The Hidden Costs of Naive Retrieval: Adaptive RAG, Part 1

Large Language Models (LLMs) have shown remarkable abilities in a wide range of Natural Language Processing (NLP) tasks, such as language generation, understanding, and reasoning. During training, LLMs can encode a massive amount of world knowledge in their parameters, which helps them excel at knowledge-intensive tasks, such as open-domain or factoid question-answering, that require memorizing factual knowledge. Despite their success, LLMs often generate outputs that are factually incorrect or suffer from temporal degradation 1.
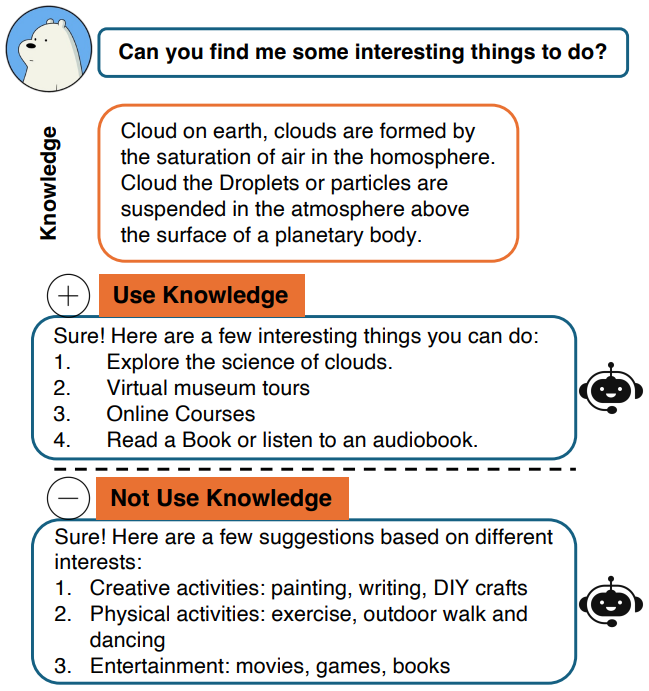
Retrieval Augmented Generation (RAG) strategy allows for incorporating non-parametric relevant knowledge from external sources to reduce reliance on parametric knowledge. But it is unclear whether it is strictly superior or complementary to parametric knowledge 1. This series of posts introduces a group of methods that determine whether LLMs need external knowledge for generation and invoke retrieval accordingly. These methods are sometimes also called Selective Retrieval, or Adaptive RAG. The goal is to understand when to utilize external retrieval and when to prompt the LLM to directly generate output.
What Is RAG and How Does It Help?
The Retrieve-Then-Read Paradigm: A typical RAG pipeline usually follows a “retrieve-then-read” paradigm. A retriever fetches query-relevant documents from an external corpus and feeds them as context to an LLM (“reader”), which is asked to generate a final answer 2. The retriever can recall relevant documents using sparse vector-based methods such as TFIDF and BM25, or dense-vector-based approaches like DPR and Contriever 3. The retrieval step often includes several components, such as a query rewriter that refines the initial query, and a filer or a reranker that ensures only the most relevant knowledge is kept4. The goal for the reader module is to then understand the retrieved text and infer the correct answer. Over the last few years, fine-tuned pretrained models built on the transformer architecture, and more recently, large language models have been utilized as the reader. LLM predictions grounded on relevant knowledge pieces from external sources help in generating a reliable answer.
A brief introduction to RAG: Given a user query q, the goal of a QA language model $\text{LM}$ is to generate answer $\bar{a}=[s_1,s_2,\dotsc,s_m] = [w_1,w_2,\dotsc,w_n]$ containing m sentences or n tokens, i.e. $\bar{a}=\text{LM}(q)$. Ideally, $\bar{a}$ should match the correct answer $a$. In this retrieval-free setup, larger language models (LLMs) with a high number of parameters can handle easy queries efficiently. However, this approach may become insufficient for queries that require information outside of LLMs’ internal knowledge.
To address this, we can retrieve relevant documents $d_q=R(q)$ from document corpus $D={d_i}_{i=1}^{|D|}$ or from web via a retriever $R$. After the retrieval step is done, we now have a pair of query $q$ and its relevant documents $d$. To augment LLMs with this retrieved knowledge, we can incorporate it into the input of LLMs, for example, by concatenating $d_q$ with $q$ to aid the answer generation as $\bar{a}=\text{LM}([q; d_q])$ where $[.;.]$ denotes concatenation. This process supplies the supplementary context that the internal knowledge of LLM lacks.
LLMs’ Internal Knowledge May Fall Short
Limits of scale
Several research works have shown that LLMs’ parameters implicitly store linguistic or factual knowledge. Relying on parameters for encoding a wealth of world knowledge requires a prohibitively large number of parameters. Meaning that even though improving the model’s capacity via scaling is a viable way to increase the amount of internal knowledge, it also leads to significantly large computational costs with increased model size.
Knowledge cut-off
Other than the model scale, LLMs’ knowledge is naturally limited by the information contained in pretraining and finetuning datasets. As these datasets are usually fixed once collected, the knowledge they contain is also frozen in time and incomplete. In continuously increasing information environments, a lot of this knowledge gets outdated, and it becomes challenging for static LLMs to factually answer questions out of their known knowledge.
In an experiment at Alibaba 5, researchers categorized open-domain questions into three categories: fast-changing, slow-changing, and never changing based on the frequency of temporal changes to corresponding information. They found that the LLM’s performance on the fast-changing and slow-changing categories of questions was suboptimal.
Hallucinations undermine reliability
As a result of outdated and incomplete knowledge, LLMs find it difficult to know they do not possess certain knowledge and often provide specious outputs that are factually inaccurate, even if they look plausible. This phenomenon, called hallucinations, can lead to users’ distrust in LLM-based information retrieval systems, posing significant risks to their real-world production deployments.
Retrieval-Augmented Generation (RAG) has been extensively studied to overcome these limitations by retrieving relevant non-parametric knowledge from external sources. Fusing this external information with the encoded knowledge of LLMs can lead to more accurate and reliable LLM responses when dealing with knowledge-intensive tasks.
RAG conditions generation on retrieved evidence
Decoupling specialized knowledge from model parameters
Retrieval Augmented Generation (RAG) is a cost-effective approach to expand LLMs’ access to a vast amount of information. It typically operates in two stages: retrieval and generation.
- In the retrieval stage, relevant information is retrieved from external databases and information retrieval mechanisms based on the user query.
- During generation, the retrieved information is integrated with the original user query to form an input for LLMs to generate responses.
Conditioning the generation stage on retrieved evidence can lead to more accurate and reliable LLM responses. The ability to retrieve specialized non-parametric knowledge helps make LLMs adaptable to different domains. It also helps with incorporating up-to-date information and reducing hallucinations without altering LLM weights or fine-tuning.
Competitive Performance on Open-domain Question Answering
In a closed-book question-answering strategy, information retrieval models solely rely on their parametric knowledge. For example, with LLMs for question-answering, this strategy involves approaches like instruction tuning and few-shot prompting. However, in real-world scenarios, natural language questions can span various topics, unstated domain knowledge, and require complex reasoning. Open-domain question-answering (ODQA) strategy allows models to consult external sources for grounding, by augmenting the input with relevant knowledge chunks retrieved from structured or unstructured external datastores 6. Several research works have shown that retrieval-augmented methods generally improve QA performance when compared with methods without using retrieval 4 7 8 9.
Improved Performance on Long-tail Questions
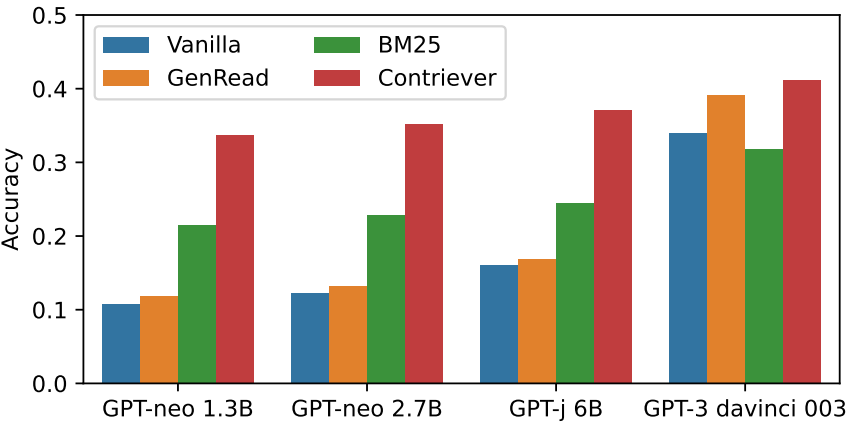
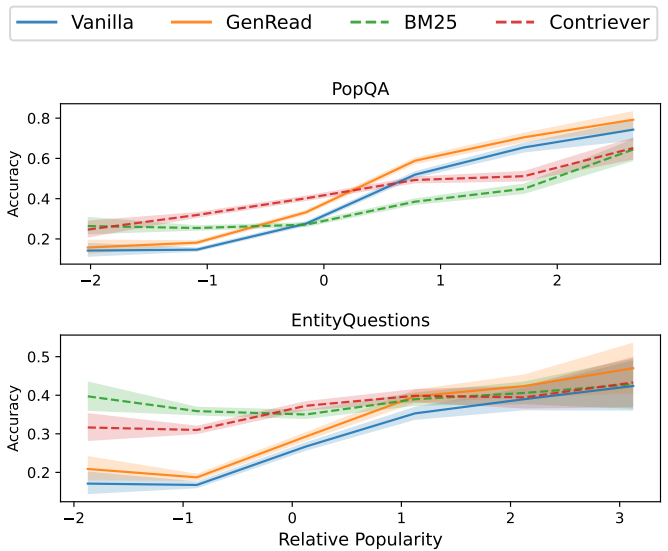
Mallen et al.1 showed that factual knowledge that is frequently discussed on the web can be easily memorized by language models. Whereas LMs benefit from retrieving external non-parametric memories to correctly answer questions regarding entities that are less discussed. Even scaling up the models does not significantly improve the performance. The authors constructed a new QA dataset, PopQA, consisting of factual information in the long-tail using Wikipedia page views as a measure of popularity. They used off-the-shelf BM25, Contriever retrievers, and a parametric augmentation method called GenRead on the PopQA dataset, and found that augmenting LMs led to significant performance improvement. While scaling lowered the popularity threshold for the knowledge to be memorized, the majority of the corresponding gains came from highly popular knowledge. Interestingly, they also found that the retrieved results may not always be correct or helpful, and can mislead the LMs.
Additionally, in real-world scenarios, a user may intend to seek a verifiable answer that requires external information sources, hence necessitating retrieval 10.
Why RAG Isn’t Always Useful?
Several studies have shown that retrieval may not always be beneficial. Failing to consider the usefulness of factual grounding may result in suboptimal task performance and increased inference costs.
The Practical Problems of Efficiency and Cost
Additional Context Simply May Not Be Necessary
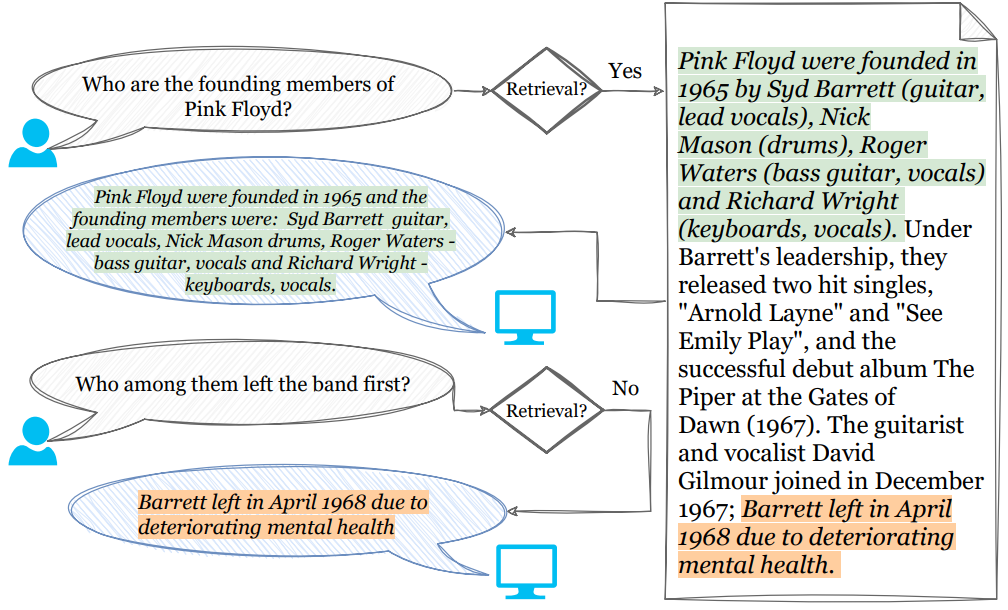
It may not be necessary to conduct a retrieval for every question at hand. LMs’ parametric knowledge may be sufficient to answer simple questions like, “What is the capital of France?”. Additionally, in multi-turn scenarios, retrieved passages may conflict with the information in passages retrieved previously. Since in multi-turn conversations, user questions often refer to responses in previous turns, it may not be necessary to retrieve new passages to answer every follow-up question 11. Tan et al.4 conducted an experiment on Llama2-7B-Chat with the ELI5 dataset and found that approximately 66.5% of samples show improvement with retrieval.
Additional Overhead
In RAG-based pipelines, the performance is highly dependent on the quality of the retriever. Developing custom retrieval modules generally requires extensive work for creating question-answer pairs and significant computational resources, especially when dealing with massive data sources 6. For complex tasks, such as long-form question answering, multi-hop reasoning, chain-of-thought reasoning, etc, multiple rounds of retrieval augmentation may be required 8. For simple queries, a multi-step retrieval could be unnecessarily expensive. Retrieved fragments may also be biased, incomplete, or not tailored to the query. Unnecessary retrieval not only jeopardizes the quality of outputs, but also introduces additional overhead, increases response latency, and computation cost of LLM inference (due to longer prompts). So, it may not be optimal to conduct retrieval-augmentation for all queries.
Retrieval for Popular Knowledge Might Be Harmful
As discussed earlier, Mallen et al.1 found that incorporating non-parametric memories improves performance on long-tail questions across models, when subject entities are not popular. However, large language models have likely memorized factual knowledge for popular entities, so retrieval augmentation for them can degrade performance when the retrieved context is noisy. Their experiments showed that for passages retrieved with low recall@1 scores, retrieval-augmented models struggled with more popular entities, leading to LMs incorrectly answering 10% of questions they could otherwise answer correctly unassisted.
The Hidden Dangers to Quality and Trust
Retrieved Context Can be Misleading or Incomplete
Retrieved results may not always be correct or even helpful. Especially for complex queries, naive retrieval methods can return irrelevant results, while compute-intensive retrieval methods may return noisy contexts. Handling sparse or underspecified queries (concise user inputs with limited contextual signals) is also a central challenge in RAG, and can often lead to the retrieval of irrelevant or low-quality documents. Indiscriminately retrieving and always incorporating a fixed number of retrieved passages can distract LMs and diminish their versatility.
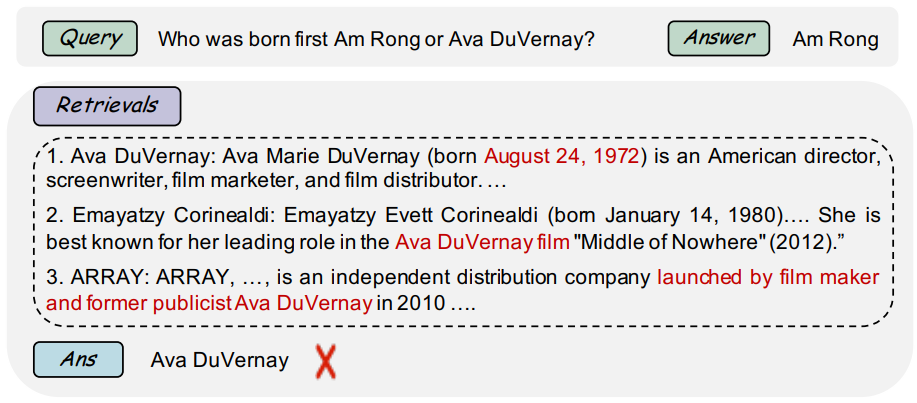
Irrelevant, conflicting, unnecessary, or off-topic passages that do not help with factual grounding may lead to low-quality generations 12. Malicious actors may inject false information into the retrieval database to manipulate LLMs. Also, context that is semantically similar to the query may only superficially relate to the topic 13. Such noisy contexts can hurt RAG performance 14.

Interestingly, Wang et al.15 also identified two categories of “information-heavy domains” where retrieval is essential.
-
Domains Requiring Making Suggestions: Domains like travel, hotels, trains, flights, services, and car rentals inherently require additional information. Meaning that for applications that help users in booking appointments, comparing products in e-commerce, checking inventory, or finding local services, retrieval is non-negotiable.
-
Domains Requiring Enriched Descriptions: Domains like movies, music, media, and events often include entities to which retrieval can enrich factual depth. So, for applications dealing with named entities like a technical support bot explaining a product feature, or a system describing a specific medical condition, etc., retrieval ensures that the answers are detailed and trustworthy.
Whereas user intents that rely on a language model’s inherent creativity and reasoning capabilities, and a vast amount of general knowledge, can benefit from skipping the retrieval step entirely. So, looking up a knowledge base may not be necessary to answer questions like, “Write a short poem about the summer season in the city of Seattle.”, “What are some of the common ways to destress after work?”, “Summarize this email: [email text]”, “Translate this into Japanese: [text]”.
Similarly, in a conversational system, a strategy that invokes retrieval augmentation at every turn of system responses may unnaturally drive and shift the conversation to non-relevant topics 15.
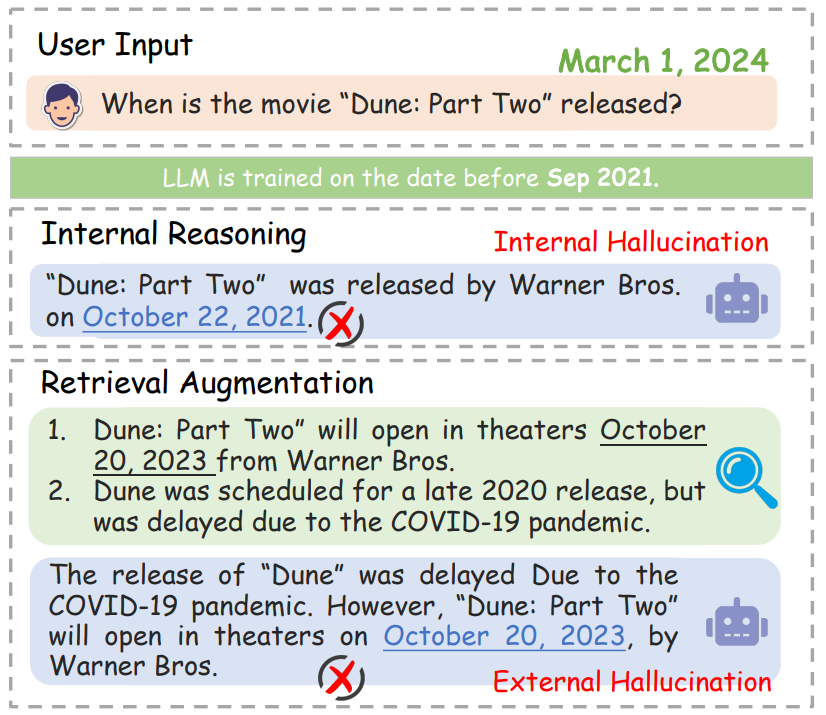
“External Hallucinations”
When relying solely on parametric knowledge, LLMs may generate seemingly plausible but inaccurate answers, for example, with the latest or domain-specific questions, because of their knowledge boundaries. This phenomenon is called Internal Hallucination. Incorporating external information can help fill these gaps in knowledge. However, if irrelevant evidence seeps into the generation process, it may lead to cumulative errors and compromise output accuracy 9. Generating non-factual responses because of such noisy context is also referred to as External Hallucination. Several research works have shown that LLMs often struggle to identify the boundary of their own knowledge and tend to prioritize external information over their internal knowledge learned during pretraining 13. Hence, they may generate incorrect outputs due to external hallucinations, even if their parametric knowledge would have been enough to accurately answer the question 16.
RAG’s Impact Varies by Task and Model Confidence
In Zhang et al.5, researchers at Alibaba found that the impact of RAG on the question-answering capabilities of LLMs can be categorized as beneficial, neutral, or harmful. Through experimentation, they identify specific scenarios where retrieval does not add value or might even be harmful.
-
When RAG Is Neutral:
-
When LLM Is Already Confident and Correct: Neutral cases peak when the LLM’s accuracy is already very high (in the 0.8 - 1.0 range). If the model already has a significant context and can answer correctly with high confidence, retrieving and adding external context provides no additional benefit.
-
For Certain Task Formats: RAG provides minimal performance improvement in tasks such as multiple-choice questions and math assessments. This suggests that retrieval has no effect for tasks that rely on internal reasoning or specific formats rather than descriptive facts.
-
-
When RAG Is Harmful:
-
When the LLM Is Highly Confident: Similar to neutral cases, harmful cases were also found to be concentrated in the high-confidence (0.8 - 1.0] accuracy range. A likely reason is that providing potentially noisy context can confuse a model that is already sure of the answer.
-
When the Context Is Noisy and the Model Is Small: The study found that RAG becomes counterproductive when relevant information is difficult to retrieve or noisy. This negative effect is more severe for smaller models, while larger models are more resilient to noise. Notably, with an increase in the number of model parameters, the tendency to copy answers from RAG inputs (as opposed to absorbing knowledge from the provided context) decreases.
-
By minimizing retrieval requests that yield neutral or harmful results, we can improve the performance of the system without compromising performance. So we should find ways to decrease the retrieval ratio without compromising performance.
The Foundational Flaws of the Paradigm
Performance on Wikipedia Doesn’t Necessarily Translate to the Wild
While RAG has shown strong performance in various studies, the impressive results often come from benchmarks that are predominantly constructed from Wikipedia or closely aligned with Wikipedia. This creates an idealistic scenario where the retrieval corpus is clean and well-aligned with the questions. However, real-world applications are far more challenging. Enterprise knowledge bases are often a mix of noisy, domain-specific, misaligned, and stylistically diverse sources. The “RAG in the Wild” study by Xu et al.17 simulated such real-world conditions using MASSIVEDS, a large-scale, multi-domain datastore. Their findings suggest that the effectiveness of RAG is likely overestimated by Wikipedia-like evaluations.
The “Retrieval Advantage” May Shrink Drastically With Model Scale
Smaller models achieve substantial performance gains via RAG due to their limited capacity to store knowledge internally. As LLMs become larger and more capable, they internalize a vast amount of knowledge, making external retrieval less impactful for anything other than highly specific, fact-checking queries. Xu et al.17 conducted a study that found while retrieval provides substantial gains for smaller LLMs (e.g., Llama-3.2-3B), these benefits diminish significantly as the model size increases (e.g., Qwen3-32B, GPT-4o). For the largest models, the improvement from RAG was marginal and sometimes even negative, except on tasks that are purely about factual recall (such as the SimpleQA dataset). It’s important to note that this study focused on question-answering tasks with short-form answers, so these findings might not apply to other scenarios like long-form reasoning.
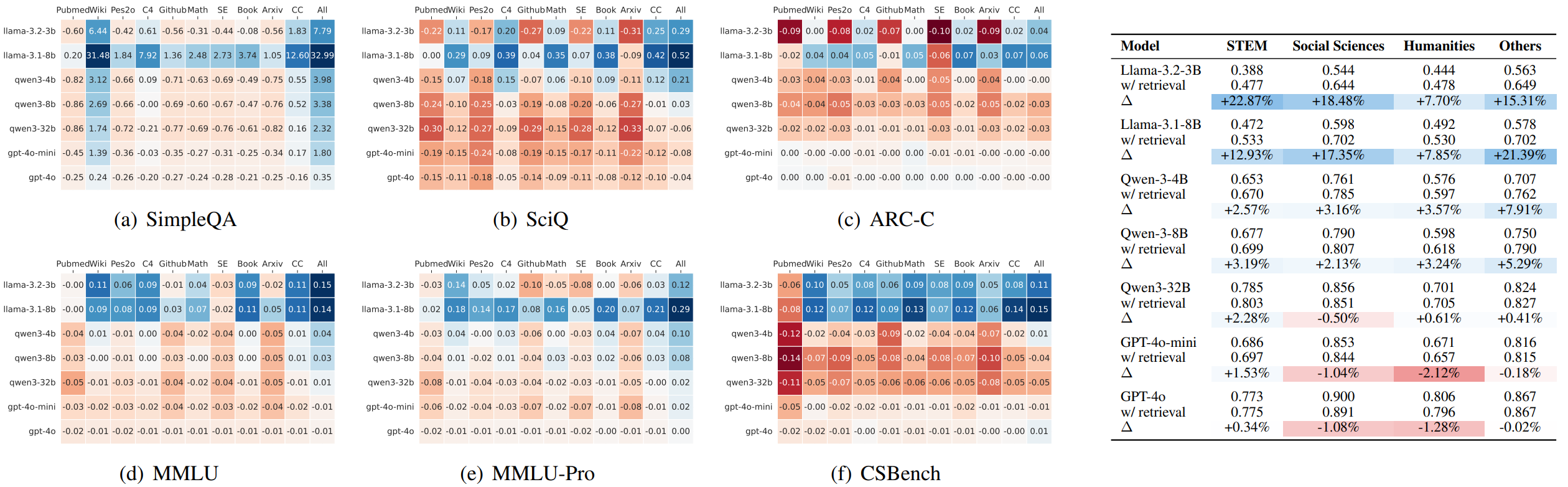
The authors also found that the diminishing returns are not solely due to retrieval quality, as even adding sophisticated rerankers only offers marginal improvements. This suggests deeper integration challenges between the retrieval and generation stages.
Most Language Models Don’t “Talk” to Retrievers
In the conventional retrieve-then-read paradigm, the language model component isn’t trained to truly collaborate with the retriever. Most off-the-shelf language models excel at prompt compliance, but not at active, aware collaboration with the retrieval process. They do not query, verify, or “talk to” the external knowledge source. Therefore, their output responses are not guaranteed to be faithful or consistent with retrieved relevant passages since the models are not explicitly trained to leverage and follow facts from provided passages 12. An LLM can also be overconfident in its knowledge. Some studies that measured RAG’s impact on LLMs found that the ratio of neutral to harmful results increased as the LLM’s confidence or certainty increased 5.
In this section, we saw that simply retrieving knowledge without considering the question difficulty and the language models’ own capabilities may lead to inefficient or inaccurate responses. In the upcoming posts, we will go through several strategies to decide whether to retrieve for a given query. These adaptive retrieval methods significantly reduce unnecessary retrievals to enhance the RAG systems.
What’s Next
We have established that while the naive “retrieve-then-read” RAG paradigm is powerful, it also has several shortcomings. Indiscriminate retrieval can introduce noise, increase latency, and even harm the quality of the final response when an LLM’s parametric knowledge would have been enough. So, how can we build RAG systems that are more robust, adaptive, and self-aware?
The upcoming posts in this series will explore the Selective Retrieval domain, diving deep into the research and techniques designed to help systems dynamically decide when to retrieve. We will cover:
- Defining Adaptive Retrieval and Measuring Success: The next post will formally introduce Adaptive RAG and a framework to evaluate the Selective Retrieval systems. We will also look at the trade-offs between ARAG pipelines and classic uncertainty estimation techniques.
- A Taxonomy of Techniques: The next set of posts will categorize the major strategies for making the retrieval decision. We will explore:
- Confidence-based Triggers: Methods that probe an LLM’s internal states using signals like token probability, output entropy, and semantic consistency.
- Fine-tuned LLMs: Fine-tuning a model explicitly to “ask for help”, i.e., make the decision to invoke retrieval when required, for example, either by generating special tokens or by reasoning through a multi-step plan.
- External Gatekeepers: A group of methods that train lightweight classifiers to act as intelligent routers, assessing query complexity or the LLM’s knowledge before generation.
References
-
Mallen, A., Asai, A., Zhong, V., Das, R., Khashabi, D., & Hajishirzi, H. (2022). When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. ArXiv. ↩︎ ↩︎ ↩︎ ↩︎
-
Ni, S., Bi, K., Guo, J., & Cheng, X. (2024). When Do LLMs Need Retrieval Augmentation? Mitigating LLMs’ Overconfidence Helps Retrieval Augmentation. ArXiv. ↩︎
-
Wang, R., Zhao, Q., Yan, Y., Zha, D., Chen, Y., Yu, S., Liu, Z., Wang, Y., Wang, S., Han, X., Liu, Z., & Sun, M. (2024). DeepNote: Note-Centric Deep Retrieval-Augmented Generation. ArXiv. ↩︎
-
Tan, J., Dou, Z., Zhu, Y., Guo, P., Fang, K., & Wen, J. (2024). Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs. ArXiv. ↩︎ ↩︎ ↩︎
-
Zhang, Z., Wang, X., Jiang, Y., Chen, Z., Mu, F., Hu, M., Xie, P., & Huang, F. (2024). Exploring Knowledge Boundaries in Large Language Models for Retrieval Judgment. ArXiv. ↩︎ ↩︎ ↩︎
-
Frisoni, G., Cocchieri, A., Presepi, A., Moro, G., & Meng, Z. (2024). To Generate or to Retrieve? On the Effectiveness of Artificial Contexts for Medical Open-Domain Question Answering. ArXiv. ↩︎ ↩︎
-
Zhang, Z., Fang, M., & Chen, L. (2024). RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering. ArXiv. ↩︎
-
Su, W., Tang, Y., Ai, Q., Wu, Z., & Liu, Y. (2024). DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models. ArXiv. ↩︎ ↩︎
-
Labruna, T., Campos, J. A., & Azkune, G. (2024). When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively. ArXiv. ↩︎ ↩︎
-
Cheng, Q., Li, X., Li, S., Zhu, Q., Yin, Z., Shao, Y., Li, L., Sun, T., Yan, H., & Qiu, X. (2024). Unified Active Retrieval for Retrieval Augmented Generation. ArXiv. ↩︎
-
Roy, N., Ribeiro, L. F., Blloshmi, R., & Small, K. (2024). Learning When to Retrieve, What to Rewrite, and How to Respond in Conversational QA. ArXiv. ↩︎
-
Asai, A., Wu, Z., Wang, Y., Sil, A., & Hajishirzi, H. (2023). Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. ArXiv. ↩︎ ↩︎
-
Zeng, S., Zhang, J., Li, B., Lin, Y., Zheng, T., Everaert, D., Lu, H., Liu, H., Liu, H., Xing, Y., Cheng, M. X., & Tang, J. (2024). Towards Knowledge Checking in Retrieval-augmented Generation: A Representation Perspective. ArXiv. ↩︎ ↩︎
-
Cuconasu, F., Trappolini, G., Siciliano, F., Filice, S., Campagnano, C., Maarek, Y., Tonellotto, N., & Silvestri, F. (2024). The Power of Noise: Redefining Retrieval for RAG Systems. ArXiv. ↩︎
-
Wang, X., Sen, P., Li, R., & Yilmaz, E. (2024). Adaptive Retrieval-Augmented Generation for Conversational Systems. ArXiv. ↩︎ ↩︎
-
Zubkova, H., Park, J., & Lee, S. (2025). SUGAR: Leveraging Contextual Confidence for Smarter Retrieval. ArXiv. ↩︎
-
Xu, R., Zhuang, Y., Yu, Y., Wang, H., Shi, W., & Yang, C. (2025). RAG in the Wild: On the (In)effectiveness of LLMs with Mixture-of-Knowledge Retrieval Augmentation. ArXiv. ↩︎ ↩︎
Related Content





Did you find this article helpful?