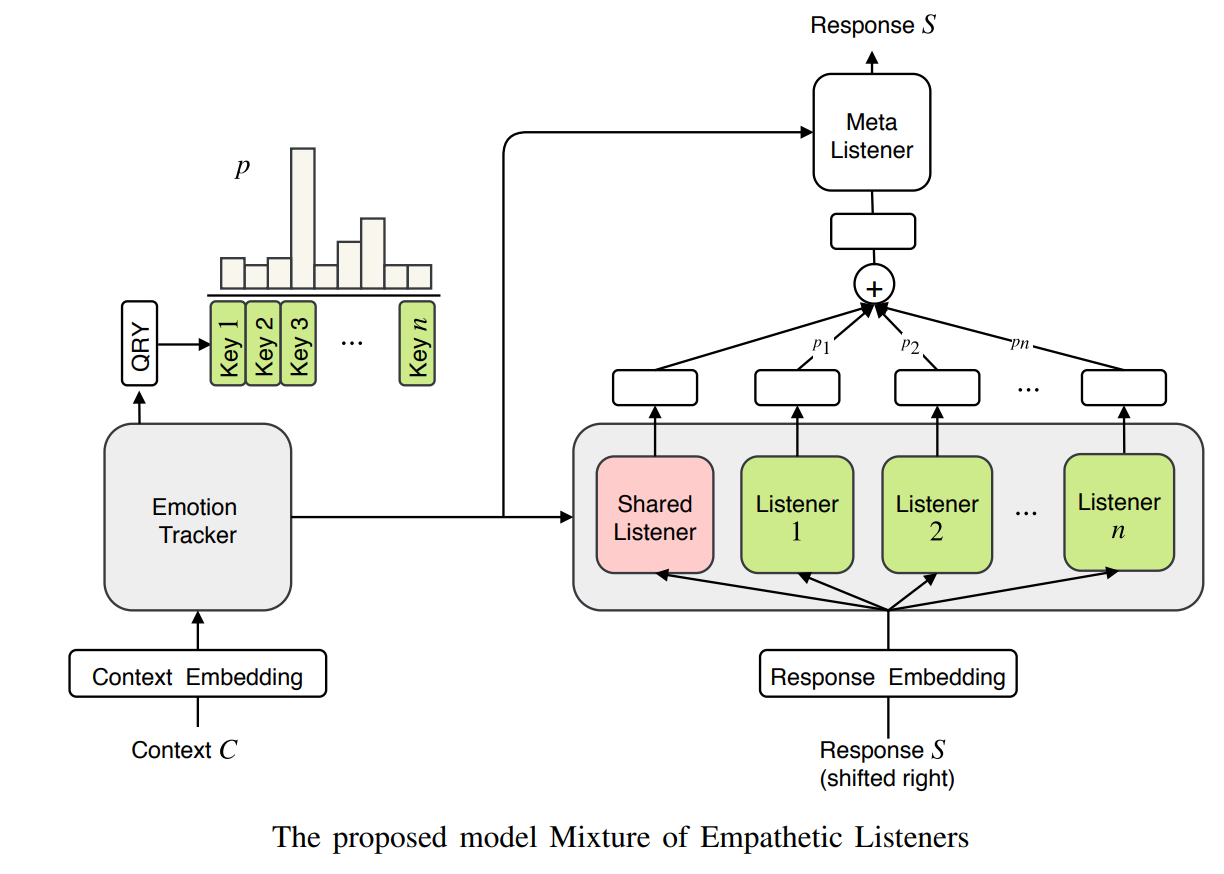
The 3-main components in this architecture are described below.
- Emotion Tracker: It is simply a standard Transformer encoder that encodes context and also computes a distribution over the possible user emotions. A query token QRY at the beginning of each input sequence, as in BERT, to compute the weighted sum of the output tensor.
- Emotion-aware Listeners: These are standard Transformer decoders that independently attend to the distribution produced by the emotional tracker and compute their own representation. There is also a shared listener that learns shared information for all emotions. The output from the shared listener is expected to be a general representation that can help the model to capture the dialogue context. But each empathetic listener learns how to respond to a particular emotion. Hence, different weights are assigned to each empathetic listener according to the user emotion distribution, while assigning a fixed weight of 1 to the shared listener.
- Meta Listener: Finally, the meta listener takes the weighted sum of representations from the listeners and generates the final response. The intuition is that each listener specializes in a certain emotion and the Meta Listener gathers the opinions generated by multiple listeners to produce the final response.
In the experiments conducted on empathetic-dialogues dataset23, MoEL shows improvements over the baseline in Empathy and Relevance, while the baseline had a higher score on Fluency.
MIME: MIMicking Emotions for Empathetic Response Generation
Mimicry is one of the key components related to empathy. Research in Psychology shows that mimicry contributes substantially to an empathic response. Sonnby-Borgstrom, 200229 proposed that mimicry enables one to automatically share and understand another’s emotions. Their proposal also receives support from studies showing a (notably, weak) correlation between the strength of the mimicry response and trait measures of empathy4. Research in neuroscience, such as Carr et al., 200330, show that the empathetic responses often mimic the emotion of the speaker.
Inspired by these ideas, Majumder et al.31, presented a proposed at EMNLP 2020 that claims to improve the MoEL research’s scores calculated on empathetic-dialogues dataset23. Their work claims that the emotions in the input text should not be treated as a flat structure where all emotions are equal. Instead, an empathetic response should mimic the emotions of a user to a varying degree. So, to improve the empathy and contextual relevance of the responses the authors introduced the following concepts: Emotion Mimicry, Emotion Grouping, and Emotion Stochastic Sampling.
-
Emotion Mimicry: As mentioned earlier, empathetic responses often mimic the emotions of the speaker to some degree. For example, positively charged utterances from the users are usually responded with positive emotions, although the response can also be somewhat ambivalent. On the other hand, responding to negatively-charged utterances often requires composite emotions that agree with the user’s emotion, but also tries to comfort them with some positivity, such as hopefulness or silver lining. This work attempts to balance the mimicry of user emotions with context.
-
Emotion Grouping: The authors split 32 emotion types into two groups containing 13 positive and 19 negative emotions.
-
Emotion Stochastic Sampling: Stochasticity is added at the emotion-group level for varied responses. This helps in avoiding generic and repetitive response generations.
Similar to Rashkin, Smith, et al. 201923, MIME uses the output of a trained emotion classifier to infuse emotion into the context representation. The classifier is trained to predict the 32 emotion labels from the Empathetic-Dialogues dataset, and also learns corresponding emotion embeddings from this data. The authors use intuitions to group these 32 emotions into 2 groups - positive and negative.
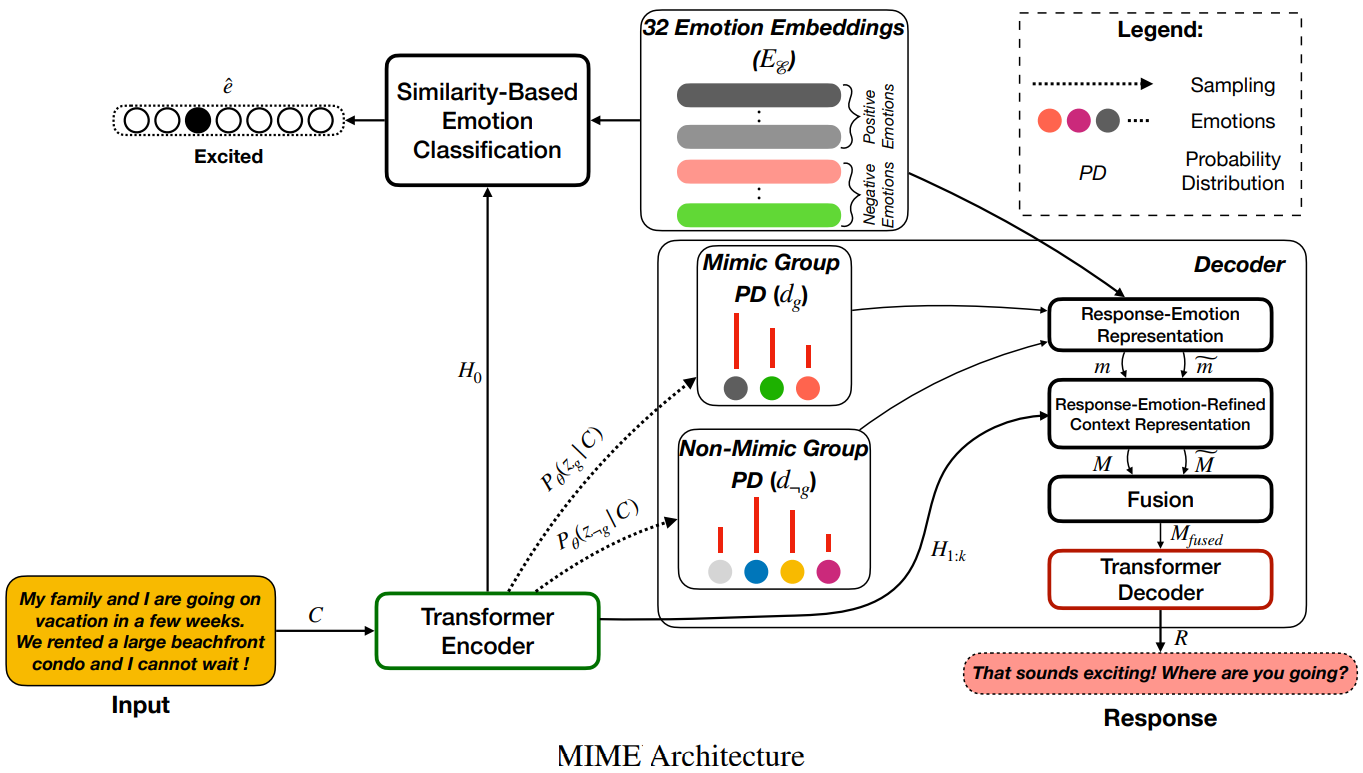
Similar to MoEL, each word is represented as a sum of three embeddings: word embedding, positional embedding, and speaker embedding. Also as in MoEL, inspired by BERT, one additional token is prepended to the context sequence to encode the entirety of the context.
A probability distribution of emotions is sampled for each of the positive and negative emotion groups that corresponds to the emotion of the response. These distributions (called response-emotion distributions) are used to create emotion representations that are then combined and balanced to create a new emotional representation that drives the emotional state during response generation using a Transformer decoder. Sampling from these two distributions achieves Emotion Stochastic Sampling, and the sampling combined with the corresponding pooled emotion embeddings enables two distinct response-emotion-refined context representations — mimicking and non-mimicking, and achieves Emotion Mimicry.
MIME showed improved empathy and Relevance scores over MoEL, which the authors attribute to appropriately mimicking the user’s emotion through stochasticity, positive/negative grouping, and sharing of emotion embeddings between classifier and decoder. However, MoEL still showed a better score on Fluency. The author hypothesizes that the drop in fluency could be because of the very structure of shared input to the decoder that is coercing the decoder to focus more on emotionally-apt tokens of the response than appropriate stop-words that have no intrinsic emotional content but lead to grammatical clarity.
Conclusion
In this article, we looked at what Empathy means from a philosophical, psychological, and neuroscience perspective. Then we did a deep dive into research on making Empathetic NLU systems. We went through several datasets and model architectures, including a peek into the current state-of-the-art systems that can generate empathetic responses in conversational dialogue systems. I hope you learned some new things from this post. And, I will love to hear your feedback in the comments below.
References
-
Einfühlung and Empathy: What do they mean?, Karal McLaren ↩︎
-
The Social Neuroscience of Empathy, Tania Singer and Claus Lamm ↩︎ ↩︎
-
Machiavellian intelligence: Social expertise and the evolution of intellect in monkeys, apes, and humans, Richard Byrne ↩︎
-
Altruism and human nature: Resolving the evolutionary paradox, Ian Vine ↩︎
-
Empathy Reconsidered: New Directions in Psychotherapy, Arthur Bohart, Leslie Greenberg ↩︎
-
Empathy and quality of care, Stewart Mercer; William Reynolds ↩︎
-
Analyzing the Language of Therapist Empathy in Motivational Interview based Psychotherapy, Xiao et al ↩︎
-
Predicting Therapist Empathy in Motivational Interviews using Language Features Inspired by Psycholinguistic Norms, Gibson et al. ↩︎
-
Identifying Empathetic Messages in Online Health Communities, Khanour et al. ↩︎
-
Modeling Empathy and Distress in Reaction to News Stories, Buechel et al. ↩︎
-
Understanding and Predicting Empathic Behavior in Counseling Therapy, Perez-Rosas et al. ↩︎
-
Zara The Supergirl: An Empathetic Personality Recognition System, Fung, Dey et al. ↩︎
-
Real-Time Speech Emotion and Sentiment Recognition for Interactive Dialogue Systems, Bertero, Siddique et al. ↩︎
-
Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory, Zhou, Huang et al. ↩︎
-
Affect-lm: A neural language model for customizable affective text generation, Ghosh et al. ↩︎
-
MojiTalk: Generating Emotional Responses at Scale, Zhou and Wang, 2018 ↩︎
-
SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks, Wang and Wan, 2018 ↩︎
-
A Simple Dual-decoder Model for Generating Response with Sentiment, Xiuyu and Yunfang, 2019; [Source Code] ↩︎ ↩︎
-
I Know The Feeling: Learning To Converse With Empathy, Rashkin, Smith et al. 2019 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Eliciting Positive Emotion through Affect-Sensitive Dialogue Response Generation: A Neural Network Approach, Lubis et al. 2018 ↩︎
-
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models, Serban et al. 2016 ↩︎
-
MoEL: Mixture of Empathetic Listeners, Lin et al., 2019; [Source Code] ↩︎
-
TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents, Wolf et al., 2019 ↩︎
-
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, Shazeer et al. (2017) ↩︎
-
Automatic mimicry reactions as related to differences in emotional empathy, Sonnby–Borgström, 2008 ↩︎
-
Neural mechanisms of empathy in humans: A relay from neural systems for imitation to limbic areas, Carr et al., 2003 ↩︎
-
MIME: MIMicking Emotions for Empathetic Response Generation, Majumder et al. 2020 [Source Code] ↩︎
Related Content





Did you find this article helpful?