Mixture-of-Experts based Recommender Systems

The Mixture-of-Experts (MoE) is a classical ensemble learning technique originally proposed by Jacobs et. al1 in 1991. MoEs have the capability to substantially scale up the model capacity and only introduce small computation overhead. This ability combined with recent innovations in the deep learning domain has led to the wide-scale adoption of MoEs in healthcare, finance, pattern recognition, etc. They have been successfully utilized in large-scale applications such as Large Language Modeling (LLM), Machine Translation, and Recommendations. This article gives an introduction to Mixture-of-Experts and some of the most important enhancements made to the original MoE proposal. Then we look at how MoEs have been adapted to compute recommendations by looking at examples of such systems in production.
Introduction to Mixture-of-Experts (MoE)
Generally speaking, MoE architecture is an ensemble of many models (aka experts). We train a number of these experts, each of which can be trained on a subspace of the problem, and then specialize in that specific part of the input space. The underlying assumption is that our data comes from different regimes. Many datasets can be naturally divided into categories that correspond to different subtasks. For example: in financial data, the state of the economy has a big effect on mapping inputs to outputs. So you might want different models for different states of the economy.
Each of the experts can be any machine learning algorithm such as an SVM, HMM, a small neural network, or even just a simple matrix multiplication. These experts often have the same architecture and are also trained by the same algorithm. Additionally, MoEs include a gating (or routing) function that acts as a manager that forwards individual inputs to the best experts based on their specialization.
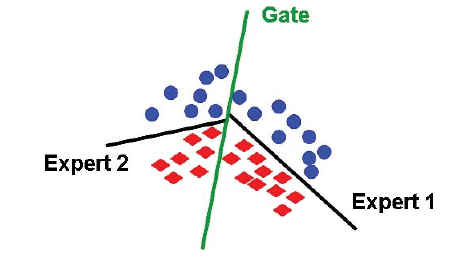
In the classification example shown above, the blue circles and red diamonds correspond to two different classes. The gate does a soft partition of the input space and defines the regions where the individual experts are trustworthy. For example, Expert 1 is responsible for the left of the gating line, whereas Expert 2’s opinion is considered for the data points to the right of it. This approach simplifies a non-linear classification problem into two linear classification problems2.
This divide-and-conquer approach to problem-solving also underlies many other predictive modeling ensembles, like Boosting methods. However, all the trained models in Boosting are given some weightage regardless of the current input we are dealing with, so the result will be combined from all models. On the other hand, the routing scheme in MoE only incurs computational cost corresponding to the selected experts. Hence MoEs enable a paradigm called Conditional Computation and perform effectively when there is a large amount of training data. Also, because the input is fractionated, MoE models often do not perform well with small datasets.
Make experts complete, not cooperate
Training a single, multilayer network to perform different subtasks on different occasions can lead to strong interference effects that lead to slow learning and poor generalization. If the number of subtasks is known prior to training, one option, for example, is to make the final output of the whole system to be a linear combination of the outputs of the local experts, each given their own proportional weights. So, the error value on case c can be calculated as:
$$ E^c = || y^c - \sum_{i} w_i^c o_i^c ||^2 $$
where $o_i^c$ is the output vector of $i$th expert and $w_i^c$ is the proportional contribution of expert $i$, and $y^c$ is the desired output. Note that the CART algorithm uses a similar approach. One problem with such an error measure is that it encourages cooperation as there is a strong coupling between the experts. Each local expert will have to make its output cancel the residual error that is left by the combined effect of other experts. And, if the weight of one expert changes, the residual error changes, and the error derivatives for all other local experts also change.
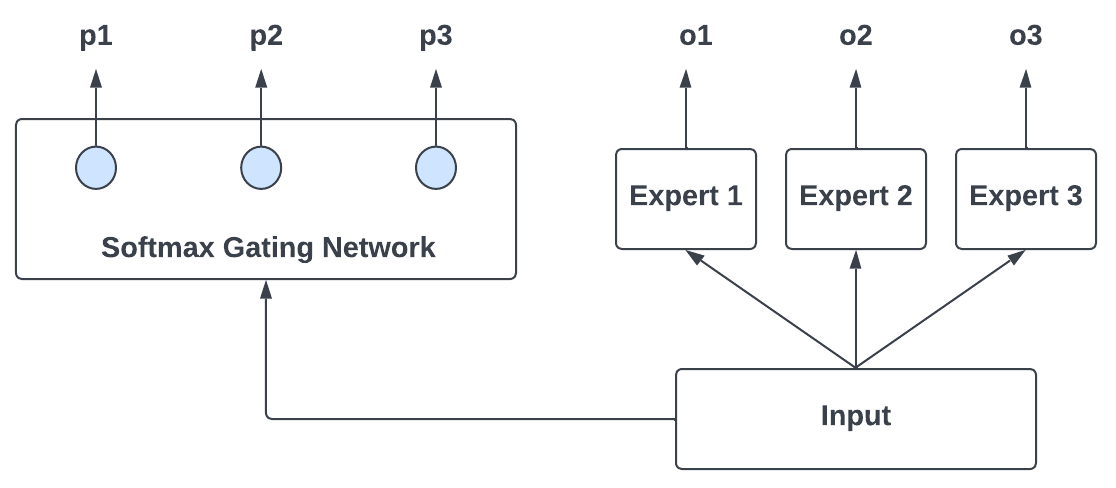
The interference can be reduced by using a system composed of several different “expert” networks plus a gating network that decides which of the experts should be used for each training case. Instead of using a linear combination of experts, we can use a manager layer (aka a gating network) that makes a stochastic decision about which single expert to use for specific input. The gating network allows the mixing proportions of the experts to be determined by the input vector. This gives us a system of competing local experts where each expert is required to produce the whole of the output vector rather than a residual effectively making the experts independent of each other.
$$ E^c = || y^c - o_i^c ||^2 = \sum_{i} p_i^c || y^c - o_i^c ||^2 $$
Here $p_i^c$ represents the probability that the gating network will select the output from the expert $i$ for an input $c$. If an expert gives less error than the weighted average of all experts, its responsibility for that case will be increased. There is still some indirect coupling because if some other expert changes its weights, it may cause the gating network to alter the responsibilities that get assigned to the experts, but at least these responsibility changes cannot alter the sign of the error that a local expert senses on a given training case.
The authors of MoE paper proposed to further optimize the above error function to a negative log probability of generating the desired output vector under the mixture of Gaussian model1.
$$ E^c = - \log{ \sum_i p_i^c e^{- \frac{1}{2} || y^c - o_i^c || }} $$
Advantages of MoE
- MoEs are can be flexibly combined with different models. For example, when combined with SVMs they can allocate different kernel functions to different input regions, which is not possible with vanilla SVMs.
- They find the subsets of patterns that naturally exist within the data. This makes MoEs a great choice for problems that contain non-stationary, piecewise continuous data and datasets that contain a naturally distinctive subset of patterns.
- The divide-and-conquer strategy used by MoEs allows for building larger networks that are still cheap to compute at test time, and more parallelizable at training time3.
- Empirical studies show that the MoE model does not collapse into a single model4.
Problems with MoE
- At the beginning of the training, all experts are randomly initialized, have the same network, and are trained by the same algorithm. This makes it hard for the gating network to learn the right features because all the experts look the same. Hence the gating mistakes get amplified.
- The gating network can converge to a state where it relies heavily on a specific set of experts. This problems is called the expert load imbalance during training and it can lead to performance issues. Some researchers have suggested adding a load imbalance loss value to mitigate this problem5.
MoE Variants
Since their inception over 30 years ago, MoEs have been revised many times and several improvements have been proposed. This section highlights a few of them.
Hierarchical Mixture of Experts
The Hierarchical Mixture-of-Experts (HME) algorithm proposed by Jordan et. al6 takes a recursive approach to decompose the predictive modeling task. During MoE training, the gate and expert parameters are decoupled and estimated separately. This modularity led to the development of HMEs. HME learns a hierarchy of gating networks in a tree structure, such that the output is conditioned on multiple levels of gating functions. The outputs are then mixed according to the gating weights at each node.
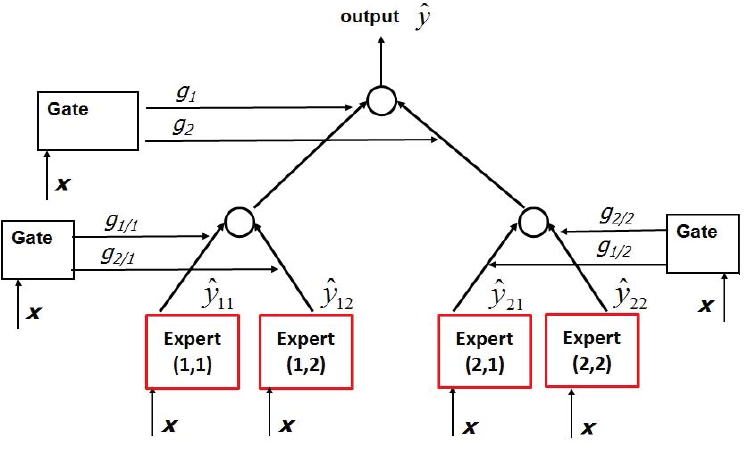
The above example shows a two-level HME architecture with two MoE components at the bottom, each consisting of a single gate and two experts. Compared to the CART algorithm’s greedy approach, splits in HME are probabilistic functions. So HME can also be thought of as a statistical approach to decision tree modeling that has the capability of recovering from a poor decision somewhere further up the tree.
Deep Mixture of Experts
Eigen et. al7 proposed a Deep Mixture of Experts (DMoE) model that stacks MoEs such that a suitable expert combination is dynamically assembled for a given input. DMoE uses multiple sets of gating and experts to exponentially increase the number of effective paths, yet maintains a modest model size by associating each input with a subset of experts at each layer.
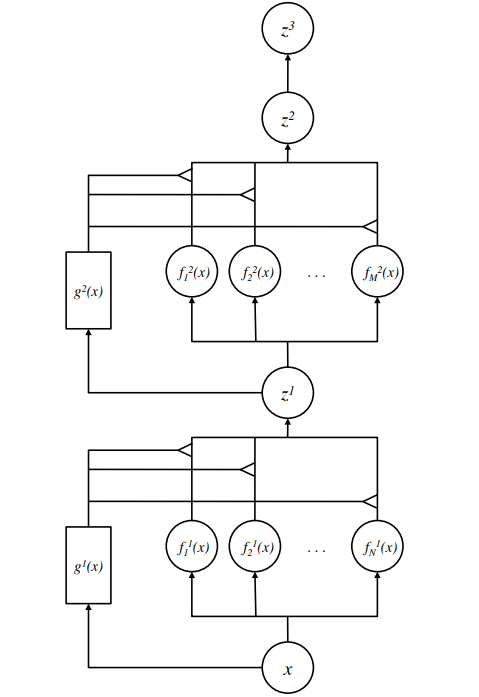
The above example shows a DMoE with two sets of experts with gating networks. It dynamically computes a suitable expert combination by conditioning the experts and gating networks on the output of the previous layers. To ensure that the experts at the first layer do not overpower the remaining experts, the authors propose an explicit constraint on relative gating assignments applied temporarily during training.
Sparsely-gated Mixture of Experts
One of the most influential improvements to MoEs was proposed by Shazeer et. al5 which offered a dramatic increase in model capacity without a proportional increase in computation. Their Sparsely-gated Mixture-of-Experts model can achieve more than 1000x improvement in model capacity while incurring only a minor loss in computational efficiency. While scaling a traditional deep learning model costs a significant amount of compute because the entire model is activated for every example, the gating method proposed in this paper selects a sparse combination of experts to process each input. Before taking the softmax in a standard gating network, they add a tunable Gaussian noise, and then keep only the top-k values, setting the rest to $-\infty$ (making the corresponding gate outputs to be 0).
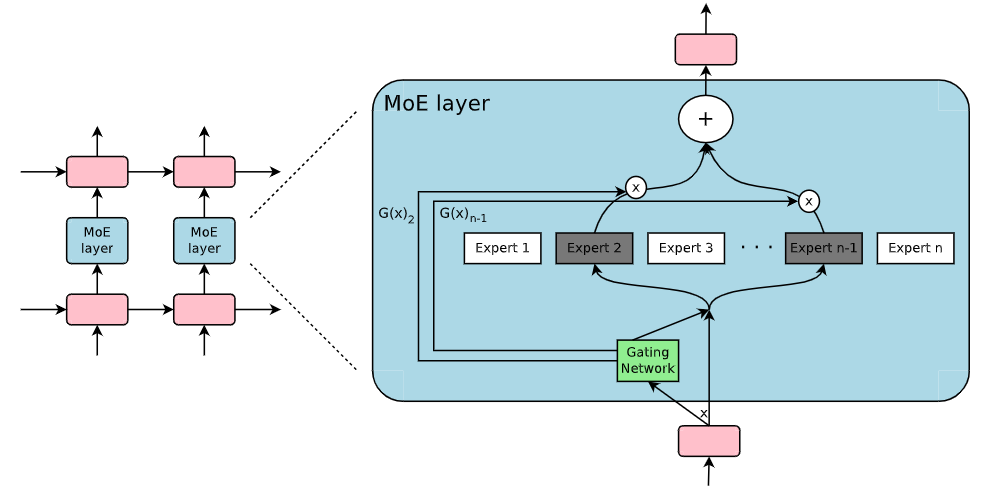
The above example shows their proposed MoE layer embedded within a recurrent model. The sparse gating function in the example has selected two experts to perform computations. They trained the model on language modeling and machine translation tasks and show that different experts tend to become highly specialized based on input syntax and semantics. The paper also proposes parallelism techniques for increasing batch sizes and additional loss terms to balance the utilization of experts.
Some recent studies show that using sparsely-gated MoEs for Large Language Modeling (LLM) can lead to similar performance as achieved by a dense model that requires four times as much compute8. Meta also used the sparsely-gated MoE technique for its No Language Left Behind (NLLB-200) model that provides translation capability for low-resource languages with relatively little data9.
Multi-gate Mixture-of-Experts
In Multi-gate Mixture-of-Experts (MMoE), Ma el. al10 adapted the MoE structure to multi-task learning. The goal of multi-task learning is to build a single model that learns multiple tasks simultaneously. The authors hypothesize that such learning is sensitive to the differences in data distributions and the relationship between tasks. Such factors can affect a model’s performance especially when model parameters are shared among the tasks.
They propose a novel approach that is based on MoEs and explicitly models task relationships along with learning task-specific functionalities. In their architecture, the expert submodels (feed-forward networks) are shared across all tasks, while the gating networks are task-specific. Each task also has a task-specific “tower” to decouple the optimization for tasks. The key idea here is that the commonly used shared-bottom model structure is replaced by MoEs.
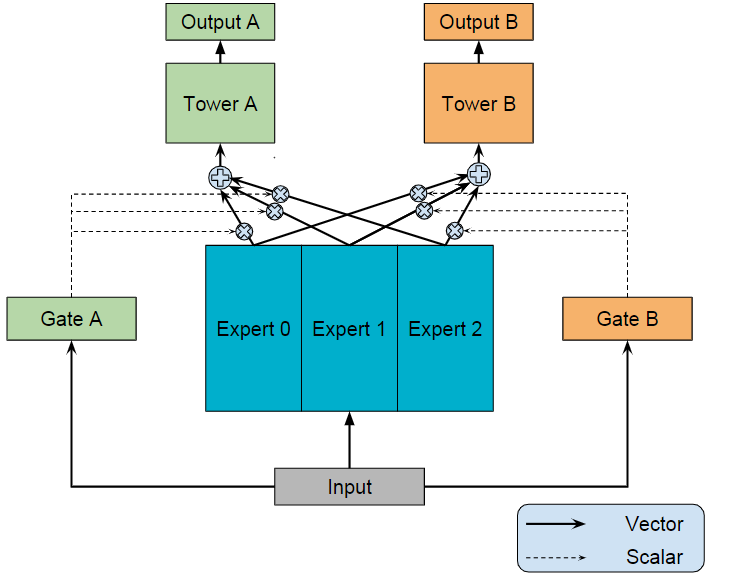
The above example shows an MMoE architecture for two tasks. Their gating networks allow different tasks to utilize different experts differently. Through experiments, the authors show that MMoE architecture outperforms baseline methods, especially when the correlation among tasks is low. The authors test MMoEs in large-scale recommender systems at Google by training a ranking model optimized for user engagement and user satisfaction objectives. However, because training task-specific models can lead to learning billions of parameters for individual tasks, the authors simply change the top layer of the shared-bottom network to an MMoE layer.
Mixture-of-Expert for Recommendations
A lot of recommender system applications are built on a multi-task learning framework. The key idea is to model multiple related objectives, like user engagement (such as clicks, engagement time), user satisfaction (such as ratings, like rate), and user purchases together for a more holistic view of the users. Such joint modeling allows for efficient and effective knowledge and data sharing across relevant tasks. This is especially useful for tasks with sparse data availability. Multi-task learning can also act as a regularizer such that the inductive biases introduced by the auxiliary tasks also improve the generalization of the main task.
Some of the widely used multi-task learning models are based on a shared-bottom model structure. These systems suffer from optimization conflicts caused by different tasks sharing the same set of parameters. Data sparsity, data heterogeneity, and users’ complex underlying intents are some of the other common challenges faced by these multi-task learning systems. Recently, some large-scale recommendation systems have started to utilize MMoE for multi-task modeling and achieve state-of-the-art results for recommendations. This section highlights some notable examples from the industry.
YouTube’s Next Video Recommendation
Zhao et. al11 from Google proposed an MMoE-based multi-objective ranking system for recommending what video to watch next on YouTube. They first group their task objective into two categories: engagement and satisfaction. Given the list of candidate videos from the retrieval step, their ranking system uses candidate, user, and context features to learn to predict the probabilities corresponding to the two categories of user behavior.
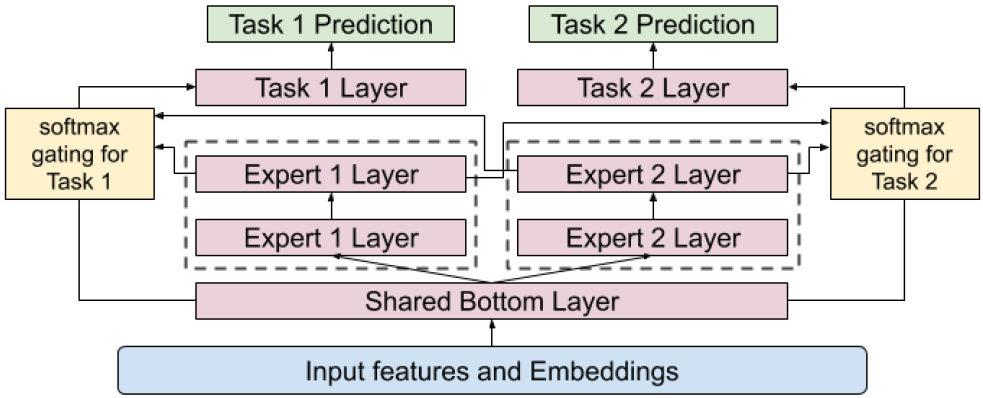
They substitute the last shared-bottom layer in their previous model with the MoE layer with task-specific gating and experts shared across tasks. They chose to not apply the MoE layer directly to the input because the high dimensionality of input would lead to significant model training and serving costs. In the paper, they also describe a shallow tower learned alongside this MMoE to reduce selection biases.
GMail’s Mixture of Sequential Experts
Qin et. al12 from Google, proposed a Mixture-of-Sequential-Experts (MoSE) framework for multi-task modeling that focuses on sequential data (like user behavior from search or browsing logs) instead of non-sequential data (like user query and context) to model user behavior. In order to incorporate temporal dependencies from sequential data modeling into the MMoE structure, they utilized an LSTM shared-bottom, LSTM-based experts and LSTM task-towers.
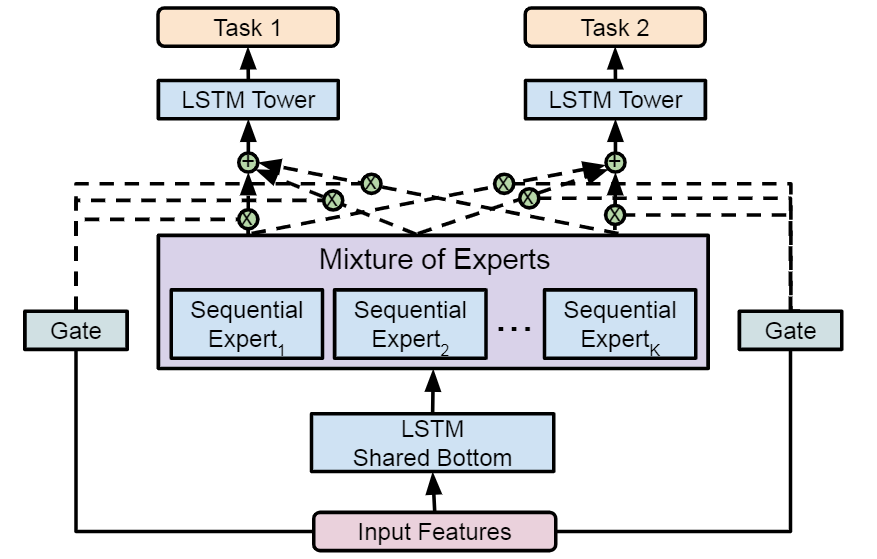
Their experiments showed that the LSTM-based MMoE (MoSE) performed better at modeling user activity streams than the FFN-based MMoE model.
Kuaishou’s Kwai Recommender System
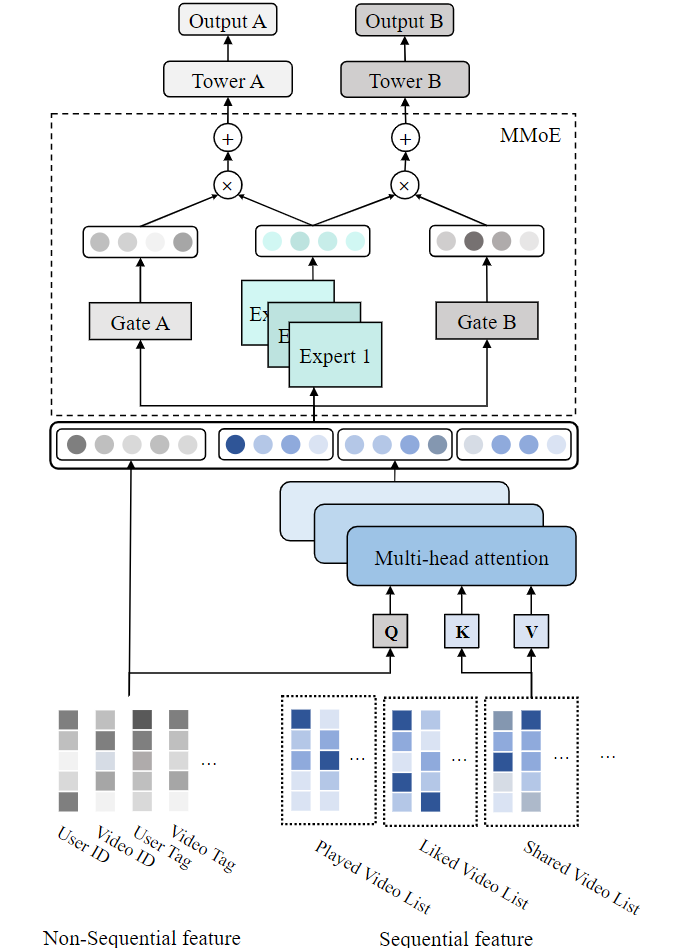
In Personalized Cold Start Modules (POSO), Dai et. al13 explained their recommendation system used in the Kwai app. The input consists of sequential features (like the user’s historical interaction) and non-sequential features (like user ID). All of these features are first mapped into low-dimensional vectors using an embedding look-up table. For each sequential feature, a multi-head attention (MHA) module is used to fuse the embeddings into a concatenation of vector outputs from each head. These sequential and non-sequential vectors are then concatenated and fed into an MMoE layer, which is followed by a task-specific MLP that predicts the probabilities for user behavior specific to the task.
Summary
Mixture-of-Experts have seen a wide-scale adoption in the industry for a number of applications. Their learning procedure divides up the task into appropriate subtasks, each of which can be solved by a very simple expert network. A gating network further reduces the computational overhead by deciding which of the experts should be used for each input. MoEs can automatically adjust parameterization between modeling shared information and modeling task-specific information. MoE layers in deep learning achieve conditional computation where only parts of a network are active on a per-example basis at both training and serving time. This capability translates to parallelizable training and fast inference, making MoEs lucrative for large-scale systems. This article introduced MoE and its variants in detail and highlighted several industrial recommender systems that utilized mixture-of-experts.
References
-
Jacobs, R.A., Jordan, M.I., Nowlan, S.J., & Hinton, G.E. (1991). Adaptive Mixtures of Local Experts. Neural Computation, 3, 79-87. ↩︎ ↩︎
-
Yüksel, S.E., Wilson, J.N., & Gader, P.D. (2012). Twenty Years of Mixture of Experts. IEEE Transactions on Neural Networks and Learning Systems, 23, 1177-1193. ↩︎
-
Kalyan, S.K. (2017). Designing mixture of deep experts. ↩︎
-
Chen, Z., Deng, Y., Wu, Y., Gu, Q., & Li, Y. (2022). Towards Understanding Mixture of Experts in Deep Learning. ArXiv, abs/2208.02813. ↩︎
-
Shazeer, N.M., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q.V., Hinton, G.E., & Dean, J. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. ArXiv, abs/1701.06538. ↩︎ ↩︎
-
Jordan, M.I., & Jacobs, R.A. (1993). Hierarchical Mixtures of Experts and the EM Algorithm. Neural Computation, 6, 181-214. ↩︎
-
Eigen, D., Ranzato, M., & Sutskever, I. (2013). Learning Factored Representations in a Deep Mixture of Experts. CoRR, abs/1312.4314. ↩︎
-
Artetxe, M., Bhosale, S., Goyal, & Stoyanov, V. (2021). Efficient Large Scale Language Modeling with Mixtures of Experts. Conference on Empirical Methods in Natural Language Processing. ↩︎
-
Team, N. (2022). No Language Left Behind: Scaling Human-Centered Machine Translation. ArXiv. /abs/2207.04672 ↩︎
-
Ma, J., Zhao, Z., Yi, X., Chen, J., Hong, L., & Chi, E.H. (2018). Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ↩︎
-
Zhao, Z., Hong, L., Wei, L., Chen, J., Nath, A., Andrews, S., Kumthekar, A., Sathiamoorthy, M., Yi, X., & Chi, E.H. (2019). Recommending what video to watch next: a multitask ranking system. Proceedings of the 13th ACM Conference on Recommender Systems. ↩︎
-
Qin, Z., Cheng, Y., Zhao, Z., Chen, Z., Metzler, D., & Qin, J. (2020). Multitask Mixture of Sequential Experts for User Activity Streams. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ↩︎
-
Dai, S., Lin, H., Zhao, Z., Lin, J., Wu, H., Wang, Z., Yang, S., & Liu, J. (2021). POSO: Personalized Cold Start Modules for Large-scale Recommender Systems. ArXiv, abs/2108.04690. ↩︎
Related Content





Did you find this article helpful?