How Twitter Reduced Search Indexing Latency to One Second

In June 2020, Twitter announced a major overhaul in its storage and retrieval systems. These changes allowed Twitter to reduce the search index latency from 15 seconds to 1 second.
So, what did they do to get such impressive gains? Allow me to explain!
Twitter’s Search Architecture
Designing a search system for Twitter is an incredibly complex task. Twitter has more the 145 million daily users 1 and over half a billion tweets are sent each day 2. Their search system gets hundreds of thousands of search queries per second. For any search system indexing latency is an important metric. The indexing latency can be defined as the amount of time it takes for new information (“tweets” in this case) to be available in the search index. And as you can imagine, with a large amount of data generated every day, we have an interesting engineering problem at hand.
Before we take a look at what’s new, let’s first understand how the search workflow looked like at Twitter before these changes took place. In their 2012 paper titled: “Earlybird: Real-Time Search at Twitter” 3 4, Twitter released details about its search system project codenamed “Earlybird”. With Earlybird Twitter adopted their custom implementation of Apache Lucene which was a replacement for Twitter’s earlier MySQL-indexes based search algorithm. Some of the enhancements included image/video search support, searchable IndexWriter buffer, efficient relevance based search in time sorted index etc. This enabled Twitter to launch relevance-based product features like ranked home timeline. Although the search was still limited to last x days, but they later added the support for performing archive search on SSD with vanilla Lucene, as shown by the bottom row in the diagram below.
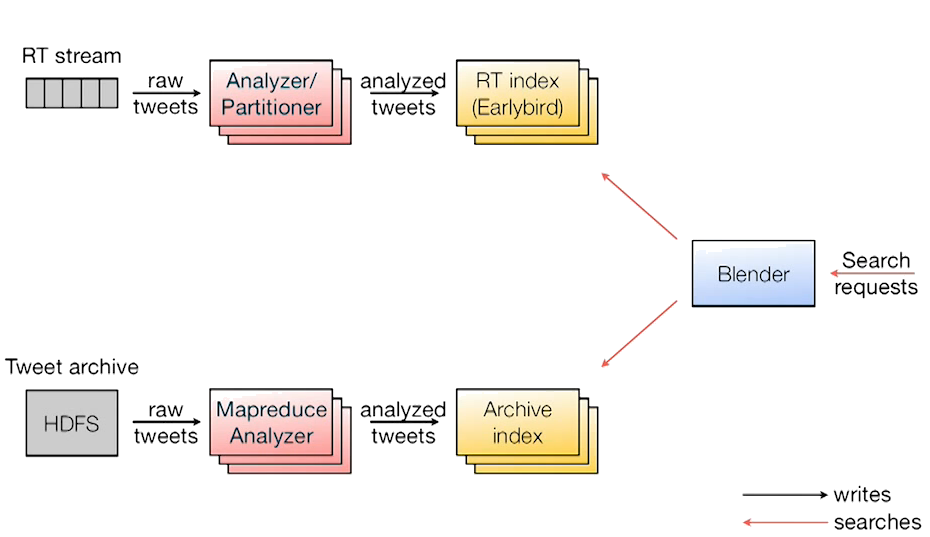
Lucene Basics
Knowing basics of Lucene helps to better understand Twitter’s implementation for their search system. Lucene is an open-source search engine library that is completely written in Java and is used by tech companies like LinkedIn, Twitter, Slack, Evernote etc. As you can imagine, we can’t afford to search record-by-record on large data specially for a time-sensitive application, we use a Lucene like solution that provides us Inverted Indexes. In information retrieval terminologies, a string is called a “term” (for example, English words), a sequence of terms is called a “field” (for example, sentences), a sequence of fields is called a document (for example, tweets), and a sequence of documents is called an index 5.
Following is an example of inverted index creation, taken from “Inverted files for text search engines” research paper 6
| document id | document text |
|---|---|
| 1 | The old night keeper keeps the keep in the town |
| 2 | In the big old house in the big old gown |
| 3 | The house in the town had the big old keep |
| 4 | Where the old night keeper never did sleep |
| 5 | The night keeper keeps the keep in the night |
| 6 | And keeps in the dark and sleeps in the night |
| term | freq | inverted list for t |
|---|---|
| and | 1 | <6> |
| big | 2 | <2>, <3> |
| dark | 1 | <6> |
| did | 1 | <4> |
| gown | 1 | <2> |
| had | 1 | <3> |
| house | 2 | <2>, <3> |
| in | 5 | <1>, <2>, <3>, <5>, <6> |
| keep | 3 | <1>, <3>, <5> |
| keeper | 3 | <1>, <4>, <5> |
| keeps | 3 | <1>, <5>, <6> |
| light | 1 | <6> |
| never | 1 | <4> |
| night |3 | <1>, <4>, <5> |
| old | 4 | <1>, <2>, <3>, <4> |
| sleep | 1 | <4> |
| sleeps | 1 | <6> |
| the | 6 | <1>, <2>, <3>, <4>, <5>, <6> |
| town | 2 | <1>, <3> |
| where | 1 | <4> |
You can use the above inverted index to answer questions like “Which documents have the word house in them?” Also, note that a term or a document could also be a single word, a conjunction, a phrase or a number. Each row of this index above, maps a term to a Posting List. In real implementations, the posting list may also include additional information, such as the position (index) of the term in the document or some other application-specific payload.
Changes in Ingestion Pipeline
Let’s get back to Twitter’s ingestion pipeline, which used to look like this:

Fix: Twitter decided to stop waiting for the delayed fields to become available by adding an asynchronous part to their ingestion pipeline.
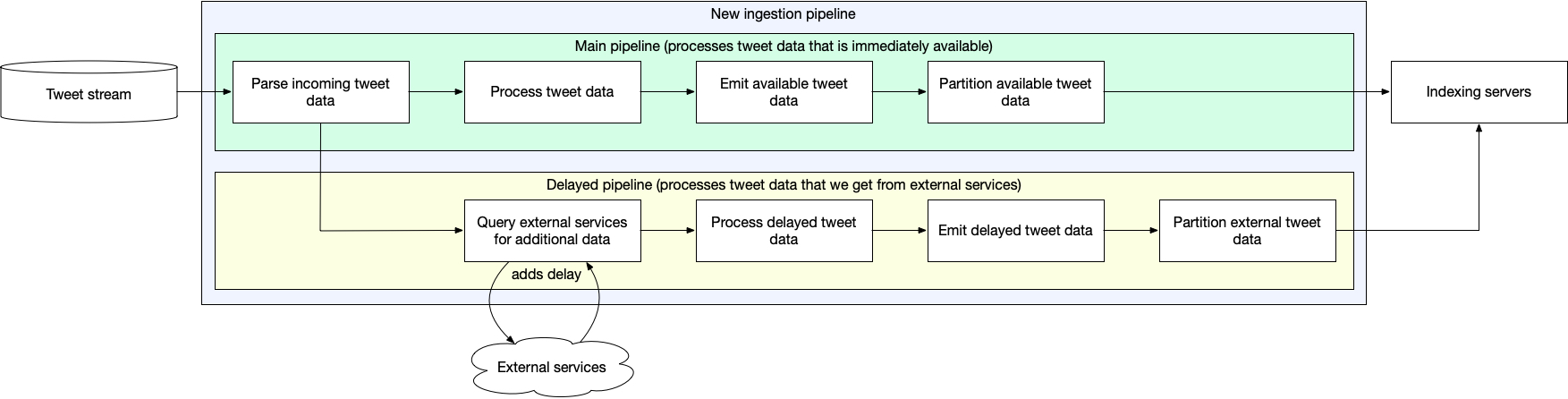
Now most of the data will be sent to indexing system as soon as the Tweet is posted. Another update will be sent once the additional information is available. Even though the indexing service doesn’t have full information at the beginning, at least for search system we have enough information to fetch results.
Changes in Data Structures and Algorithms
Eliminating Sorting Step
Lucene’s vanilla implementation stored document ids using delta encoding, such that the key at an index depends on the previous index. Also, the document ids were generated starting from 0 up to the size of the segment storing those documents (a segment is just a “committed” i.e. immutable index). This essentially meant that the search could only be performed from left to right, i.e. from the oldest tweet to latest tweet. However, like many other products at Twitter, search is also designed to prioritize recent tweets over the older ones. So, twitter decided to customize this implementation in Earlybird.
Earlybird diverged from standard Lucene approach and allocated document ids to incoming tweet from high value to low value, i.e. from the {size of the index - 1} to 0. This lets searching algorithm to traverse from latest tweet to oldest tweet and with the possibility of returning early if a client-specified number of hits have been recorded.
FIx: Twitter changed it’s ID assignment scheme such that each tweet is given a document ID based on its time of creation. They fit the document id to 31 bits (positive Java Integer), such that 27 bits store the timestamp with microseconds granularity. The rest 4 bits are used as a counter for the all of the tweets received at the same microsecond. Although the probability of such \( 2^4\) events is rare, but all tweets after 16, that are created at the same microsecond precision, would be assigned to the next segment, and would appear slightly out of order in search results, if selected. This means that Twitter can eliminate the need for explicit sorting step and reduce latency even further.
Optimizing Operations on Posting Lists
For their posting list implementation, Twitter had been using Unrolled Linked Lists.
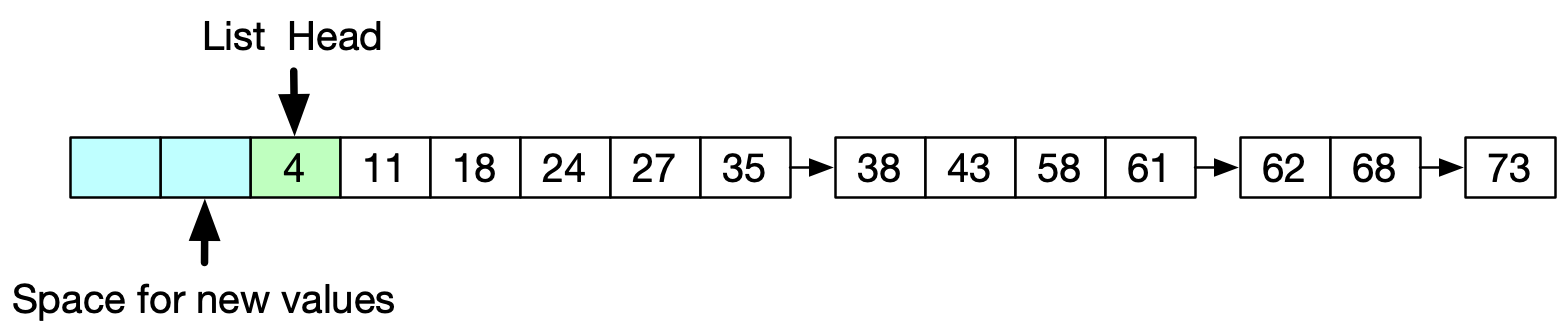
This implementation had only one writer thread and multiple searcher threads (one per CPU core, with tens of thousands of cores per server) without any locks. Writing would be done only at the head of the list, and the searcher would search starting from the new head pointer or the older head (still, valid) pointer to the end of the list. (notice in the figure above how document id assignment is done from high value to low value. )
Unrolled linked lists are cache friendly data structures that also reduce some of the overhead of storing pointer references. However, we can’t use them to cost-effectively insert at arbitrary location in the list, they also depend largely upon the assumption that the input will be strictly ordered.
Fix: Twitter decided to opt for Skip Lists as the replacement for unrolled linked lists. Skip Lists allow for O(\( \log{n}\)) search and insertions, and also support concurrency. I wrote an introductory article on Skip Lists here. I highly recommend you to read through the article to better understand the concept behind Skip Lists.
Twitter’s Skip List implementation
Skip Lists are probabilistic data structures, such that after inserting a new node at list \( L_{i} \), we insert the node at the layer \( L_{i+1}\) with some probability. Twitter’s found 20% ( \( \frac{1}{5}\) ) is a good tradeoff between space and time complexity (memory used vs. speed).
In their implementation, Twitter used several optimizations. The implemented the Skip List in a single flat array, such that the “next” pointer becomes just an index into the array.
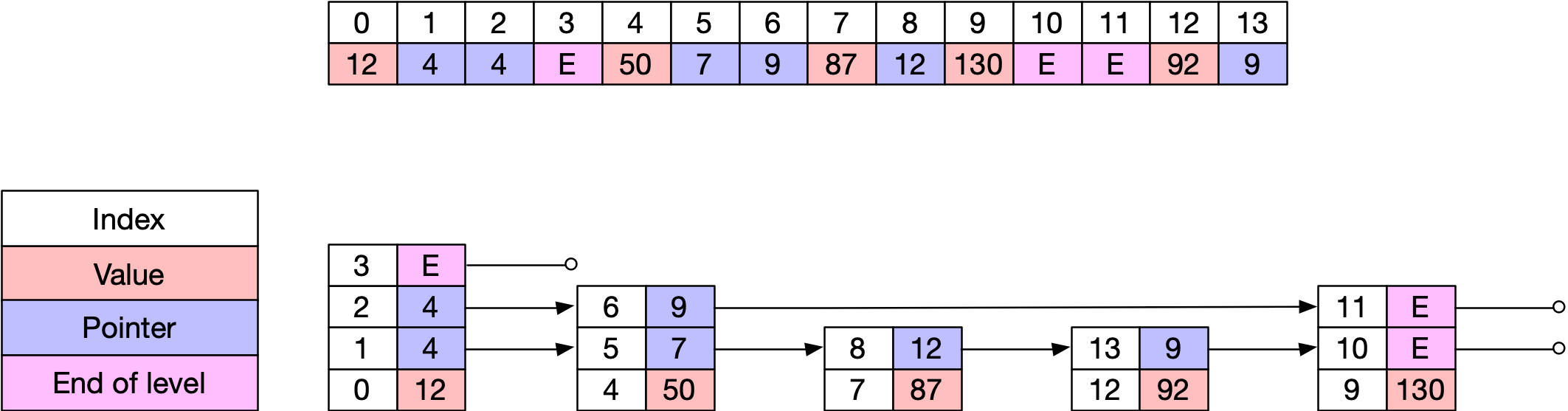
Here’s a breakdown of the other optimizations in their Skip List:
- Insertion would simply append the new value at the end of the array, and the corresponding pointer will be updated appropriately after traversing the Skip List. New values at the higher levels will be added with a 20% probability.
- At every search operation, the descent down the different levels is recorded and saved as a “search finger”. This helps in lookups when we are finding a document with id greater than the one for which we already have the search finger. It reduces the lookup time complexity from O(\( \log{n} \)) to O(\( \log{d} \)), where n is the number of items in the posting list and d is the number of items in the list between the first value and the second value, in case of conjunction search queries.
- Using primitive array also has an advantage of reducing pointer management overheads, such as garbage collection.
- Allocating vertical levels of Skip List in adjacent location, eliminates the need for storing “above” and “below” pointers.
One obvious disadvantage, however, is that the Skip Lists are not cache friendly. However, being able to run in logarithmic time in case of sparse documents is a big advantage.
Additional Details
- Twitter’s new Skip List implementation also uses a “published pointer” that points to the current maximum pointer into array such that searchers never traverse beyond this pointer. This allows for ensuring atomicity in search and retrievals, and a document is searched only if all of its terms are indexed.
- Considering this was a change of large magnitude, Twitter rolled it out gradually by first evaluating the results in Dark Launch mode. This was done to ensure that the clients do not have any reliance or assumptions on the earlier 15 seconds delay in search indexing.
Conclusion
In order to reduce search indexing latency, Twitter made big changes to its storage system and retrieval system. They shared their approach and learnings in a whitepaper 7 that I summarized here. The search indexing improvement from 15 seconds to 1 second means that the new content should be available for Twitter users to access almost instantaneously.
Related Content



Did you find this article helpful?