The Evolution of Multi-task Learning Based Video Recommender Systems - Part 2

This article continues the discussion on the evolution of multi-task learning based large-scale recommender systems. Refer to the this link to read the previous article.
Disentangling Input Space
Intuitively, input features work differently for different tasks. For example, device type (mobile phone or desktop computer) and connection type (mobile network or WiFi) could be good features for predicting multimedia clicks and consumption but they may not help a lot with tasks like upvoting/downvoting. The models that we have seen so far, like MMoE, and PLE, use the original input data and feed them to all experts. Some researchers argue that this approach is still likely to face negative transfer because the problem not only happens on the shared bottom layer but is also a result of input features. As a solution, they have proposed methods that disentangle representations for multiple tasks before gating networks.
Prototype Feature Extraction from Kuaishou
Xin et al.1 proposed a method called Prototype Feature Extraction (PFE) to explicitly capture complicated task correlations. PFE extracts disentangled prototype features from original features for each sample as shared information. The core idea is that the extracted features fuse various features from different tasks to better learn inter-task relationships. The model then utilizes learned prototype features and task-specific experts for MTL.
PFE is based on the Ordinary Feature Extraction (FE) process that builds derived features intended to be informative and non-redundant to be used for learning. It dynamically identifies latent factors, called prototype feature centers, which can be used to disentangle input data into different types. Each center is learned from a cluster of similar features and is intended to extract better features.
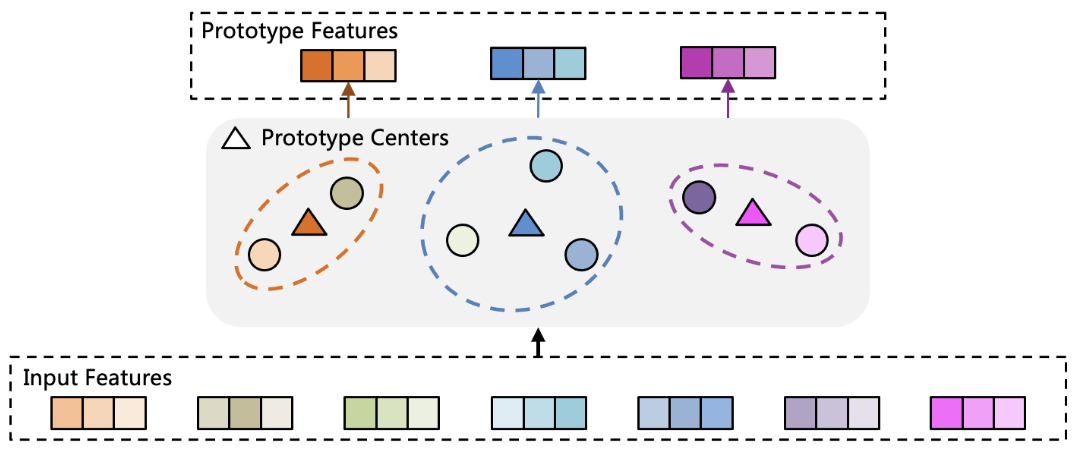
PFE uses an Expectation-Maximization (EM) algorithm for clustering to iteratively update prototype features and prototype feature centers. Overall, network architecture combines the shared information from extracted prototype features and task-specific information from task-specific experts.
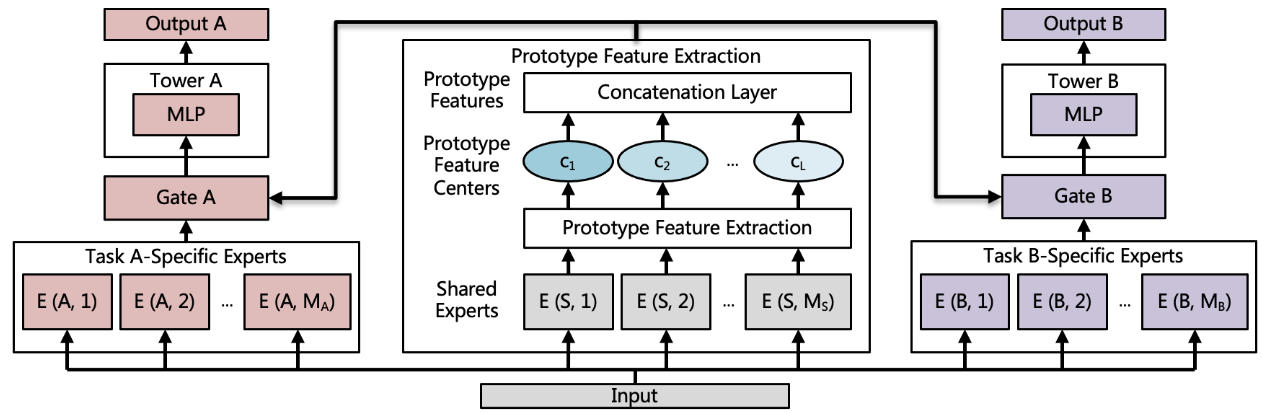
As shown above, the gating networks combine the extracted prototype features and task-specific experts from the bottom module. The top module has task-specific towers that output the results of each task.
Tencent’s Embedding-level Disentanglement
Su et al.2 empirically show that in MTL settings, two tasks benefit from joint modeling when one task has limited positive feedback compared to the other. However, negative transfer is observed when both tasks have a comparable amount of feedback due to possible contradictory user preferences captured by the two tasks. To fix this, they proposed a Shared and Task-specific Embeddings (STEM) paradigm, that incorporates both shared and task-specific embeddings, as opposed to shared embedding models that we have seen so far. Such a paradigm can capture the diversity of task-specific user preferences.
The STEM-net model performs a lookup operation for each feature ID to retrieve both shared and task-specific embeddings. Then it constructs a set of shared and task-specific experts corresponding to these embeddings. The core idea is that parameter interference can be avoided by keeping separate embedding tables for task-specific and shared experts.
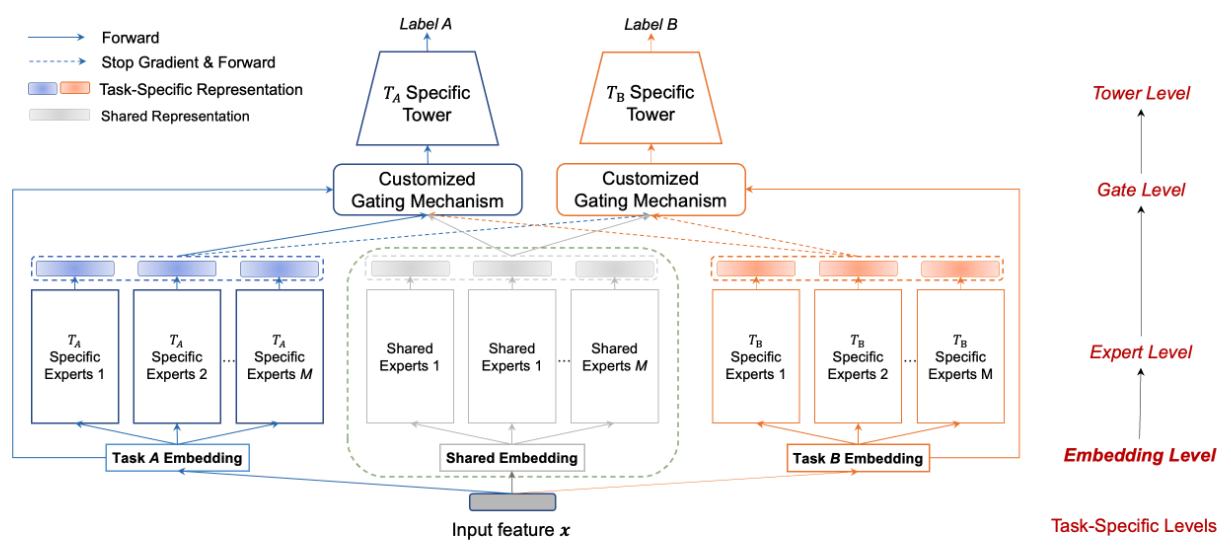
The model also uses stop-gradient operations on experts from other tasks to ensure the learning of task-specific embeddings. This operation prevents the gradients from flowing back to the experts of other tasks, pushing the task-specific tower to exclusively update its corresponding embeddings. Shared and task-specific embeddings are concatenated across all features. The next figure shows the comparison of the gating mechanism in STEM-Net compared to MMoE and PLE.

MMoE updates all experts without distinction, while STEM-Net is optimized for shared and task-specific updates. PLE requires shared experts as intermediaries for knowledge transfer which could result in information loss, but STEM-Net allows towers to directly transfer knowledge from other task experts.
Addressing Biases
In this section, we take a look at some of the proposals to tackle biases in MTL-based video recommender systems.
YouTube’s Position Bias Fix
Our training data is extracted from user logs and is based on user behavior and responses to the current production system. These logged interactions consist of many types of biases. For example, a user may have clicked an item because it was selected by the current system, causing a feedback loop effect. Similarly, position bias refers to a type of selection bias toward the user clicking and watching a video displayed closer to the top of the list, regardless of its actual utility to the user. This bias can cause the more relevant videos in the list to be overlooked. To remove this bias and break the feedback loop, a common approach is to inject position as an input feature in model training and then remove the bias through ablation at serving time. Some methods also learn a bias term from the position and apply it as a normalizer or regularizer.
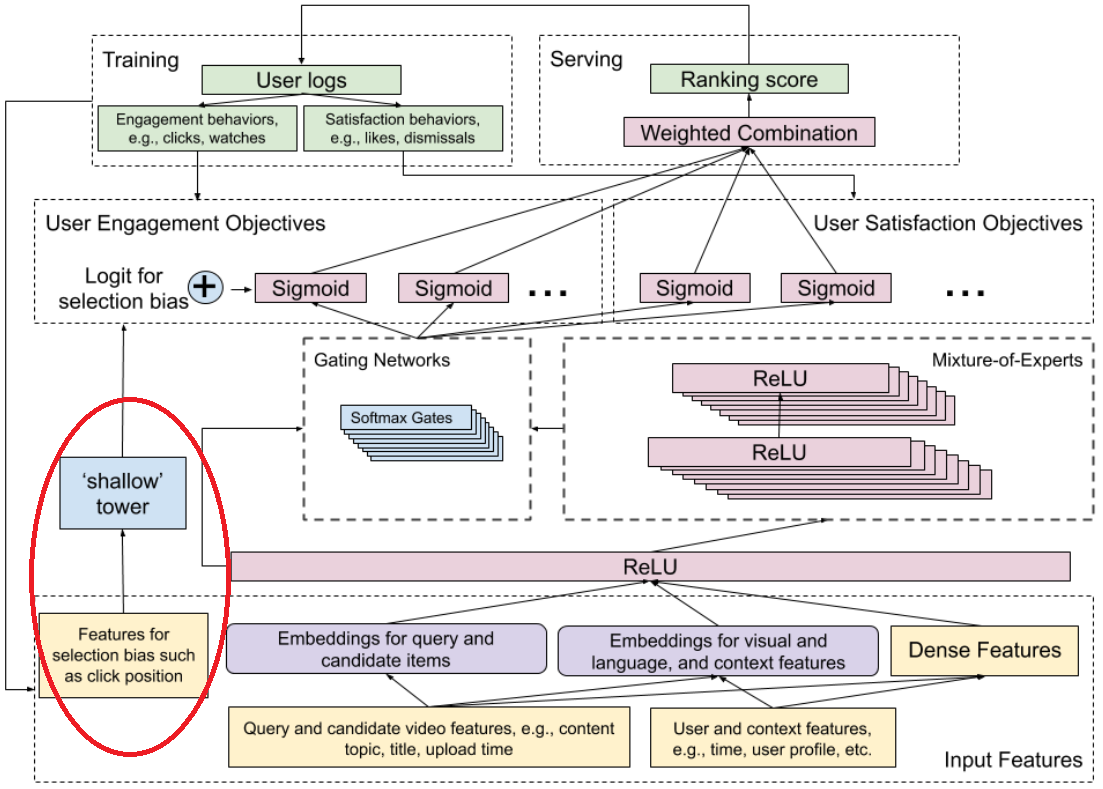
In YouTube’s MT Ranker model, Zhao et al.3 add a shallow tower to reduce the position bias, effectively making it similar to a wide and deep model architecture. The tower uses input contributing to the selection bias (e.g., video position and device data) and outputs a scalar serving as a bias term (or estimated propensity score) to the final prediction of the main model. User utility is calculated from the main tower, and the bias component from the shallow tower is added to the final logits of the main model. At serving time, the feature is set to missing.
Facebook Watch’s Conformity Bias Fix
Raul et al.4 hypothesize that often user-item interaction happens due to ecosystem factors rather than the actual user utility. For example, a user may watch a video just because it has lots of views, even when the video doesn’t necessarily align with their true interests. Such conformity distorts the logged user interactions. The item-side debiasing approach described above does not consider the variety of users’ conformity. For example, a sports fan might purchase a popular bicycle because its features align with their true taste, while a non-enthusiast might purchase the same bike just because it is popular5. Recommender systems may cause strong conformity bias if they fail to account for the fact that historical user interactions could be influenced by multiple factors, making them inconsistent with user preferences.
To disentangle users’ conformity to popular items from their true interests, the authors implemented a Conformity-Aware MT model (CAM2) for Facebook Watch. Previously, Zheng et al.5 tackled this problem by decomposing user interactions into two factors: conformity and interest, and learned separate embeddings for them with cause-specific data. User-item matching scores are computed for both causes and summed up. Effectively, this helps capture the fact that different users have different levels of influence on their judgment. CAM2 extends this idea by learning conformity and relevance-based representations over full data as auxiliary tasks in the same model by partitioning input features.
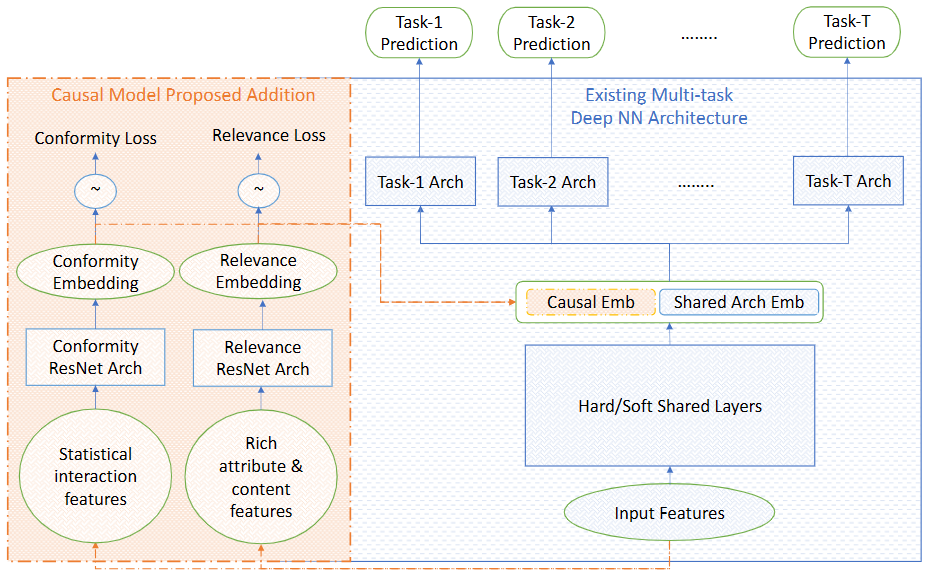
CAM2 trains two separate cause-specific ResNet modules as an auxiliary task to learn conformity alignment and relevance along with corresponding loss values. Note that these losses are only used to train the causal architecture and not for inference. Gradient backpropagation from tasks architecture to the causal module is disabled. User conformity alignment is learned from statistical engagement-based features such as the number of video impressions, views, engagement rate, etc. User relevance is learned from rich attribute-based and content-based features such as user demographics, previously engaged videos, video interest, video quality features, etc. The authors hypothesize that this feature decomposition allows the model to learn more accurate embedding representations for both popular and long-tail groups.
Amazon Prime’s Popularity Bias Fix
Gampa et al.6 described their implementation of a multi-territory recommender system at Amazon Prime Video. Their catalog has coverage of multi-territory videos where a locally popular item can be overshadowed by a globally prevalent item. Even if a video is popular in a specific territory, it may not have as much interaction data as a globally popular item in the same region. This can cause a feedback loop where items that are available in a lot of regions may always be ranked higher. To prevent overfitting on global titles and to improve fairness to local titles, the authors utilized a hard parameter-sharing MT model.
Theoretically, Amazon could train separate region-specific models. However, such an approach can be costly to develop and maintain. In their solution, the authors first upsample input data by adding a disjoint set of active user data along with the regular random user set, hoping to increase the number of positive examples in minor territories. Next, they map the 200 territories into 4 geographically closer groups and develop an MTL-based two-tower model where the user tower is branched out to have 4 task-specific layers, one for each territory group.
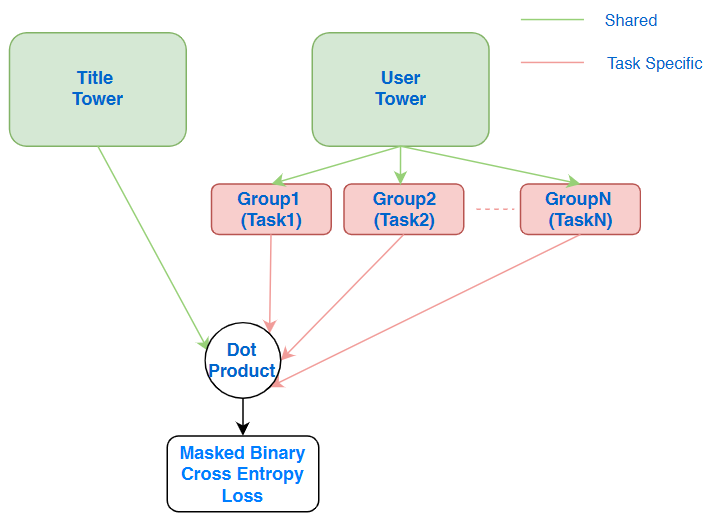
During training, the shared blocks are always updated using backpropagation for all the data points, while the group-specific blocks are only updated for the data points coming from the respective group. The goal for the shared bottom is to enable regularization and transfer some of the learning from low-data territories to high-data territories.
Other Useful Takeaways
- Ma et al.7 highlights several important observations.
- They propose a coarse-to-fine MTL method to jointly predict click-through and playtime. They discretize playtime into several intervals and then use a coarse-to-fine strategy first to make a coarse estimate of playtime as a classification task, and then improve it through a regression task by estimating an offset amount. More importantly, their model accounts for the cascading relationship between click-through rate and playtime, i.e. a user must click the video before watching it.
Modeling this sequential relationship between these two tasks is quite relevant to many modern UI flows, where a user must click an in-feed suggestion for a video to trigger a full-screen short video viewing experience. But Click-through itself cannot capture any post-click engagement. Since playtime can capture post-click user activity, it should be used as a proxy for user engagement and satisfaction. With the joint, cascading-style modeling of CTR and watch time, we could optimize for downstream watch time and also disincentivize clickbait that leads to the user exiting the full-screen video viewing flow shortly after entering it.
Tapping an in-feed suggestions takes user to full-screen short-video viewing experience. - The authors note that the playtime follows a long-tail distribution, and the logarithm of playtime is nearly Gaussian. So they use the log of playtime for playtime prediction. Several approaches in the past have tried modeling playtime as Weibull or Gamma distribution.
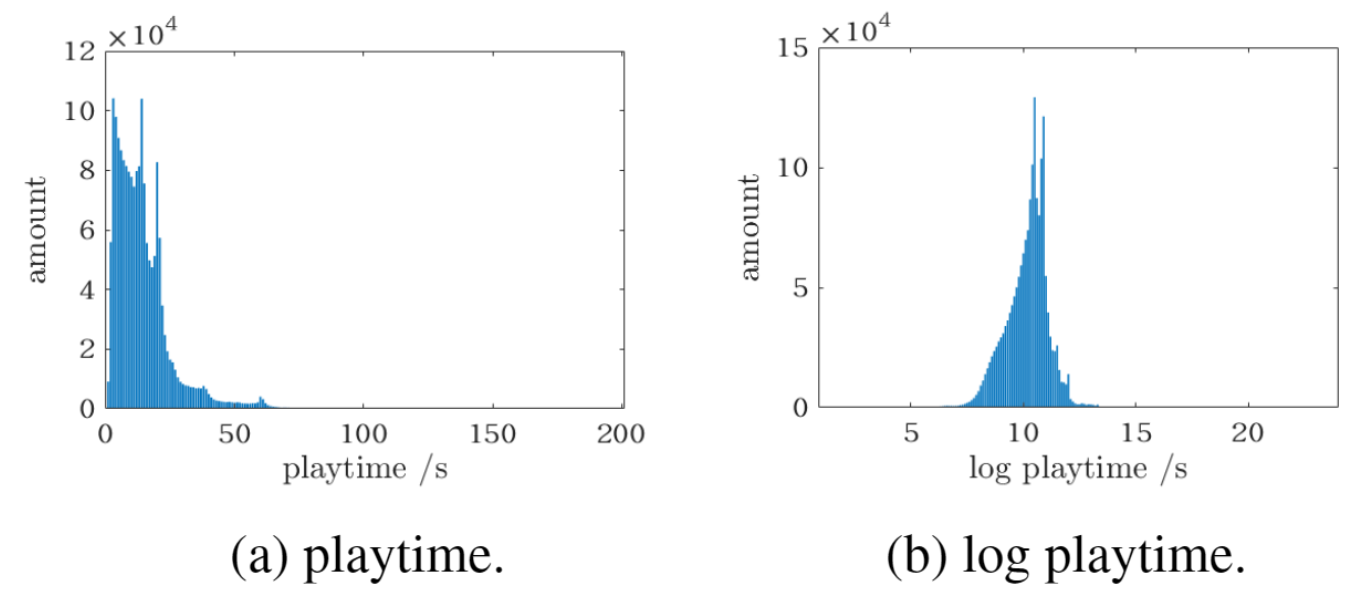
Histogram of short-video playtime - Predicting watch time is hard due to three main reasons:
- Several extraneous factors can affect playtime. For example, the user might leave while the video is still playing, the longer length of the video may dissuade time-constraint users from watching a relevant video, etc.
- Playtime exhibits a long-tail distribution.
- The real-world data samples are usually extremely biased. Several samples may not have any significant watch time.
- They propose a coarse-to-fine MTL method to jointly predict click-through and playtime. They discretize playtime into several intervals and then use a coarse-to-fine strategy first to make a coarse estimate of playtime as a classification task, and then improve it through a regression task by estimating an offset amount. More importantly, their model accounts for the cascading relationship between click-through rate and playtime, i.e. a user must click the video before watching it.
- In Song et al.8 MX Media describes their implementation of the TakaTak short-video MTL recommender system, and in Covington et al.9 Google describes one of the earliest two-stage recommender systems deployed at YouTube. Both papers share several practical tips and are great reads for industry professionals.
- Tang et al.10 serve the MT ranking model for Tencent News. For calculating the weighted score for each candidate video, they also multiply each score value with $f(\text{video length})$ non-linear transform function, such as sigmoid or log function, of the video duration.
- Covington et al.9 share several interesting observations from their work on YouTube.
- Ranking by click-through rate often promotes deceptive videos, such as clickbait, that the user does not complete. Instead, watch time is better at capturing engagement.
- Users consistently prefer fresh content, though not at the expense of relevance.
- In addition to the first-order effect of simply recommending new videos that the user wants to watch, there is a critical secondary phenomenon of bootstrapping and propagating viral content.
- The distribution of videos popularity is highly non-stationary. Feeding the age of the training example as a feature during training could ensure that the model doesn’t simply predict the average watch likelihood in the training window. At serving time, they set this feature set to zero (or slightly negative). This feature addition led the model to represent the time-dependent behavior of popular videos and dramatically increased the watch time on recently uploaded videos in A/B testing.
- Users are likely to discover video through other means than YouTube recommenders, such as embedded videos on other sites. To enable new content to effectively surface, it is important to also propagate such discoveries to others via collaborative filtering.
- Discarding sequence information from a user’s search history and representing search queries with an unordered bag of words could help avoid some undesirable scenarios. For example, if a user recently searched for ‘Taylor Swift’, reproducing results from the same search to recommend the next video feed leads to a poor user experience.
- Features that describe the frequency of past video impressions are crucial to ensure that successive requests do not return identical items. But serving this up-to-the-second impression and the watch history requires an incredible amount of feature engineering effort.
- Generating a fixed number of training examples per user is equivalent to weighing users equally in the loss function, and prevents highly active users from dominating the loss.
- In their experiments, propagating information from the candidate generation stage to ranking stage was crucial. This information can be in the form of features like which sources nominated the candidate video, what score did they assign, etc.
- For the candidate generation step (two-tower model), simply averaging the embeddings of the user’s historical interactions worked better than sumpool/maxpool.
- Predicting users’ next watch rather than predicting a randomly held-out watch always worked better.
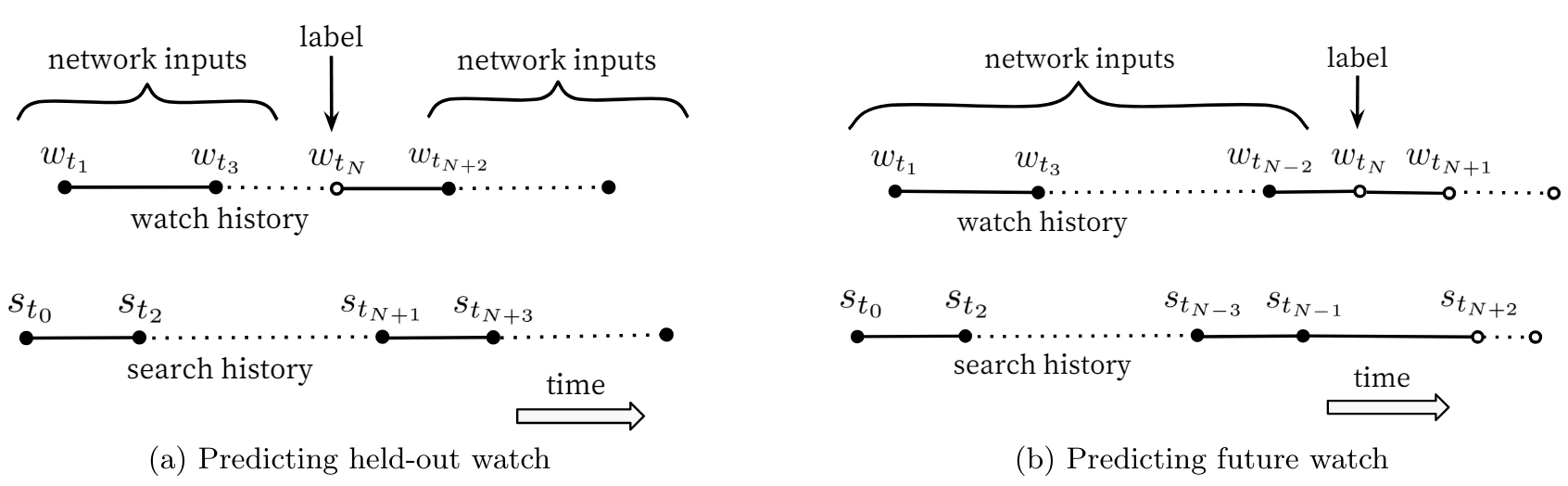
Label selection - Proper normalization for continuous features was critical. Feeding powers of continuous features were found to improve offline accuracy. Given a feature $x$, they supplied raw normalized feature $\tilde{x}$ and powers $\tilde{x}^2$ and $\sqrt{\tilde{x}}$ giving the network more expressive power, allowing it to form super and sub-linear functions of the feature.
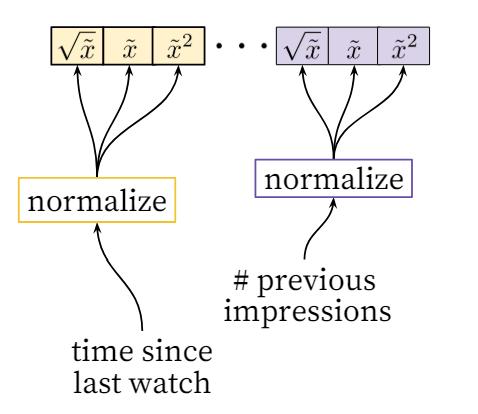
Normalizing Continuous Features
Conclusion
This article concluded the two-part deep dive series about the evolution of the MTL-based video recommender system. It highlighted several nuanced and unique challenges while implementing such systems at a large scale. We looked at state-of-the-art disentanglement strategies to enable effective and efficient learning of inter-task relationships. The article also highlighted several real-world solutions from Kuaishou, Tencent, YouTube, Facebook, and Amazon Prime Video to address different biases and shared insights and takeaways that will be valuable for practitioners in this field.
References
-
Xin, S., Jiao, Y., Long, C., Wang, Y., Wang, X., Yang, S., Liu, J., & Zhang, J. (2022). Prototype Feature Extraction for Multi-task Learning. Proceedings of the ACM Web Conference 2022. ↩︎
-
Su, L., Pan, J., Wang, X., Xiao, X., Quan, S., Chen, X., & Jiang, J. (2023). STEM: Unleashing the Power of Embeddings for Multi-task Recommendation. AAAI Conference on Artificial Intelligence. ↩︎
-
Zhao, Z., Hong, L., Wei, L., Chen, J., Nath, A., Andrews, S., Kumthekar, A., Sathiamoorthy, M., Yi, X., & Chi, E.H. (2019). Recommending what video to watch next: a multitask ranking system. Proceedings of the 13th ACM Conference on Recommender Systems. ↩︎
-
Raul, A., Porobo Dharwadker, A., & Schumitsch, B. (2023). CAM2: Conformity-Aware Multi-Task Ranking Model for Large-Scale Recommender Systems. Companion Proceedings of the ACM Web Conference 2023. ↩︎
-
Zheng, Y., Gao, C., Li, X., He, X., Jin, D., & Li, Y. (2020). Disentangling User Interest and Conformity for Recommendation with Causal Embedding. ArXiv. /abs/2006.11011 ↩︎ ↩︎
-
Gampa, P., Javadi, F., Bayar, B., & Yessenalina, A. (2023). Multi-Task Learning For Reduced Popularity Bias In Multi-Territory Video Recommendations. ArXiv, abs/2310.03148. ↩︎
-
Ma, S., Zha, Z., & Wu, F. (2019). Knowing User Better: Jointly Predicting Click-Through and Playtime for Micro-Video. 2019 IEEE International Conference on Multimedia and Expo (ICME), 472-477. ↩︎
-
Song, J., Jin, B., Yu, Y., Li, B., Dong, X., Zhuo, W., & Zhou, S. (2022). MARS: A Multi-task Ranking Model for Recommending Micro-videos. APWeb/WAIM. ↩︎
-
Covington, P., Adams, J.K., & Sargin, E. (2016). Deep Neural Networks for YouTube Recommendations. Proceedings of the 10th ACM Conference on Recommender Systems. ↩︎ ↩︎
-
Tang, H., Liu, J., Zhao, M., & Gong, X. (2020). Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. Proceedings of the 14th ACM Conference on Recommender Systems. ↩︎
Related Content





Did you find this article helpful?