Self-Supervised Contrastive Approaches for Video Representation Learning

Need for self-supervised learning
Supervised deep learning approaches have shown remarkable success in various domains, such as Computer Vision. With the advent of big data, some of these approaches have lagged as the amount of labeled data is often minuscule compared to large-scale unlabeled data, like text, photos, and videos. To address this challenge, a number of algorithms have been proposed in the self-supervised domain that learn robust representations without any labels.
A common approach to training such models is to learn a pretext task, which is solved only for the purpose of learning effective data representations to be used in downstream tasks. Some of the pretext tasks for learning image representations include predicting the rotation of images, relative positions or tracking of patches in an image, image colorization, solving jigsaw puzzles, and counting visual primitives.
Pretext tasks for video representation learning are more complex due to the presence of temporal dimensions. Some of the pretext tasks in the video domain include predicting future frames or the correct order of shuffled frames, shuffled clips, video rotations, motion and appearance statistics, tracking patches, objects, pixels, etc. These approaches have achieved great performance in learning image/video representations. However, they do not perform competitively with supervised methods because some of these tasks can be trivially solved through learned shortcuts.
The emergence of contrastive learning
Contrastive learning is one of the categories of the self-supervised learning paradigm. These methods learn a latent space that draws positive samples together (e.g. frames from the same video) while pushing part negative samples (e.g. frames from different videos). Various contrastive learning algorithms usually differ in the way they define positive and negative samples. For example, algorithms could use multiple augmented views of the same image, clustering methods to find semantically similar examples, sub-clips of the same or different lengths from the same video, etc. In some cases, these methods can also work without explicit negatives1. In video representation learning, contrastive methods could use pretext tasks such as pace prediction, clip shuffling, etc.
A lot of recent approaches use a variant of contrastive learning called Instance Discrimination to further close the gap with supervised learning methods. These approaches include data augmentation, contrastive losses, momentum encoders2, and memory banks3. Data augmentation is commonly used by several image-based methods like SimCLR4 to generate positive samples. For example, random image transformations, like random crops, can be applied to an image to obtain multiple views of the same image, which are assumed to be positives. The downside of using such a transformation is that the onus of generalization lies heavily on the data augmentation pipeline which can not cover all possible variances5.
InfoNCE is one of the most commonly used contrastive loss functions. Given an embedded video $z$ and corresponding positive embedded video $k^+$ (for example, a random augmentation of $z$) and many negative embedded videos $k^- \in \mathcal{N}_i$ respectively, infoNCE loss is defined as:
$$ \mathcal{L}^{\text{InfoNCE}} = -\log \frac{\exp(z_i \cdot z_i^+ / \tau)}{\exp(z_i \cdot z_i^+ / \tau) + \sum\limits_{z^- \in \mathcal{N}_i} \exp(z_i \cdot z^- / \tau)} $$
where $\tau$ is the temperature hyperparameter. Similarity among the positive $(z_{i}, z_{i}^+)$ and negative $(z_i, z^-)$ pair is usually defined as dot product (cosine distance) and the embedded vectors are usually $\ell_2$-normalized.
Contrastive learning from unlabeled videos
Google’s Contrastive Video Representation Learning (CVRL)
In the CVRL paper6, researchers at Google built a framework to promote spatial self-supervision signals in videos. They noted that since both spatial and temporal information is crucial for learning video representation, only applying spatial augmentation independent of video frames breaks the natural motion along the time dimension.
Instead, they recommended a temporally consistent spatial augmentation method by fixing the randomness across frames. They hypothesized that a pair of positive clips (taken from the same video) that are temporally distant, may contain very different visual content, leading to a low similarity that will be indistinguishable from negative pairs. At the same time, disregarding timewise distant clips reduces the temporal augmentation effect.
So their recommended sampling method ensured that the time difference between two positive clips, sampled from the same input video, follows a monotonically decreasing distribution. Effectively, temporally close clips are a much stronger basis for learning as compared to distant clips. It also ensures that the model doesn’t learn temporally invariant features, which is the problem with previous temporal augmentation techniques like sorting video frames or clips, altering playback rates, etc.
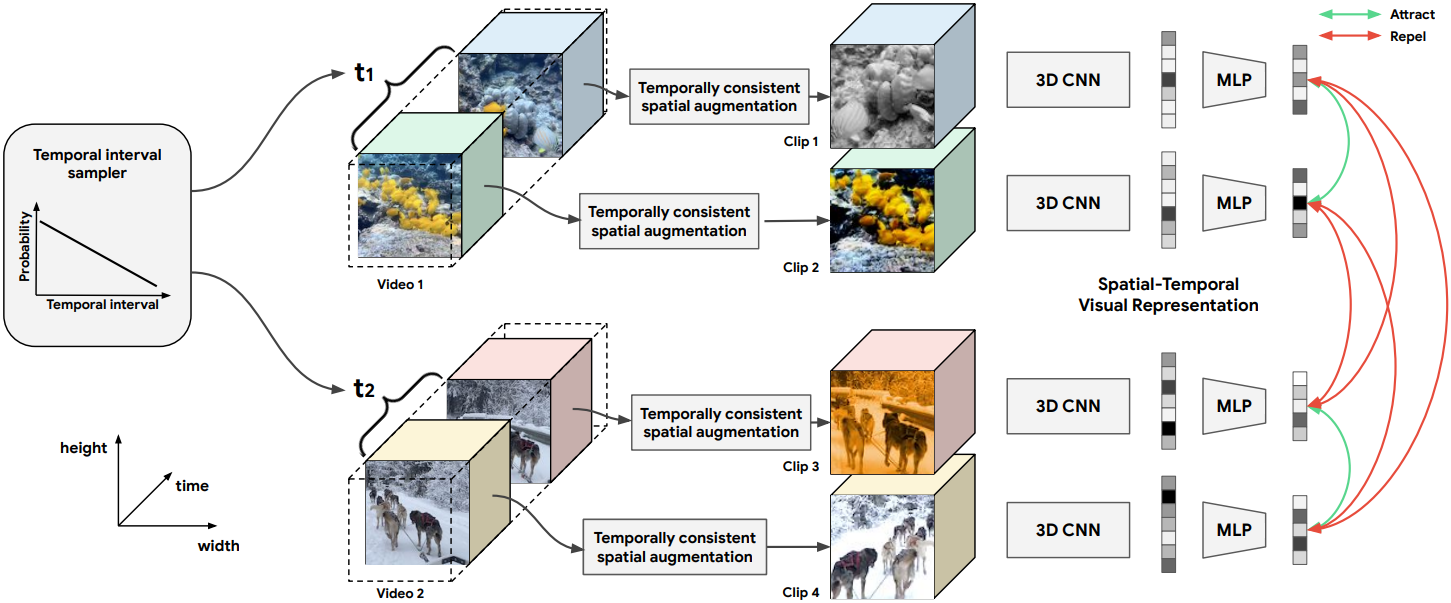
These sampled clips are then spatially augmented. Previous spatial augmentation techniques like random cropping, color jittering, and blurring break the motion cues across frames that negatively affect the representation learning along the temporal dimension. To address this, the authors designed the following algorithm that makes the spatial augmentation consistent along the temporal dimension.

Following this, a video encoder maps the input video clip to a 2048-dimensional latent representation using 3D-ResNets as backbones. This network is a minor modification (different stride and kernel size) of the “slow” pathway of the SlowFast network7. An MLP layer further reduces this representation to a 128-dimensional feature vector that is used to compute InfoNCE loss. As per the standard convention, the MLP is discarded during evaluation. Their representations outperformed all existing baselines for self-supervised learning and they also showed that the CVRL framework benefits from larger datasets and larger networks. The official TensorFlow implementation of CVRL is available on GitHub.
Facebook’s $\rho$-Momentum Contrast ($\rho$-MoCo)
Facebook AI Research (FAIR) proposed a simple method to learn video representations that generalized existing image-based frameworks to space-time. The authors argue that visual content is often temporally-persistent along a timespan in a given video. For example, persistency may involve a person dancing, transitioning from running to walking, etc. covering short to long spans, with different levels of visual invariance. Hence they use an encoder to produce embeddings that are persistent in space-time, over multiple ($\rho$) temporally distant clips of the same video. Their experiments showed that it is beneficial to sample positives with longer timespans between them.
The authors used an encoder design that is similar to Google’s CVRL, i.e. a 3D ResNet-50 ConvNet without temporal pooling in convolutional feature maps, followed by an MLP projection head. For their experiments, they used 2 contrastive approaches which use both positive and negative samples: SimCLR and MoCo, and 2 other methods that only use positive samples: BYOL and SwAV. The original objective of these methods was to learn invariant features for images across different views (augmentations). The authors extended this objective to the temporal domain for videos.
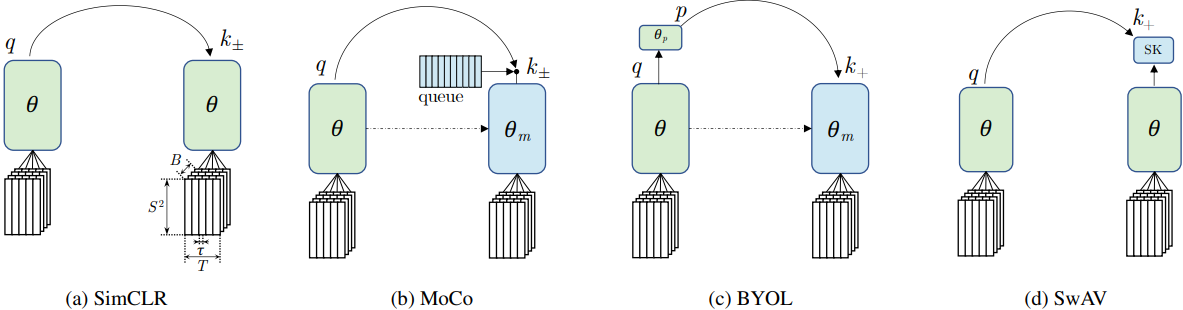
SimCLR uses the in-batch negative embeddings of other videos, while MoCo maintains a queue that stores embeddings from previous iterations to fetch negatives. BYOL can be thought of as a form of MoCo without the negative samples but with an extra predictor MLP ($\theta_p$ in the figure), whereas SwAV can be viewed as a form of SimCLR without the negative samples that also has Sinkhorn-Knopp (SK) transformation step for the targets. Through an extensive set of experiments, the authors share the following findings:
- The long-spanned persistency can be effective even if the timespan between positives is up to 60 seconds. Beyond that the positive pair might no longer share the same semantic context for learning high-level features corresponding in time, hence the corresponding representations might not be beneficial for downstream tasks.
- There was no performance difference between contrastive and non-contrastive methods.
- Multiple samples ($\rho$) from the same clip are beneficial to achieve high accuracy, with the best results achieved at $\rho = 4$.
- While MoCo performed the best for uncurated videos, BYOL and SimCLR showed better performance for short videos (10-16 seconds).
- Methods that used momentum encoders (like MoCo, BYOL) tend to do better than the methods with contrastive objectives (SimCLR, SwAV).
Amazon’s Inter-Intra Video Contrastive Learning (IIVCL)
The authors of Nearest-Neighbor Contrastive Learning of Visual Representations (NNCLR)5 proposed a nearest-neighbor-based approach to sampling the nearest neighbor as a positive sample for images. The authors of IIVCL8 extended this idea to the video domain to provision extra positive samples in addition to the previous CVRL and $\rho$-MoCo models’ approach of fetching two positive clips from the same video. The authors argue that by only considering clips from the same video to be positive, the previous methods neglect other semantically related videos that may also be useful and relevant as positives for contrastive learning. For example: in the following samples clip A and B are from the same skiing video, hence they are positives, while video 2 and video 3 are negatives for both. But this assumption ignores the fact that video 3 (snowboarding) is more similar to video 1 (skiing) than video 2 (push-ups).

Hence there is a need to look beyond just the local intra-video similarities and consider global inter-video similarities as well. This ensures additional diversity in viewpoint and scene orientation that cannot be expressed through sampling sub-clips from the same video. And, it also makes it possible to learn from weaker yet relevant and useful positive pairs. However, only using global inter-video semantics will lead to losing granular details that are also important for video understanding. So an effective approach must use both local and global similarities. To achieve this, IIVCL creates a dynamically evolving queue from which the most similar videos (nearest neighbors) are found. Note that the intra-video clips are randomly sampled and there is no temporal ordering among them.
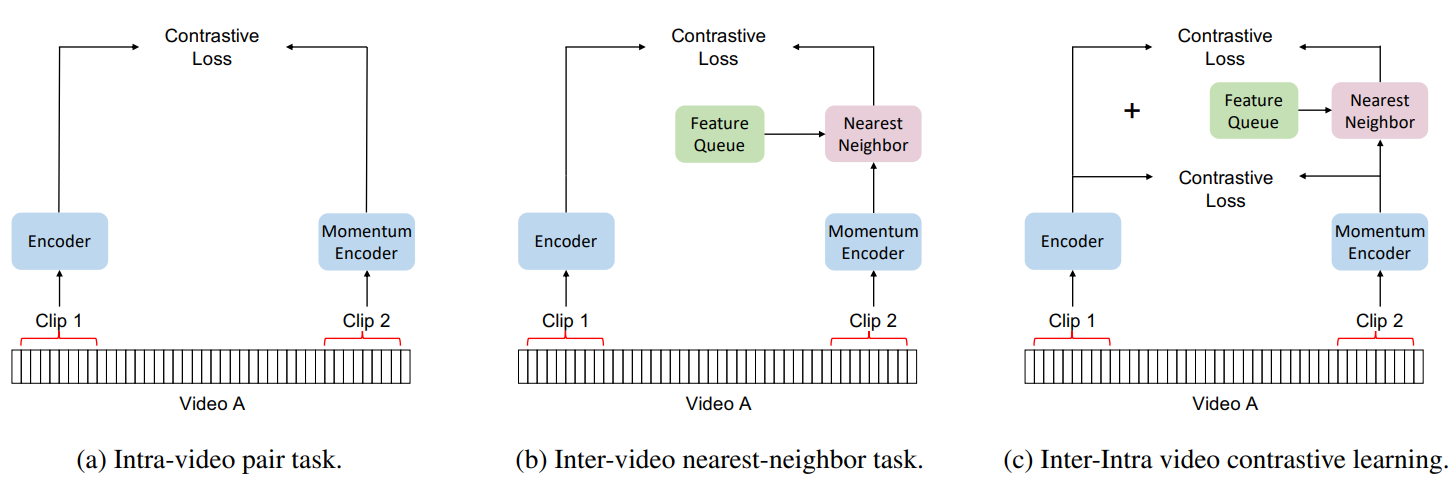
As contrastive learning requires large batch sizes and computing video embeddings can be very expensive, the FIFO-style queue is updated with embeddings from a momentum encoder. The queue is updated at the end of each training setup (forward pass) by taking the n (batch size) embeddings from the current training step and inserting them into the end of the queue. The nearest neighbors are calculated from this queue by calculating the cosine similarities between the input video and the queue. Over the course of pretraining, the model continually evolves its notion of semantic similarity and becomes better at picking semantically similar nearest-neighbor clips. Hence, no clustering or separate training is required to get the global support set. Separate MLP projection heads are used to process the intra-video and nearest-neighbor positive pairs. Both of these pretext tasks are then combined using a multi-task loss. Similar to other methods, the trained model is evaluated using linear evaluation and fine-tuning protocols.
Summary
Advances in self-supervised learning have enabled the utilization of large-scale unlabeled data. Contrastive learning methods have further helped to reduce the performance gap between self-supervised and supervised methods. This article summarized some of the most popular ways to apply contrastive methods for effective representation learning for videos. These algorithms proposed different ways to address the spatial and temporal information in video data to achieve state-of-the-art performance for representation learning.
References
-
Grill, J., Strub, F., Altch’e, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Doersch, C., Pires, B.Á., Guo, Z.D., Azar, M.G., Piot, B., Kavukcuoglu, K., Munos, R., & Valko, M. (2020). Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. ArXiv, abs/2006.07733. ↩︎
-
He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R.B. (2019). Momentum Contrast for Unsupervised Visual Representation Learning. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 9726-9735. ↩︎
-
Wu, Z., Xiong, Y., Yu, S.X., & Lin, D. (2018). Unsupervised Feature Learning via Non-parametric Instance Discrimination. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3733-3742. ↩︎
-
Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). A Simple Framework for Contrastive Learning of Visual Representations. ArXiv. /abs/2002.05709 ↩︎
-
Dwibedi, D., Aytar, Y., Tompson, J., Sermanet, P., & Zisserman, A. (2021). With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations. ArXiv. /abs/2104.14548 ↩︎ ↩︎
-
Qian, R., Meng, T., Gong, B., Yang, M., Wang, H., Belongie, S.J., & Cui, Y. (2020). Spatiotemporal Contrastive Video Representation Learning. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 6960-6970. ↩︎
-
Feichtenhofer, C., Fan, H., Malik, J., & He, K. (2018). SlowFast Networks for Video Recognition. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 6201-6210. ↩︎
-
Fan, D., Yang, D., Li, X., Bhat, V., & Rohith, M.V. (2023). Nearest-Neighbor Inter-Intra Contrastive Learning from Unlabeled Videos. ArXiv, abs/2303.07317. ↩︎
Related Content





Did you find this article helpful?