Teaching Models to Decide When to Retrieve: Adaptive RAG, Part 4

In the previous posts of this series, we established that naive RAG is costly and often harmful. We then explored lightweight methods that decide whether to retrieve based on query characteristics alone, followed by more nuanced approaches that probe the LLM’s confidence by analyzing its outputs and internal states. But all these approaches work with models as-is, either by analyzing inputs or observing output to infer when retrieval is needed.
This final post takes a fundamentally different approach and treats adaptive retrieval as a learned skill. Instead of passively observing the model, we actively train it to participate in the retrieval decision. We will examine three paradigms in increasing order of sophistication:
- Training Separate “Gatekeeper” Models: Training lightweight models that act as intelligent routers, deciding whether to invoke retrieval before passing queries to the main LLM.
- Teaching the Main LLM: Fine-tuning approaches that give LLMs the ability to recognize their knowledge gaps and signal when they need external information.
- Teaching Reasoning About Retrieval: Advanced methods that train LLMs to engage in multi-step reasoning about what they know, what they need, and how to gather missing information iteratively.
As you can guess, each of these paradigms represents a different point in the spectrum of training complexity, computational overhead, and decision-making sophistication.
Paradigm 1: Training Separate “Gatekeeper” Models
The first approach is to treat retrieval decision-making as a classification task handled by a separate, lightweight model. Rather than modifying the main LLM, these approaches train a specialized “gatekeeper” model that takes the user query, and based on its training, decides whether to pass it directly to the LLM for a generation-only response or to route it through a full RAG pipeline.
This separation of concerns offers several practical advantages. The gatekeeper model can be trained independently, updated frequently, and optimized specifically for the decision task without touching the main LLM’s weights. This approach is also computationally efficient at inference time, as the gatekeeper is much smaller than the main LLM. This paradigm also allows the usage of proprietary closed-source LLMs while still implementing adaptive retrieval through the gatekeeping classifier model.
Using a Query Complexity Classifier
Jeong et al.1 argue that while applying a computationally expensive multi-step retrieval process to answer a simple question like “What is the capital of France?” is wasteful and slow, the reverse is also true, i.e., trying to answer a complex, multi-hop query with a simple single-step retrieval, or no retrieval at all, will likely produce an inaccurate answer. The authors propose training a small language model (such as T5-Large) that acts as a “smart router” to predict the complexity level of the incoming query, and dynamically adjust the operational strategy for the RAG pipeline. To train the classifier, they propose a two-part automatic labeling strategy, in which the labels are first generated by simply observing which strategy correctly answers a query, and the remaining unlabeled queries are either assigned the label B or C, based on whether the query originated from a single-hop or multi-hop dataset, respectively.
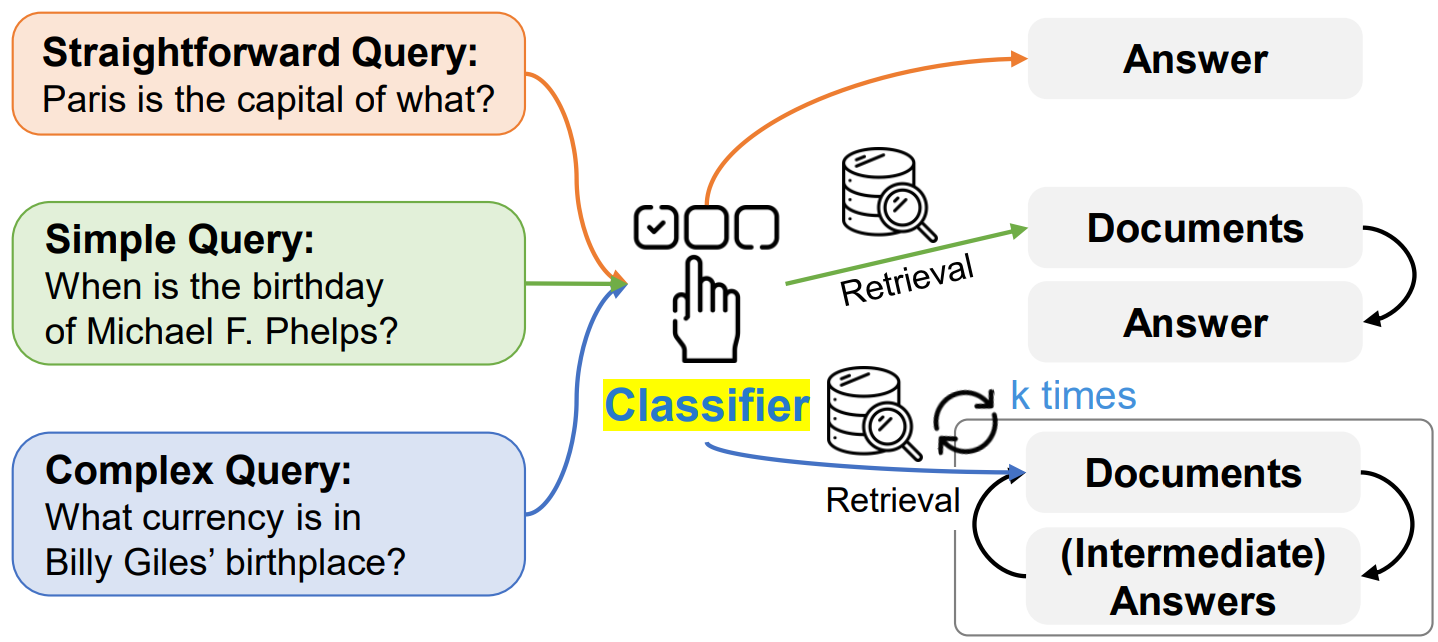
The classifier assigns one of the three pre-defined complexity levels to the query: “A”, “B”, or “C”. The label “A” indicates that the query is straightforward and answerable by LLM’s parametric memory, “B” indicates moderate complexity where a single-step RAG is activated, and “C” indicates a complex question requiring a multi-step iterative RAG process. The code for this paper is available on GitHub.
Using Multiple Classifiers to Determine the Need for Retrieval
In UAR (Unified Active Retrieval), Cheng et al.2 hypothesize that relying on a single criterion, like either intent awareness, knowledge awareness, time awareness or, self-awareness, for adaptive RAG is limiting in real-world scenarios. These criteria are defined as follows:
- Intent Aware: Does the user explicitly want the model to use retrieval?
- Knowledge-Aware: Does the question require factual knowledge to answer?
- Time-Sensitive Aware: Is the answer likely to change over time?
- Self-Aware: Does the LLM have the necessary knowledge stored internally?

The authors propose a multi-faceted decision-making process that considers all four distinct orthogonal criteria to determine if retrieval is necessary. For each criterion, the authors train a lightweight, plug-and-play binary classifier on the last layer’s hidden state of a fixed LLM to judge whether the input requires retrieval. The input for each classifier is the hidden state of the last token from the user’s instructions.
At inference time, the UAR-Criteria framework specifies priority for multiple retrieval criteria and unifies them into a single decision tree, as shown below.
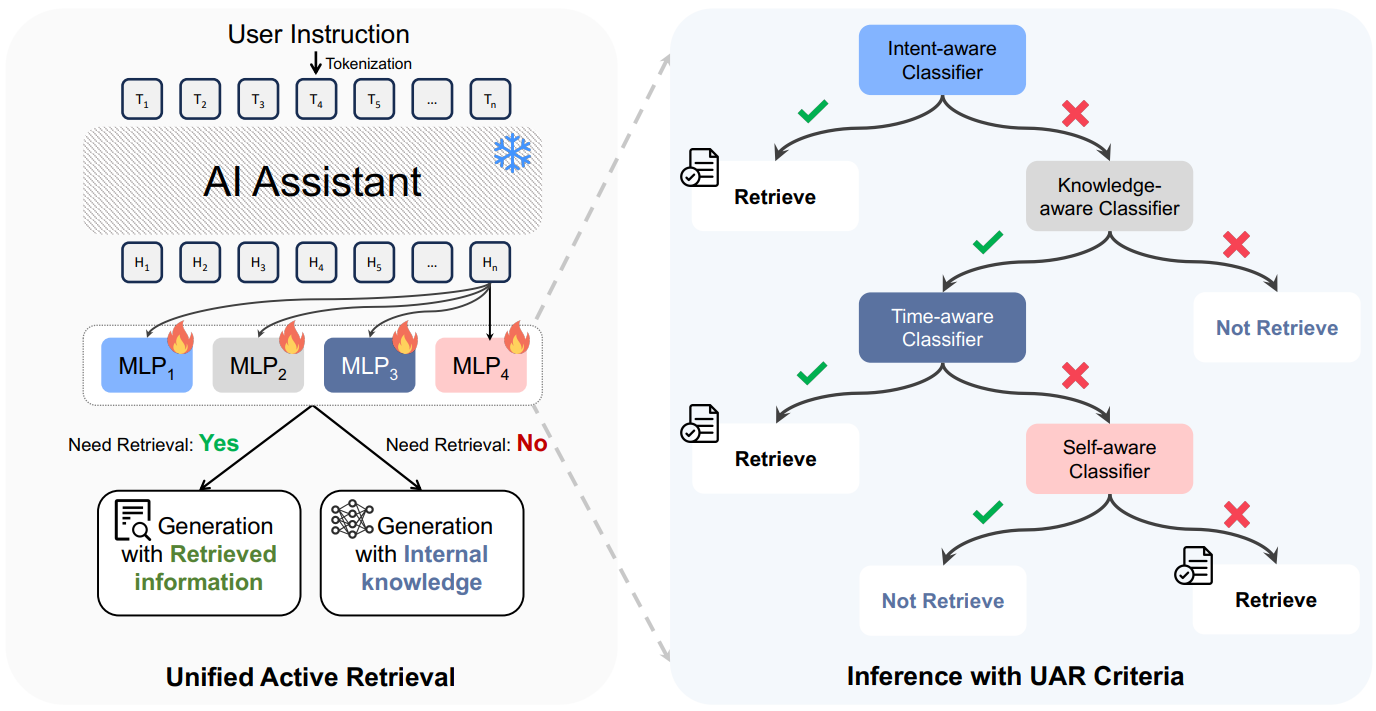
- First, the intent-aware classifier checks if the user has an explicit retrieval intent. If yes, retrieval is triggered immediately. Otherwise, the knowledge-aware classifier determines if the query requires factual knowledge. If not, retrieval is skipped.
- If the query is deemed knowledge-intensive, the time-aware classifier checks if the answer is time-sensitive. If yes, retrieval is triggered.
- Finally, if the query is knowledge-sensitive but not time-sensitive, the self-aware classifier decides if the model has the relevant internal knowledge to answer the question, or if retrieval should be triggered.
The code, data, and models for UAR are available on GitHub.
Using Multiple Classifiers to Filter the Retrieved Context
Zeng et al.3 propose a multi-stage filtering approach that uses four task-specific binary classifiers, each trained on one of the four distinct knowledge-checking tasks:
- Internal Knowledge Checking: Does the LLM have the knowledge to answer a query without any help?
- Uninformed Helpfulness Checking: Is a retrieved document helpful when the LLM lacks internal knowledge about the query?
- Informed Helpfulness Checking: Is a retrieved document helpful even when the LLM already knows the answer?
- Contradiction Checking: Does the retrieved information contradict the LLM’s internal knowledge?
The authors used the RetrievalQA dataset for the first task, subsets of the Natural Questions dataset for the two helpfulness tasks, and a subset of the ConflictQA dataset for the final task. The positive and negative examples for each task are fed into a base LLM (e.g., Mistral-7B-Instruct). The authors hypothesize that LLMs’ representations exhibit distinct patterns when they encounter high-level concepts, such as helpful vs unhelpful prompts. Based on this, the internal representation from the LLM’s final layer for the last input token is used to train classifiers with respect to the four tasks.
While the other methods discussed in this post focus on the initial retrieval decision, this paper used the trained classifier after retrieval but before generation, to filter out all the unhelpful or misleading documents. During inference, the system retrieves an initial set of documents for the given user query. In parallel, the query is sent to the Internal Knowledge Classifier to determine if the query is “Known” or “Unknown”. Then each of the retrieved documents goes through the Helpfulness Checking Classifier. If the query was classified as “Known” by the first classifier, the documents also go through the Contradiction Checking Classifier. Finally, any document classified as “unhelpful” or “contradictory” is discarded before the final answer is generated.
Using an Encoder-Based Classifier
In RAGate-MHA (RAGate-Multi-Head Attention), Wang et al.4 propose training a multi-head attention neural classifier model (based on the Transformer architecture’s encoder part) specifically for the task of deciding when to retrieve.
For training the classifier, the authors used the KETOD dataset, which includes human labels as ground truth, indicating the turns where knowledge augmentation is needed. The main input to the classifier is the conversational context (dialogue history), but the authors additionally experimented with the following 3 setups.
- Context Only: Use only the conversation history as input for queries, keys, and values in the attention mechanism.
- Context + Knowledge: Use conversation history combined (concatenated) with the retrieved knowledge snippet.
- Context x Knowledge: Use conversation context as the query and the retrieved knowledge as the keys and the values. This setup is configured to specifically model the interaction between dialogue and the document.
Through experimentation, they found that the ‘Context Only’ version provided the best overall performance. The model was particularly effective at capturing human retrieval patterns, learning to augment more at the beginning of conversations, and for information-heavy domains. After processing the input, the model passes its final representation through a linear layer and a softmax function to produce a binary output that is used to make the decision on whether to augment the response with external knowledge.
Training a Lightweight Knowledge Boundary Classifier
In KBM (Knowledge Boundary Model), Zhang et al.5 argue that a decision to retrieve made by a powerful model like GPT-5 may not be appropriate for a smaller model like Llama-2 7B, as their inherent “knowledge boundaries” are very different. By systematically measuring a model’s confidence and certainty on various questions, we can generate a dataset that maps its unique knowledge boundary. This dataset can then be used to train a specialized, light-weight model whose only job is to decide whether the main LLM needs knowledge-augmentation.
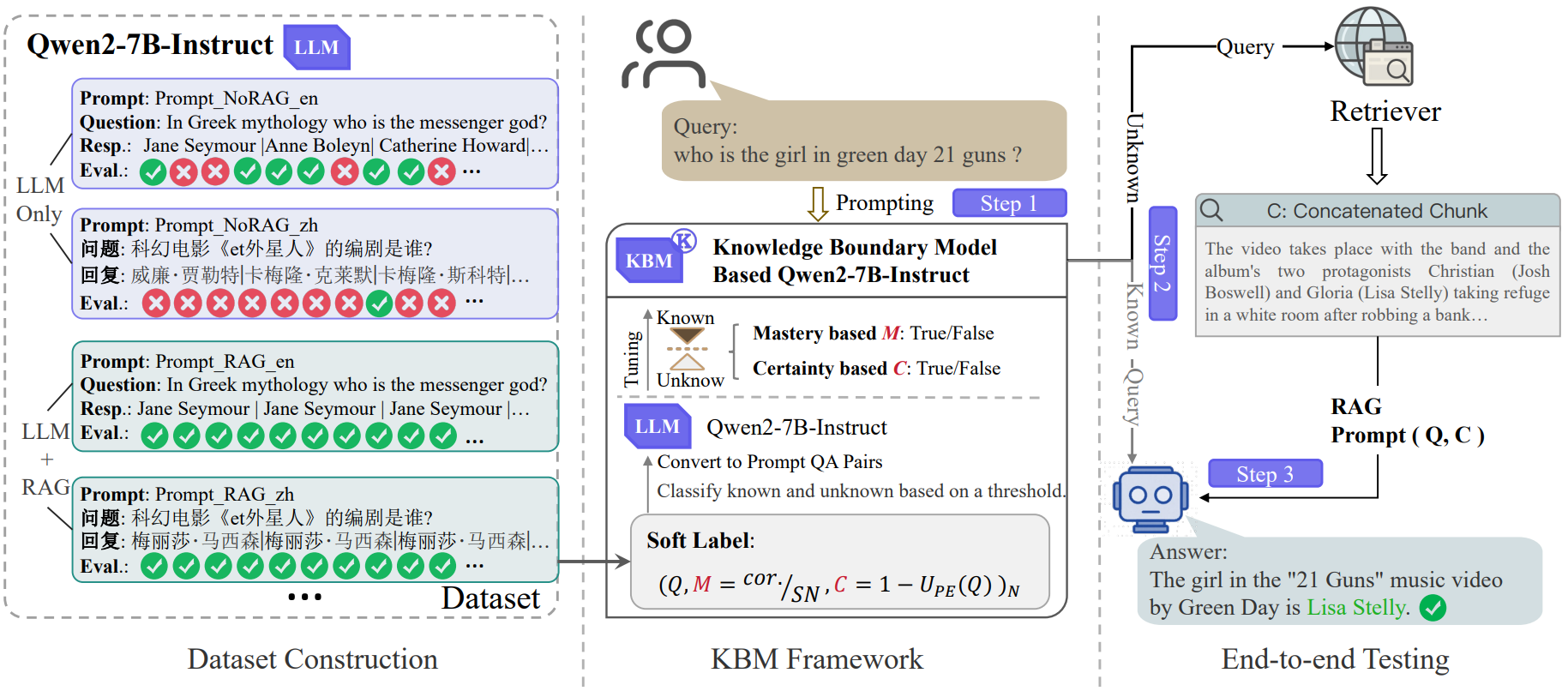
During training, for a large set of questions, their framework generates “soft labels” by repeatedly querying the target LLM (e.g, Qwen2-7B) and calculating the following two metrics.
- Mastery (or Confidence): For questions with known correct (gold) answers, we sample 30 responses from the LLM. The mastery score is simply the percentage of correct answers in that sample.
- Certainty: For questions without any gold answer, we measure the consistency of the 30 sample responses. This can be done by calculating the entropy of the different answer phrases. A low entropy score means that the model is highly consistent and certain, even if it’s confidently wrong.
The authors set a predefined threshold on these 2 scores to automatically label every question as “Known” or “Unknown” for that specific LLM. This dataset is then used to fine-tune a separate model (the KBM model). During inference, the user query is first sent to the KBM. If the KBM predicts the query is “Known”, the query is directed to the main LLM to produce the answer; otherwise, if KBM predicts the query to be “Unknown”, a RAG pipeline is activated instead.
Combining Proactive and Reactive Classifier Strategies
In DioR, Guo et al.6 critique ARAG methods that rely on simplistic rules, like triggering retrieval when an output token’s generation probability falls below a threshold. They argue that low token probability doesn’t necessarily mean the final output will be a hallucination, and these triggers are often reactive, acting only after a hallucination has started. To solve this, they propose a framework called Adaptive Cognition Detection that uses a dual classifier approach that can act proactively before generation and reactively during generation.
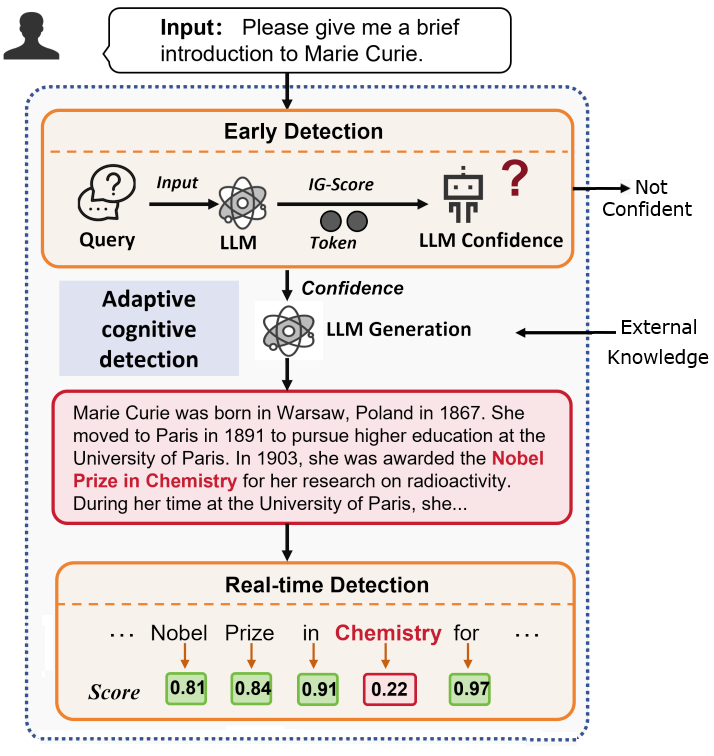
-
Early Detection Classifier: The authors hypothesize that when a model is confident, its attention is sharply focused on a few key terms in the query. But when it’s uncertain, the attention is more dispersed. They use a metric called Attribution Entropy to compute how the LLM ‘attends’ to the user’s initial question. A low entropy score suggests focused attention and high confidence, while a high entropy score suggests dispersed attention and a higher chance of hallucination. An RNN-based classifier is trained to predict the hallucination label on questions from Wikipedia based on the question’s attribution entropy.
-
Real-time Detection Classifier: If a query passes the initial check, a second classifier is used to monitor the LLM’s output on-the-fly. This MLP-based classifier is trained to spot hallucinations as they appear during the generation process. The authors hypothesize that entity-level errors, such as incorrect names, dates, or places, are the most common source of hallucinations. Thus, to create training data for this classifier, the authors take passages from Wikipedia, truncate them, and ask LLM to continue the text. The entities in the generated text are then compared to the entities in the original, ground-truth text. If the entities are semantically different, the training example is labeled as a hallucination.
During inference, a question is first fed to the early detection classifier. If it predicts a lack of confidence, the retrieval is triggered immediately; otherwise, the LLM generates the answer token-by-token. During this generation, the real-time detection classifier assesses each token. It pauses generation and triggers retrieval if a token is classified as being part of a likely hallucination.
A Bandit Approach to Extend Since-Class Supervision Methods
In MBA-RAG (Multi-arm Bandit RAG), Tang et al.7 argue that the prior classifier-based methods, such as the one proposed by Jeong et al.1, rely on ‘single-class supervision’. These methods assume there’s only one retrieval strategy that’s optimal for a given query, typically one with the lowest computational cost. This assumption could be inaccurate, as it penalizes other strategies that might also yield a correct answer that could also be more comprehensive. It also prevents the model from learning more nuanced tradeoffs between different approaches. Instead, the authors reframe the retrieval strategy selection as a game of exploration and exploitation using a classic reinforcement learning concept, i.e., the multi-arm bandit algorithm.
The MBA-RAG framework treats each retrieval strategy as a distinct “arm” of a slot machine:
- Arm1: Direct Answer (no retrieval)
- Arm2: Retrieve Once
- Arm3: Iterative Retrieval
The goal is to train an agent that learns to “pull” the arm that will yield the highest reward for a given query. The model is supervised only by the feedback (reward) of the arm it pulls, without penalizing the strategies that were not selected, allowing it to explore different strategies and learning a more comprehensive selection policy. To guide this process, the authors propose a fine-grained reward function that balances accuracy with computational efficiency, to penalize strategies that are correct but unnecessarily costly.
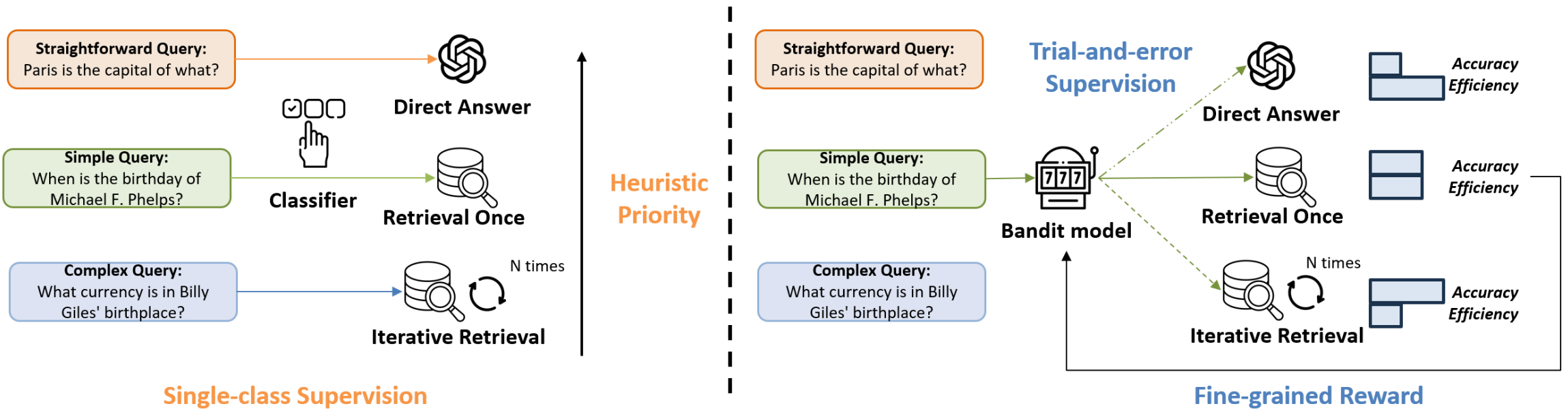
First, a lightweight pre-trained language model, DistilBERT, is used as a query encoder. It takes the user’s query and outputs a prediction of the expected reward for each arm. To balance what it already knows (exploitation) and trying new things (exploration), an epsilon-greedy strategy is used, such that the arm with the highest predicted reward is selected with probability $1-\epsilon$, while a random arm is selected with probability $\epsilon$.
After the model selects an arm $a$ and the corresponding RAG strategy is executed, the model receives a reward $r_a$ calculated by a cost-aware function: $$r_a = \mathcal{A}(y,\hat{y}_{a}) -\lambda C(a)$$
Where $\mathcal{A}(y,\hat{y}_{a})$ is an accuracy metric, such as an exact match, $C(a)$ is the computation cost of the strategy (measured by the number of retrieval steps), and $\lambda$ is a hyperparameter that balances accuracy vs efficiency. The query encoder is then trained to minimize the squared error between its predicted reward and the actual received reward. Over time, the model learns to accurately predict which retrieval strategy will yield the best balance of performance and cost for a given query’s complexity. The authors note the challenges in scalability and adaptability when entirely new types of queries are encountered. The code for MBA-RAG is available on GitHub.
Use a Smaller Model From the Same Family to Predict the Knowledge Gaps
In SlimPLM (Slim Proxy Language Model), Tan et al.8 hypothesize that large and small decoder-only models, which often share similar Transformer architectures and are trained on overlapping public datasets, can reach a consensus on what they know and what they don’t know. Their preliminary experiments show that the knowledge gap between a large model like Llama2-70B and a small one like Llama2-7B is most apparent on difficult questions they both struggle with. And if the small model can correctly answer a question, the large model is very likely to be able to correctly answer it as well. Hence, the authors propose using a proxy model with fewer parameters to predict the knowledge gaps of a large one.
First, the small proxy model is given the user question as input to generate a preliminary “heuristic answer”. The heuristic answer and the original question are then fed into a light-weight, fine-tuned “Retrieval Necessity Judgement” (RJ) model, like Llama2-7B. The RJ model outputs a simple binary decision.
Input:
You are a helpful assistant. Your task is to parse user input into structured formats and accomplish the task according to the heuristic answer.
Heuristic answer: {Heuristic Answer} Question: {user question} Retrieval Necessity Judgment Output: Output:
Known (True / False)
If the output is “Known”, the system assumes that the LLM can answer from its internal knowledge. Whereas if the output is “Unknown”, the system triggers the retrieval-augmentation workflow.
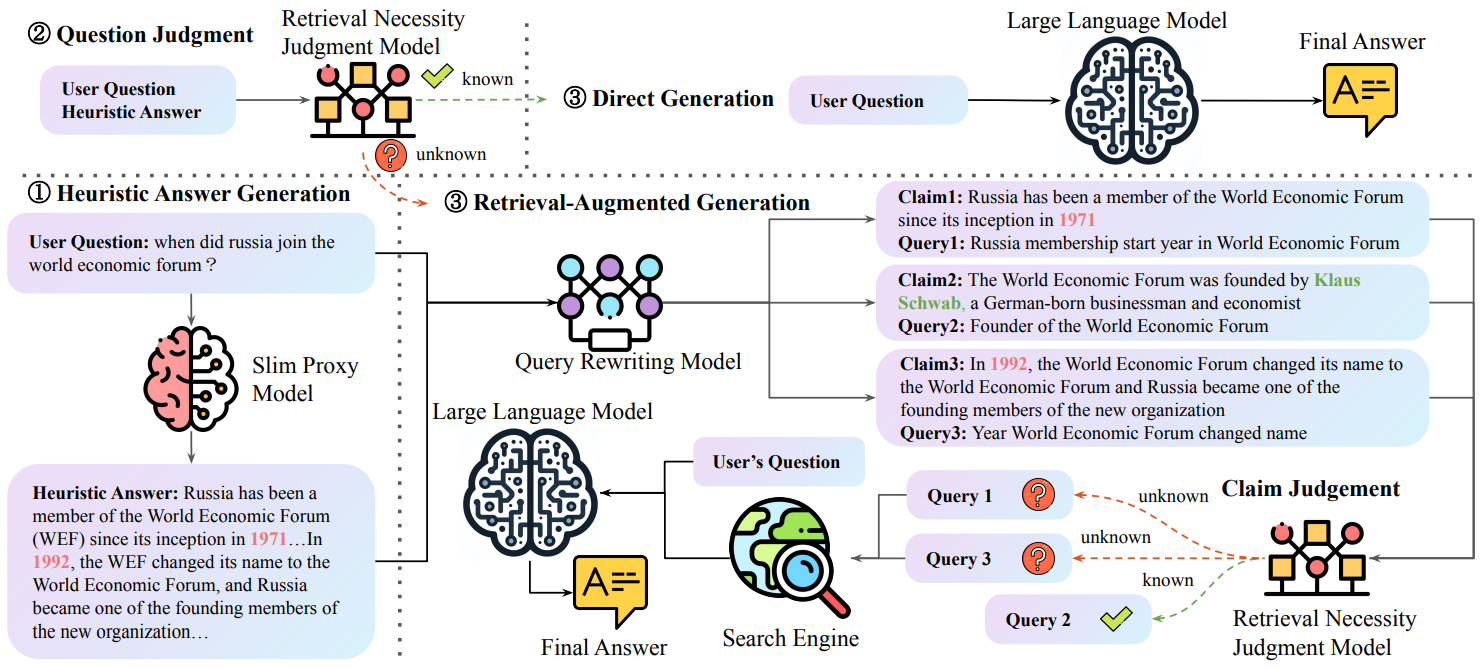
When retrieval is triggered, a query rewriting model decomposes the heuristic answer into a set of distinct individual claims and generates a specific search query for each claim. The RJ model is then reused to filter out claim-query pairs that LLM is likely to already know. Retrieval is only performed for the queries that pass the filter, and the resulting documents are then passed with the original question to the LLM for generating the final answer. The code and dataset for SlimPLM are available on GitHub.
Gatekeeper-based approaches are excellent at operational simplicity. They are easy to deploy and can be retrained without affecting the main LLM. However, this paradigm has several inherent limitations. These methods require managing a separate training pipeline and dataset for the gatekeeper and incur a small additional latency during inference. The gatekeeper can not adapt its judgement based on the LLM’s generation process, as it makes its decision before seeing how the LLM would respond. There’s also a risk of “knowledge gap” between the gatekeeper and the main LLM when the classifier may not perfectly align with the LLM’s true knowledge boundaries, leading to suboptimal routing decisions.
To overcome some of these challenges, the next section introduces methods that teach LLM itself to recognize and communicate its knowledge boundaries.
Paradigm 2: Teaching the Main LLM
Instead of using an external model, we can teach the main LLM to be self-aware about its own knowledge limitations and communicate the need for retrieval. This paradigm involves fine-tuning the LLM on specialized datasets, teaching it to generate special tokens, specific phrases, or internal signals that trigger the retrieval process.
These methods make the LLM become self-aware learning, not just to answer questions, but also to recognize when it shouldn’t answer without help. This paradigm offers several advantages in decision quality. The retrieval decision is better aligned with the LLM’s internal states, as the model itself is the one making the decision. A single model handles both the retrieval decision and the subsequent generation, eliminating the coordination overhead of the gatekeeper-based methods. The use of Parameter-Efficient Fine-Tuning (PEFT) techniques also helps in making this approach computationally feasible.
Train Language Model to Introspect Its Output and Request Retrieval When Required
In Self-Reflective Retrieval-Augmented Generation (SELF-RAG), Asai et al.9 introduce a framework that trains an arbitrary LM in an end-to-end manner to adaptively retrieve passages on demand. SELF-RAG trains the model to generate intermittent special tokens, called reflection tokens, alongside the regular text. These tokens act as an internal monologue, allowing the model to critique its own output and hence control the generation process. The following figure shows the two types of reflection tokens (Retrieve and Critique) that the model learns to generate to indicate the need for retrieval and its generation quality, respectively.

- Training Process: First, a proprietary LLM like GPT-4 is prompted to generate the appropriate reflection tokens for various examples. Then, inspired by reward models used in reinforcement learning, a separate “critic” model is trained by fine-tuning a pre-trained LM (like Llama-2) on this dataset, where reflection tokens are the labels. The goal here is to effectively distill the judgment capabilities of the larger model to a critic model, which is then used to annotate a large, diverse dataset of instructions and responses. For each piece of text, the critic inserts the appropriate
[Retrieval],[ISREL],[ISSUP], and[ISUSE]tokens to create a rich annotated corpus.
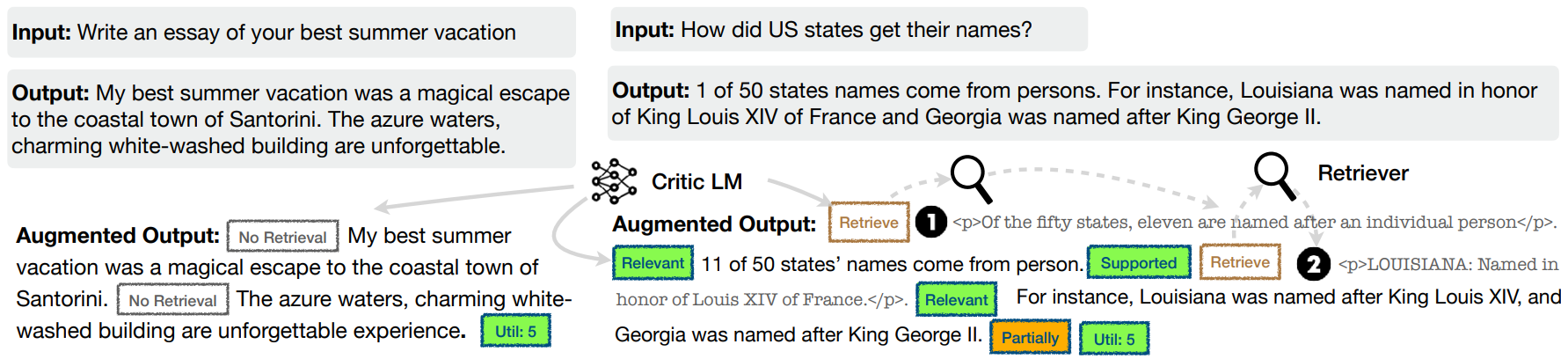
Finally, a generator LM (the end-product of the SELF-RAG model) is trained on the annotated corpus with a standard next-token prediction objective. This model predicts both the response text and the interleaved reflection tokens.
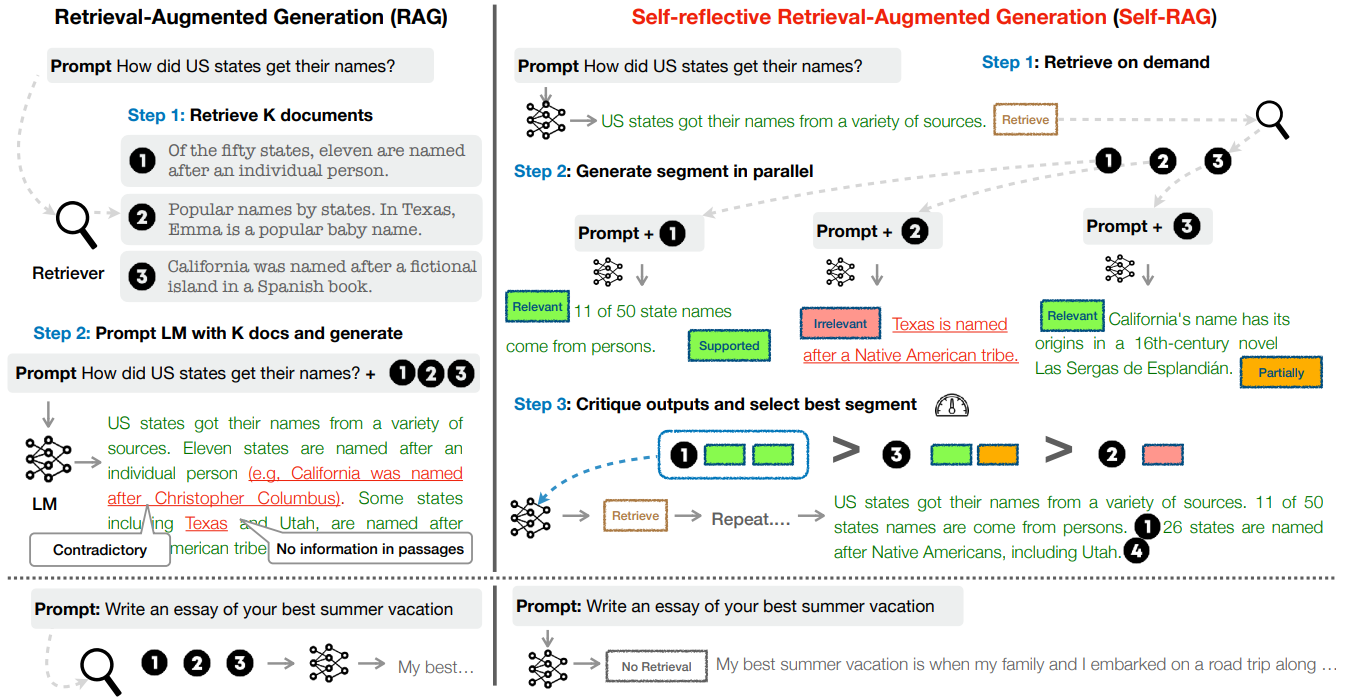
- Inference Process: Given a prompt, the model first generates a
[Retrieval]reflection token to decide if fetching external information would be helpful. A tunable probability threshold can be used here to optimize the decision to invoke retrieval. No retrieval is performed if the model generates[Retrieval=No], and if it generates[Retrieval=Yes], a retriever is used to fetch external documents. The model processes retrieved documents in parallel and generates a candidate response for each one. Then it critiques its own output by producing[ISREL]token to evaluate the relevance of the retrieved passage and[ISSUP]to evaluate if its own generation is supported by the passage. Finally, the best response is selected based on the critique tokens, and the process is repeated for the next segment. This reflection step also enables the model to discard generated segments that are based on irrelevant or contradicting passages.
Some recent studies have argued that SELF-RAG’s effectiveness is tied too closely to the base LM’s ability to generate accurate self-reflection tokens 10 11, and the model just learn to “mechanically” predict these tokens without developing any deeper reasoning capabilities 12. Also, this method is primarily designed to differentiate between knowledge-intensive and non-knowledge-intensive instructions, which may be less optimal for tasks like multi-turn conversational dialogue 2. The code and trained models for SELF-RAG are available on Github.
Simplifying SELF-RAG
In the previous section, we explored how Self-RAG trains a model to have a sophisticated internal monologue to retrieve, generate, and critique its own output segment-by-segment using a variety of special “reflection tokens”. Labruna et al.13 propose a framework, called ADAPT-LLM, to simplify this method by focusing on teaching an LLM a single, fundamental skill of recognizing its own knowledge gaps. Instead of relying on a separate critic model to generate labels, this method uses the base LLM’s own performance to bootstrap the training corpus. The authors create a self-correcting feedback loop where if the model answers correctly from its parametric memory, it’s taught to do so again. In case of incorrect answers, two different training instances are created. The first teaches the model to only emit a special <RET> token, which signals the need for retrieval, while the second teaches it to correctly answer the question after being provided with the question and the corresponding context passage.
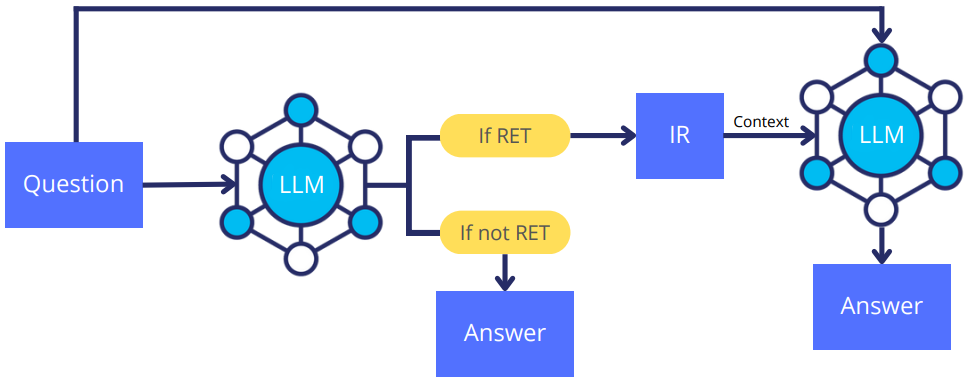
The base LLM is then fine-tuned on this newly constructed dataset. During inference, the model either generates the final answer or the <RET> token indicating the need for retrieval. The code for ADAPT-LLM is available on GitHub.
Multi-Turn Conversational QA Extension for Self-RAG
Roy et al.14 proposed an extension to SELF-RAG for multi-turn conversational question-answering where context is often built over multiple turns. The authors redesign the prior framework to include a conversational history instead of a single-turn question.
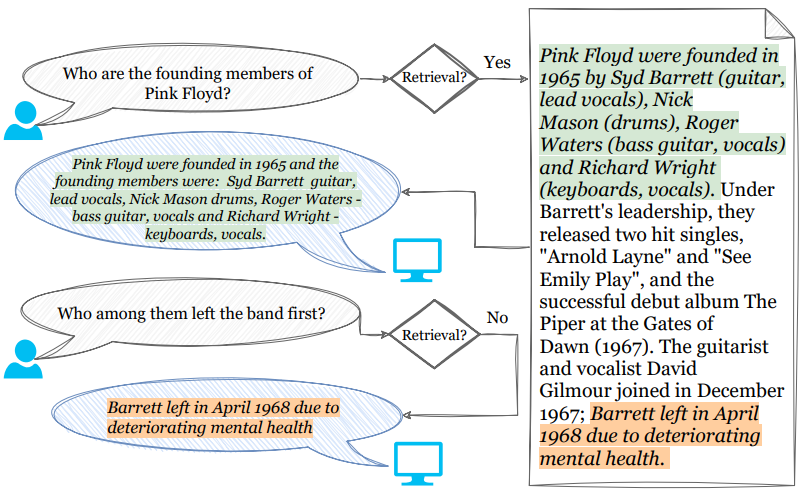
They extend the binary decision to retrieve ([Retrieve]), or not retrieve ([No Retrieve]) by teaching LLM to generate a new special token [Continue to Use Evidence] to indicate that the answer can be found in the conversation history or within the previously retrieved passages.
Multimodal Extension for SELF-RAG Framework
In ReflectiVA (Reflective LLaVA), Cocchi et al.15 adapt the Self-RAG framework to a knowledge-based Visual Question-Answering (VQA) task using multimodal LLMs (MLLMs). The authors teach an MLLM to distinguish between a purely visual question (like, “what color is the cat in this image?”) that can be directly answered by an MLLM, versus ones that require external knowledge (“what company manufactured this truck?”). Similar to Self-RAG (although a bit less granular), ReflectiVA introduces four reflective tokens to the model’s vocabulary:
<RET>and<NORET>to indicate whether retrieval is required or not, to answer the question about the image<REL>and<NOREL>to assess if a retrieved passage is relevant or not relevant to the image-question pair
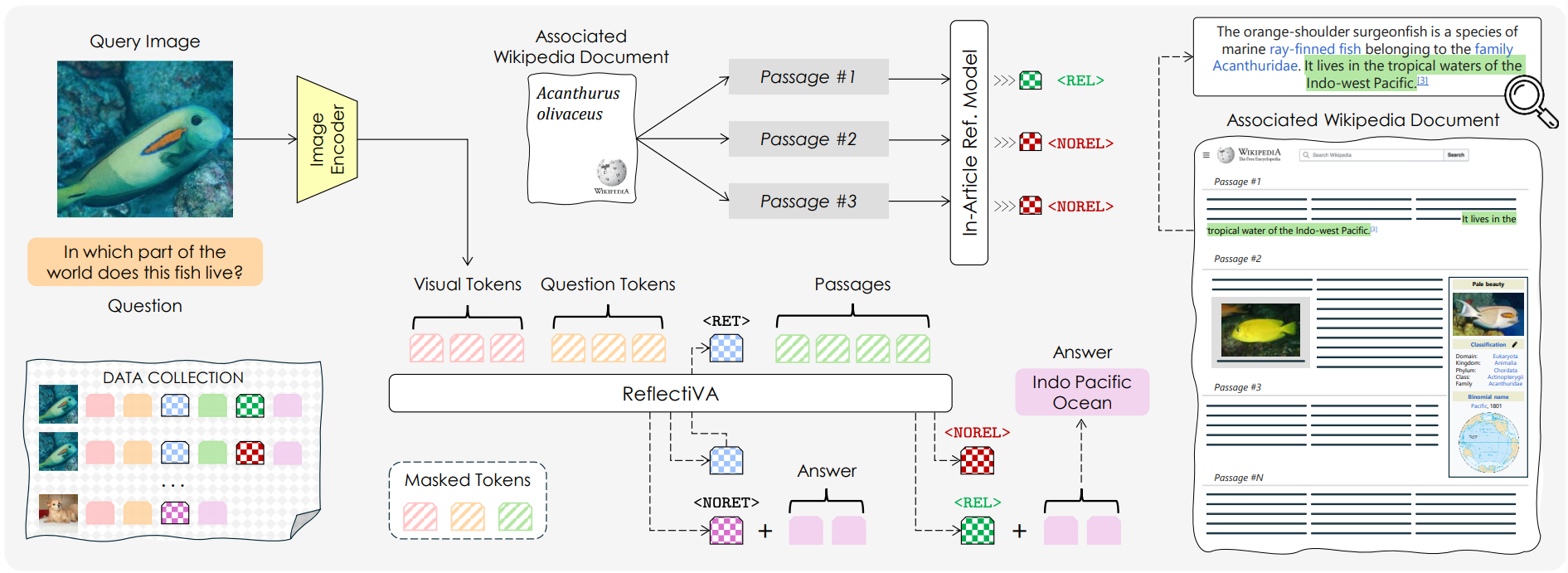
Like Self-RAG’s critic model, ReflectiVA trains a preliminary “in-article reflective model” to generate a high-quality training set for the final model. This model learns to distinguish between relevant and non-relevant text passages coming from the same source article. To create training data for this critic model, the authors used GPT-4 to generate positive (i.e., containing the answer) and negative labels, given an image, a question, and all of the passages from the ground-truth Wikipedia article. This critic model is then used to build a much larger dataset for training the final model. Passages are labeled <REL> and <NOREL> depending on whether the critic model finds them relevant to the given image-question pair. The authors add data from standard conversational and instruction-following datasets with <NORET> label and samples from knowledge-intensive VQA datasets with <RET> label. Finally, the ReflectiVA model is trained on this rich, annotated corpus of images, questions, and passages to learn to generate both the correct answer and the appropriate reflective tokens.
During inference, given an image and a question, the model is first asked to generate a single token, with its choices restricted to either <RET> or NORET. If the model outputs <RET>, it proceeds to generate the final answer using only the image-question pair and its internal memory. If the model outputs <NORET> instead, a retrieval process is activated. Before generating the final answer, the model judges the relevance of each retrieved passage by generating <REL> or <NOREL> tokens. The model then generates the final answer, but it is conditioned only on the retrieved passage marked as relevant. The source code and trained models for this paper are available on GitHub.
Fine-Tuning the LLM to Predict Information Needs
Déjean et al.16 argue that the LLM can also be efficiently trained to determine if an answer is already in its parametric memory. Interestingly, they find that this capability is significantly enhanced by allowing the model to generate the first few tokens of its response before making the decision. This partial answer text seemingly provides a powerful clue about the model’s internal state, making the decision to retrieve more reliable.
The process begins by creating training data using a separate LLM model (SOLAR-10.7B-Instruct-v1.0) to act as an “evaluator” or a “judge”. First, the main LLM (like Mistral-7B or Llama-3.1-8B) generates answers for a large set of questions from a labeled dataset (the paper uses the NQ dataset). Then the judge model evaluates these generated answers by comparing them against the ground-truth dataset. The judge’s output is converted into a binary “Yes” or “No” label, creating a set of “silver labels” for training.
Next, the main LLM is fine-tuned on the dataset generated via the distilled “LLM-as-a-Judge” model. For models 7B or larger, this fine-tuning is done using adapters.
During inference, this fine-tuned model receives the user’s question. The authors use a “peek” technique. Given the user’s question, like “Who directed the movie Jaws?”, the LLM first runs in standard, non-RAG mode to generate the first 32 tokens of a potential answer, such as “Jaws was directed by Steven …”. The original query and this partial answer are then concatenated and fed to the same fine-tuned LLM. Now, the model’s task is to perform the classification. The softmax function is then applied to the logits of “Yes” and “No” tokens, and the resulting probability for the “Yes” token is used as the IK (“I Know”) score. This score value is compared against a predefined threshold to decide whether to trigger retrieval-augmentation.
Parameter-Efficient Fine-Tuning for the LLM to Decide When to Retrieve
In RAGate-PEFT, Wang et al.4 propose using Parameter-Efficient Fine-Tuning (PEFT) approach, specifically QLoRA, to adapt an LLM for determining the need for retrieval during conversations.
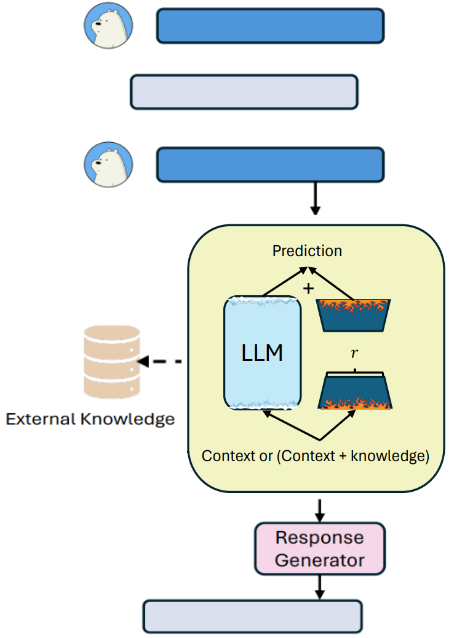
The authors source training data from the KETOD dataset, which already contains human labels indicating which specific turn in a conversation would benefit from being augmented with external knowledge. These human judgements serve as the ground truth label for the model’s training. They structured the data into instruction-input-output triplets.
- Instruction: This is simply a command describing the task (e.g., “Analyze this conversation and decide if you need external knowledge”)
- Input: Other than the conversational context (dialogue history), the authors experimented with several combinations to find the most effective one. They tested adding the system response, i.e., ground truth response for that turn (if available), synthetic response, named entities recognized within the incoming response, the actual text snippet retrieved from an external source, and a description of the external source (e.g., “WikiHow website”). The experiments showed that simply providing the conversational context along with a synthetic response (generated by a language model as a stand-in) and its named entities led to the best results.
- Output: The ground truth label (“True” or “False”) from the KETOD dataset.
The model’s predicted output (“True”, or “False”) directly controls whether the retrieval step is triggered or skipped for any given turn in the conversation.
Some disadvantages of this paradigm include the fact that it requires modifying the LLM itself, which has practical challenges. Fine-tuning large models can be computationally expensive and can lead to catastrophic forgetting, where the model’s general capabilities degrade after specialized tuning. The training data creation process can be complex, often requiring powerful teacher models or sophisticated labeling strategies to generate high-quality examples. It also requires access to model weights, making it incompatible with closed-source APIs.
In this section, we looked at ways to teach an LLM to make binary, “retrieve”, or “don’t retrieve” decisions. However, the models don’t explicitly plan multi-step information gathering or reason about what specific knowledge is missing. In the next section, we will look at a group of methods that not only recognize knowledge gaps but actively reason about how to fill them.
Paradigm 3: Teaching Reasoning About Retrieval
The final and most sophisticated paradigm teaches LLMs to articulate what information is missing, plan multi-step retrieval strategies, and iteratively refine their understanding as they gather knowledge. The LLM becomes an autonomous agent that decomposes complex queries, engages the retrieval system in a dialogue, evaluates retrieval information, and decides when it has gathered enough evidence to formulate the final answer.
Reasoning-based approaches offer several advantages due to their ability to handle complex, multi-hop questions that are difficult to answer with a single retrieval. They can recover from irrelevant retrievals by reformulating queries, demonstrating planning capabilities. The explicit reasoning traces also allow for interpretability.
Teaching LLMs to Leverage Reasoning for Retrieval as a Dialogue
In Auto-RAG, Yu et al.12 propose a framework to train an LLM to become an autonomous agent that itself decides both when and what to retrieve. For complex, multi-hop questions (see example in the next image), a single search is often not enough to gather sufficient knowledge. The authors argue that existing adaptive RAG methods overlook the LLM’s latent potential to use its own reasoning and decision-making abilities to plan its own retrieval strategy. Their Auto-RAG method uses the LLM’s reasoning ability to engage in a multi-turn dialogue with a retriever, systematically planning retrieval and refining queries until it has enough information to answer the user’s question.

The authors first create a specialized instruction-tuning dataset built starting from question-answer pairs from existing datasets like NaturalQuestions and 2WikiMultihopQA. Each example in the training data is a complete trace of a successful multi-step retrieval process. For this data creation, a powerful teacher LLM (Llama-3-8B-Instruct) guided by few-shot prompts is used to generate reasoning steps, while another model (Qwen1.5-32B-Chat) is used to create diverse rewritten queries. This process follows a Chain-of-Thought paradigm with three types of reasoning:
- Retrieval Planning: Given the user question and the current context, LLM identifies what knowledge is needed, assesses retrieved documents, and decides if another search is required.
- Information Extraction: LLM summarizes relevant information from the retrieved documents, effectively filtering out noise.
- Answer Inference: Once all the necessary information is collected, the LLM reasons through the facts to formulate the final answer.
The model first generates an initial reasoning $R_0$ given just the question. For multi-hop datasets, it iteratively generates multiple candidate queries and retrieves documents for each. The authors only keep the queries that contain sub-answers. At each step, the model generates new reasoning $R_t$ given the question, all previous retrievals, and current documents. Pre-defined trigger words like “However”, “no information”, and “find” are used to detect if more retrieval is needed. A final filtering is applied such that only the training examples where the final answer matches the ground truth are kept.
Turn 0: Input = Question $X$
Output = Reasoning $R_0$ + Query $Q_1$
Turn $t$: Input = Retrieved Documents $D_t$
Output = $R_t$ + Next Query $Q_{t+1}$ or Final Answer $A$
An LLM (Llama-3-8B-Instruct) is then fine-tuned on this dataset using a standard supervised learning objective. This training process teaches the model to autonomously generate the reasoning and actions needed for the iterative retrieval.
During inference, the fine-tuned model takes the user’s question and generates initial reasoning. Based on that reasoning, it decides whether to output a query for the retriever or to directly generate the final answer. If retrieval is used, it assesses the retrieved documents, generates further reasoning, and decides whether to continue the retrieval cycle or generate the final answer. The code for AutoRAG is available on GitHub.
Calibrate LLMs to Make Atomic Decisions
Guan et al.17 argue that while iterative ARAG methods like Auto-RAG teach a model to engage in a multi-turn dialogue with a retriever, they can struggle with ineffective task decompositions or fall into continuous retrieval loops when no relevant information is found. These redundant retrieval attempts can introduce noise, ultimately degrading the quality of the final response. The challenge is to teach a model to break down a complex query into a coherent, step-by-step reasoning process and make the retrieval decision for each step.
To address this, the authors propose a framework called DeepRAG that models the entire retrieval-augmented reasoning process as a Markov Decision Process (MDP). This approach enables an LLM to iteratively decompose a query into atomic subqueries and make a dynamic ‘atomic decision’ at each step about whether to retrieve external knowledge or rely on its own parametric memory.
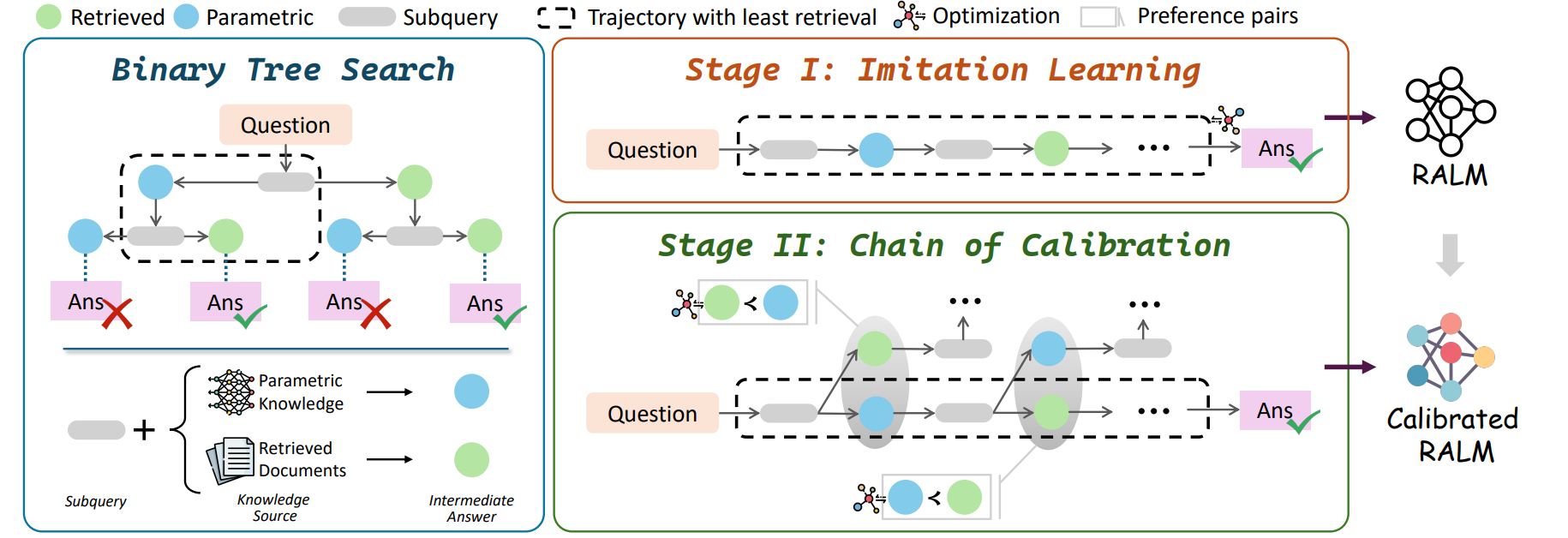
Data Synthesis
To create the training dataset, DeepRAG starts with a supervised QA dataset (like HotpotQA) and generates its specialized data via a two-stage synthesis process built on Binary Tree Search.
-
Creating Optimal Paths for Imitation Learning: For any given question, the framework explores all reasoning paths. At each step, a subquery is generated, creating two branches:
- Parametric Path: The model attempts to answer the subquery using only its internal knowledge.
- Retrieval Path: The model retrieves external documents to answer the subquery.
A priority queue is used to manage this search. This queue is prioritized by the number of retrieval steps, ensuring that it always explores the path with the fewest retrievals first. The first path that reaches the correct final answer is therefore selected as the ‘optimal reasoning process’, and the corresponding sequence of subqueries, atomic decisions, intermediate answers, and the final answer becomes one training data point. The question is discarded if no path leads to a correct answer.
-
Creating Preference Data for Calibration: After the model is trained on the data created in the first stage, a second dataset is created to fine-tune the model’s decision-making ability. For a given question, the stage 1 model finds the optimal path (one with minimal retrieval) again. A ‘preference pair’ is created for each subquery along this path. This pair consists of two possible outcomes: using retrieval and using parametric memory. The outcome that was also a part of the optimal path is labeled as the preferred choice. This dataset is intended to teach the model which action was better for a specific subquery given in a given context.
Model Training
The training process uses the synthesized data to fine-tune the LLM in two stages.
- Imitation Learning: The synthesized optimal paths dataset is used to teach the model to mimic the optimal reasoning process. It follows a standard next-token prediction objective with a masked loss function. The text of the retrieved document is masked out to prevent the model from learning to simply copy noisy or irrelevant text. This improves the model’s ability to learn the high-level reasoning structure rather than superficial textual patterns.
- Chain of Calibration: The model from the previous stage is further fine-tuned using the preference data. This stage follows a Chain of Calibration objective. For each subquery, an objective function encourages the model to assign a higher probability to the ‘winning’ response (either the parametric answer or the retrieved answer) from the preference pair. This step directly trains the model to make accurate judgements about its own knowledge boundary and whether it needs to retrieve information at each step.
The code for DeepRAG is available on GitHub.
Incorporate Knowledge Verbalization When Retrieval Is Skipped
Wu et al.18 argue that existing Adaptive RAG (ARAG) methods underutilize the LLM’s inherent knowledge. Most of these methods make a binary choice: retrieve from an external source or the model’s internal knowledge. However, when retrieval is skipped, they directly use the LLM to generate the final answer. The authors recommend that the model first verbalize its own knowledge before generating a final response. Their framework, SR-RAG (Self-Routing RAG), fine-tunes the LLM to act as a smart router that can dynamically choose between retrieving from an external corpus or verbalizing its own parametric knowledge. It is a generalization of ARAG methods that treats the LLM itself as a first-class knowledge source.
The hypothesis here is that the knowledge verbalization expands the LLM’s capacity to answer without retrieval, especially for complex queries where naive retrieval methods may return irrelevant results and a compute-intensive retrieval may return noisy context. Knowledge verbalization helps characterize the LLM’s capabilities, allowing for more accurate retrieval decisions and better final answers.
For creating training data, the framework follows both potential knowledge sources for a given question. It retrieves context chunks from the external source (e.g., Wikipedia) and uses the GenRead technique in parallel to prompt the LLM to generate the correct answer. The source (either <Wiki> or <Self>) that provides the majority of the top-scoring snippets is designated as the preferred source for the training example.
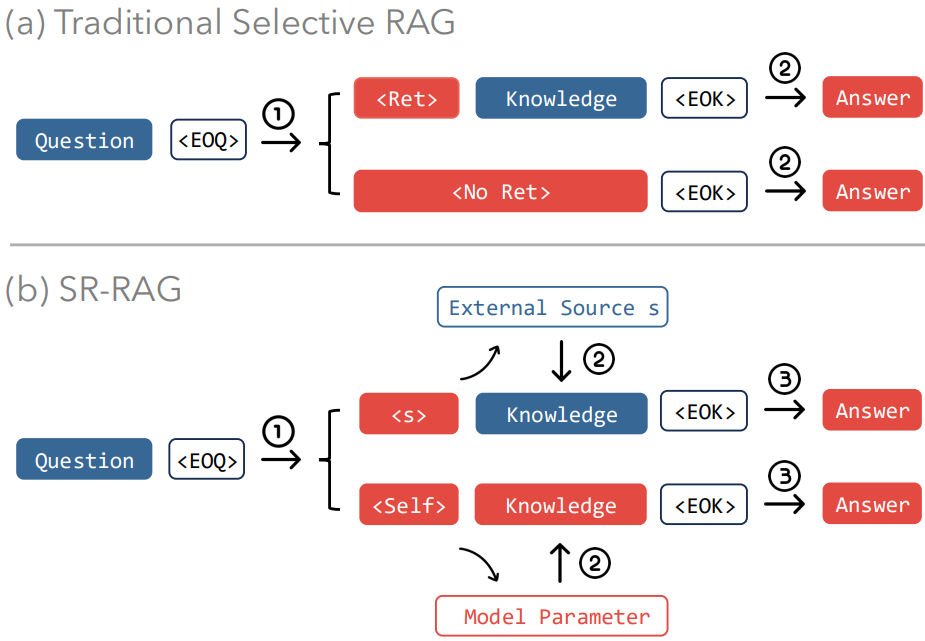
The LLM is then fine-tuned on this data using a multi-task objective that simultaneously optimizes for three skills (with a separate loss function for each):
- Source Selection: Learning to predict the special token for the preferred source (
<Wiki>or<Self>) right after the user’s query. - Knowledge Verbalization: If the preferred source is
<Self>, the model learns to generate the most helpful knowledge verbalization it produced during the data generation step. - Answer Generation: Learning to generate the final answer conditioned on the knowledge from the preferred source.
The training prompt format is shown below. Here <s> is the special token for source (<Wiki>, <Self>, etc.), {Knowledge} is the verbalized or retrieved text, <EOQ> and <EOK> are the special tokens for marking the end of query and knowledge, respectively.
Question: {question} Background knowledge:
<s> {knowledge}
The authors also propose using Direct Preference Optimization (DPO) to teach the model to prefer its most helpful verbalization over its least helpful ones, refining its own internal knowledge generation capability.
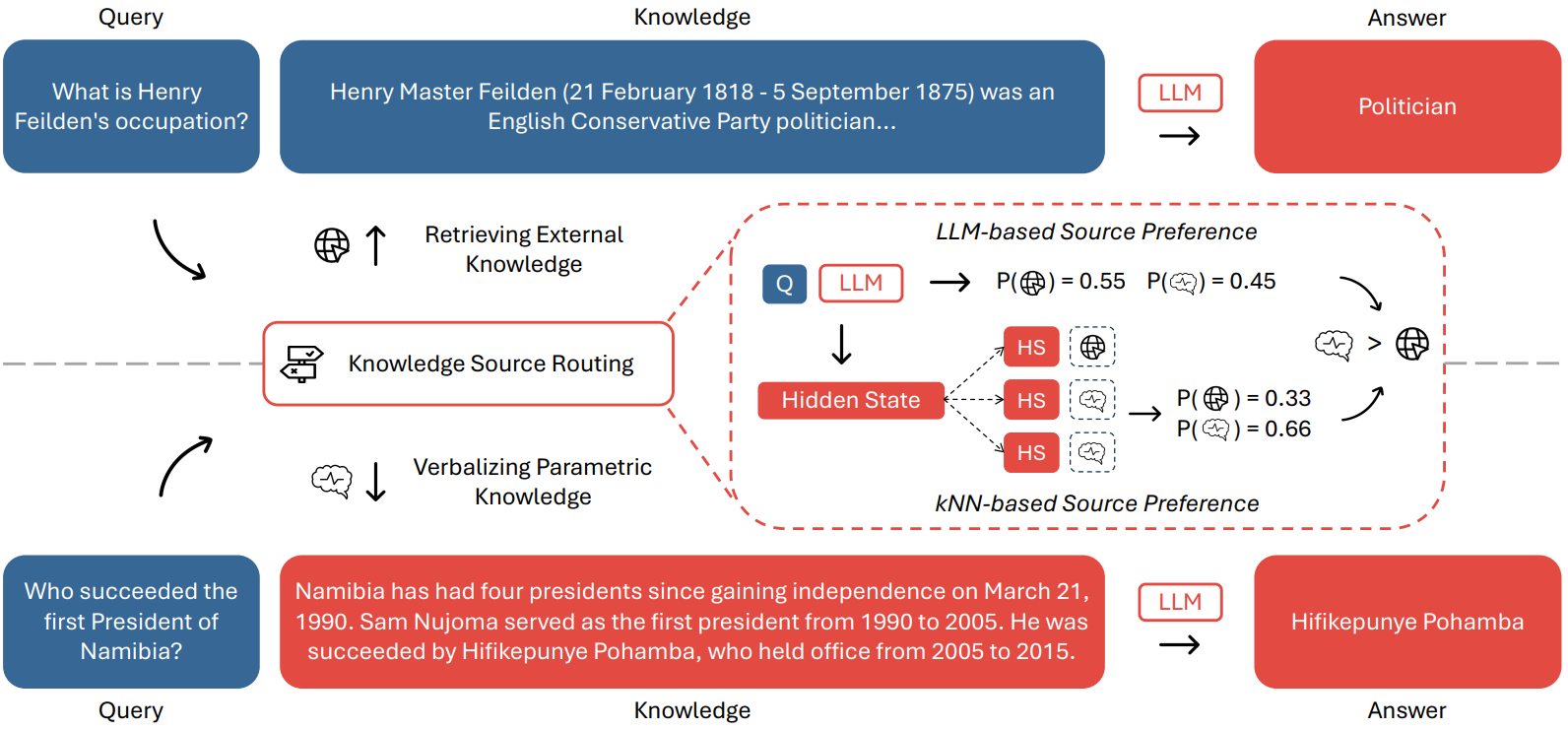
During inference, the authors propose using a Nearest Neighbor-Enhanced Source Selection mechanism instead of just picking the source with the highest probability. This method creates a “policy datastore” ahead of time. This datastore maps the hidden representation of the <EOQ> token for a given question to its preferred knowledge source. When a new query comes in, the model finds the k nearest neighbors from the datastore based on the similarity of their <EOQ> hidden states. The final source selected is based on a threshold applied to the product of the model’s predicted probability and the distribution from the nearest neighbors. This inference approach makes the retrieval decision more robust to domain shifts and shifts in LLM abilities due to fine-tuning.
The sophistication of the reasoning-based paradigm comes at substantial costs. Training these models requires carefully crafted, comprehensive datasets with annotated reasoning chains, which are expensive to create. The model needs to not just learn when to retrieve but also query formulation, information extraction, and reasoning strategies, thereby risking catastrophic forgetting. Inference is also significantly more expensive, as the model engages in multi-turn interactions with the retrieval system, generating intermediate reasoning steps and processing multiple retrieved documents.
Summary
This final piece of the Adaptive RAG series covered three paradigms for training-based approaches to adaptive retrieval. We saw how Gatekeeper models offer operational simplicity and modularity but make decisions with limited information. If you are using closed-sourced LLMs or need a quick solution, gatekeeper models provide a practical starting point. Fine-tuned LLMs leverage the model’s internal knowledge for more accurate decisions, but require expensive training and model access. If you have resources to fine-tune and want higher decision quality, this approach has great potential. While Reasoning-based approaches handle complex queries through multi-step planning, they also demand substantial training setup and inference costs. If you are tackling complex, multi-hop queries and can afford the investment, these approaches represent the current frontier of adaptive retrieval.
graph TD;
A{Using Closed-Source API?} -->|Yes| B{Latency Critical?}
A -->|No| C{Have Training Resources?}
B -->|Yes| D[Prompt Engineering
or External Features]
B -->|No| E[Consistency Sampling
or Lightweight Classifier]
C -->|No| F[Token/Internal State
Probing]
C -->|Yes| G{Query Complexity?}
G -->|Simple/Single-hop| H[Fine-tune LLM
with binary decision]
G -->|Complex/Multi-hop| I[Reasoning-Based
Iterative Retrieval]
style D fill:#90EE90
style E fill:#FFD700
style F fill:#87CEEB
style H fill:#FFA07A
style I fill:#FF6347
Series Conclusion: The Path From Naive to Autonomous RAG
In this series, we went from identifying the fundamental flaws in naive RAG to exploring progressively more intelligent solutions. Indiscriminate retrieval is costly and often counterproductive, while adaptive retrieval methods help in building reliable and trustworthy systems. We started with simple heuristics, moved to probing model confidence, and have now concluded with methods that empower the model with learned retrieval skills. The choice of which paradigm to adopt depends on the trade-off between implementation complexity, computational cost, and the required depth of reasoning for a given application. There is a clear evolution moving from static, one-size-fits-all towards dynamic, context-aware, autonomous systems. As the research continues and LLMs grow in capability and scale, the line between the “retriever” and “generator” will likely blur.
References
-
Jeong, S., Baek, J., Cho, S., Hwang, S. J., & Park, J. C. (2024). Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. ArXiv. ↩︎ ↩︎
-
Cheng, Q., Li, X., Li, S., Zhu, Q., Yin, Z., Shao, Y., Li, L., Sun, T., Yan, H., & Qiu, X. (2024). Unified Active Retrieval for Retrieval Augmented Generation. ArXiv. ↩︎ ↩︎
-
Zeng, S., Zhang, J., Li, B., Lin, Y., Zheng, T., Everaert, D., Lu, H., Liu, H., Liu, H., Xing, Y., Cheng, M. X., & Tang, J. (2024). Towards Knowledge Checking in Retrieval-augmented Generation: A Representation Perspective. ArXiv. ↩︎
-
Wang, X., Sen, P., Li, R., & Yilmaz, E. (2024). Adaptive Retrieval-Augmented Generation for Conversational Systems. ArXiv. ↩︎ ↩︎
-
Zhang, Z., Wang, X., Jiang, Y., Chen, Z., Mu, F., Hu, M., Xie, P., & Huang, F. (2024). Exploring Knowledge Boundaries in Large Language Models for Retrieval Judgment. ArXiv. ↩︎
-
Guo, H., Zhu, J., Di, S., Shi, W., Chen, Z., & Xu, J. (2025). DioR: Adaptive Cognitive Detection and Contextual Retrieval Optimization for Dynamic Retrieval-Augmented Generation. ArXiv. ↩︎
-
Tang, X., Gao, Q., Li, J., Du, N., Li, Q., & Xie, S. (2024). MBA-RAG: A Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity. ArXiv. ↩︎
-
Tan, J., Dou, Z., Zhu, Y., Guo, P., Fang, K., & Wen, J. (2024). Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs. ArXiv. ↩︎
-
Asai, A., Wu, Z., Wang, Y., Sil, A., & Hajishirzi, H. (2023). Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. ArXiv. ↩︎
-
Ding, H., Pang, L., Wei, Z., Shen, H., & Cheng, X. (2024). Retrieve Only When It Needs: Adaptive Retrieval Augmentation for Hallucination Mitigation in Large Language Models. ArXiv. ↩︎
-
Wang, R., Zhao, Q., Yan, Y., Zha, D., Chen, Y., Yu, S., Liu, Z., Wang, Y., Wang, S., Han, X., Liu, Z., & Sun, M. (2024). DeepNote: Note-Centric Deep Retrieval-Augmented Generation. ArXiv. ↩︎
-
Yu, T., Zhang, S., & Feng, Y. (2024). Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models. ArXiv. ↩︎ ↩︎
-
Labruna, T., Campos, J. A., & Azkune, G. (2024). When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively. ArXiv. ↩︎
-
Roy, N., Ribeiro, L. F., Blloshmi, R., & Small, K. (2024). Learning When to Retrieve, What to Rewrite, and How to Respond in Conversational QA. ArXiv. ↩︎
-
Cocchi, F., Moratelli, N., Cornia, M., Baraldi, L., & Cucchiara, R. (2024). Augmenting Multimodal LLMs with Self-Reflective Tokens for Knowledge-based Visual Question Answering. ArXiv. ↩︎
-
Déjean, H. (2024). Let your LLM generate a few tokens and you will reduce the need for retrieval. ArXiv. ↩︎
-
Guan, X., Zeng, J., Meng, F., Xin, C., Lu, Y., Lin, H., Han, X., Sun, L., & Zhou, J. (2025). DeepRAG: Thinking to Retrieve Step by Step for Large Language Models. ArXiv. ↩︎
-
Wu, D., Gu, J., Chang, K., & Peng, N. (2025). Self-Routing RAG: Binding Selective Retrieval with Knowledge Verbalization. ArXiv. ↩︎
Related Content





Did you find this article helpful?