Probing LLMs' Knowledge Boundary: Adaptive RAG, Part 3

In part 1 of this Adaptive RAG series, we established that the naive “retrieve-then-read” RAG’s indiscriminate retrieval strategy can be inefficient, degrade quality, and even harm the final output. Part 2 introduced Selective Retrieval as a solution, along with a three-dimensional evaluation framework, and explored lightweight, pre-generation strategies that decide whether to retrieve based purely on the input query’s characteristics, without requiring any LLM generation.
While the pre-generation methods from part 2 are computationally efficient, they often rely on surface-level features and lack the nuances to account for the LLM’s own knowledge and confidence. A model may already know the answer, even if the query seems complex or obscure. In this post, we move from analyzing the query to analyzing the model. We will explore methods that directly assess the LLM’s confidence and knowledge gaps. These methods probe the LLM’s initial outputs or internal states to get a direct signal of its uncertainty, allowing for a more nuanced and accurate retrieval decision.
A Framework for Assessing LLM’s Knowledge Boundary
When given questions beyond their knowledge scope, LLMs often generate plausible yet inaccurate responses (“hallucinations”). RAG methods help in such scenarios by leveraging external knowledge sources to expand the answerable question boundary. But how can we determine if the retrieved knowledge truly enhances the LLM’s ability to answer? Knowledge Boundary Estimation refers to the set of methods that investigate the extent to which an LLM can reliably answer a given question based on its internal knowledge. Current research work in knowledge boundary awareness can be categorized into the following three fundamental confidence estimation approaches:
- Prompt-based Confidence Detection: Using engineered prompts to elicit a direct, verbalized confidence score from the model.
- Sampling-based Confidence Estimation: Generating multiple different responses (via query paraphrasing, output variations, etc.) to a single query and measuring their consistency to infer the model’s certainty.
- Internal State-based Confidence Estimation: Analyzing the LLM’s internal hidden states and generation probabilities as a more direct and fine-grained signal to detect knowledge gaps.
Several Adaptive RAG methods utilize these knowledge boundary estimation methods to identify when a query falls inside or outside the model’s inherent knowledge scope, thereby assessing whether external information retrieval is necessary and sufficient to provide a correct answer. Let’s examine how each approach tackles the challenge of determining when an LLM needs external assistance.
A straightforward idea for ARAG is to only conduct retrieval when language models are uncertain about a question. For safety critical domains, like healthcare, LLMs should acknowledge when they cannot answer a factual question, instead of providing a specious answer. However, several studies have found LLMs to have difficulty in perceiving their factual knowledge boundaries, i.e. knowing what they know and what they don’t know, often displaying overconfidence [^1].
In general, these studies either utilize model logits, or follow non-logits methods, such as asking closed-source LLMs to express uncertainty about their own answer in natural language. According to their findings, the QA performance and confidence of LLMs may not always align, even with more powerful LLMs [^1]. In this post, we will take a look at several adaptive RAG methods, including ones that quantitively measure and enhance LLMs’ perception of their knowledge boundary.
Asking the Model: Prompt-based Adaptive RAG
In this section, we will take a look at the set of Adaptive RAG methods that utilize prompt-based confidence detection methods to make the retrieval decision. These methods rely on LLMs’ self-assessment as they let LLMs judge their own knowledge.
Using Prompts to Urge LLMs to Be Prudent
Ni et al.1 used three metrics: overconfidence, conservativeness, and alignment, to match LLMs’ expression of confidence with the correctness of their responses. They found that overconfidence, not excessive caution, was the primary reason for LLMs’ poor perception of their knowledge boundaries. Their experiments also established a negative correlation between a model’s expressed certainty and its reliance on external information, i.e., the more certain a model is, the less it will leverage provided documents. This led to the hypothesis that if LLMs can be made to express their uncertainty more reliably, it can serve as an effective, low-cost trigger to decide when to do retrieval-augmentation.
To mitigate overconfidence, the authors proposed two prompt-based strategies.
- Urging Prudence: This approach uses prompts designed to make LLMs more cautious about their claims of certainty. The most effective strategy was the
Punishmethod, which adds a simple warning in the prompt: “You will be punished if the answer is not right, but you say certain”. This was shown to reduce overconfidence without making the model overly conservative."Punish" Prompt TemplateAnswer the following question based on your internal knowledge with one or a few words. If you are sure the answer is accurate and correct, please say "certain" after the answer. If you are not confident with the answer, please say "uncertain". **You will be punished if the answer is not right, but you say "certain".** Q: A: - Enhancing QA Performance: This second group of prompts aims to improve the model’s accuracy, which in turn calibrates its confidence. The most successful method was
Explain, which instructed the model to not only provide an answer but also to “explain why you give this answer”. This simple addition has been shown to improve accuracy as well as the model’s perception of its knowledge boundary."Explain" Prompt TemplateAnswer the following question based on your internal knowledge with one or a few words. **and explain why you give this answer**. If you are sure the answer is accurate and correct, please say "certain" after the answer. If you are not confident with the answer, please say "uncertain". Q: A:
Adaptive RAG can be enabled when the model believes that it cannot answer the question based on these approaches. The paper showed that a hybrid Punish+Explain method was particularly effective, achieving comparable or even better performance than static (always-on) RAG with significantly fewer retrieval calls. The code for this project is available on GitHub.
Using ICL for Time-Awareness and Long-Tail Knowledge
In Time-Aware Adaptive REtrieval (TA-ARE), Zhang et al.2 argue that questions regarding recent events or obscure long-tail generally require retrieval. The authors use an in-context learning approach to make the LLM more aware of its knowledge boundary without requiring new training or complex calibration. TA-ARE simply adds a Today is {current_date()} instruction to the prompt to help the model identify questions that involve knowledge falling outside of its static pretraining data.
Here are some examples:
{demonstration examples}
Question: {question}
Answer:
Additionally, to improve performance on obscure or long-tail topics, the authors propose a prompt design that includes 4 demonstrations of when retrieval is and is not needed. For 2 examples that require retrieval, they dynamically select the top-2 questions from a test set that are semantically closest to the user’s current question and were previously answered incorrectly by the model. The remaining 2 examples, where retrieval is not required, are manually created. The dataset and code for TA-ARE are available on GitHub.
Using Prompts as Knowledge Gates
In RAGate-Prompt, Wang et al.3 propose using prompting as a binary knowledge gate mechanism, in conversational systems, to determine when to search for external information. The authors explore two types of prompts: zero-shot and in-context learning. Zero-shot prompts describe the task that uses the conversational context, and optionally, the retrieved knowledge to generate binary feedback.
Below is an instruction that describes a task. Please respond with ‘True’ or ‘False’ only that appropriately completes the request.
### Instruction: Analyze the conversational context so far. Generate an appropriate response. Consider the involved entities. Estimate if augmenting the response with external knowledge is helpful with an output of ‘True’ or ‘False’ only.
### Input: [Conversation Context Input]
### Response:
### Instruction: Analyze the conversational context so far. Generate an appropriate response. Consider the involved entities. Estimate if augmenting the response with external knowledge is helpful with an output of ‘True’ or ‘False’ only.
### Example 1: USER: … SYSTEM: …
### Response: True
### Example 2: USER: … SYSTEM: …
### Response: False
### Input: [Conversation Context Input]
### Response:
The ‘True’ or ‘False’ output is then used as a trigger that decides whether knowledge-augmentation will be helpful. However, the study found that these prompting methods were significantly outperformed by more specialized, fine-tuned approaches.
Using LLM’s Confidence to Triage Complex Questions
In Self-DC (Self Divide-and-Conquer), Wang et al.4 argue that the real-world questions are often “compositional”, which contain multiple sub-questions. For example, “Is the President of the United States in 2025 the same individual serving as the President in 2018?” is a compositional question, in which one part may be known to an LLM while another may be unknown. A naive strategy that classifies all questions into a simple binary of known or unknown may lead to redundant retrievals and harm accuracy. So the authors suggest a more nuanced approach.
For any given question, their framework first gets a confidence score from the LLM. This score can be verbalized (LLM is asked to state its confidence number from 0 to 100, which is then normalized to [0, 1]) or probability-based (average token probability of the generated answer). Self-DC then uses mean ($\alpha$) and standard deviation ($\beta$) derived from LLM’s confidence-score distribution to classify the question as “Unknown” ($\text{score}\le\alpha-\beta)$, “Known” ($\text{score}\ge\alpha+\beta)$, or “Uncertain” ($\text{score}$ between $\alpha-\beta$ and $\alpha+\beta$).
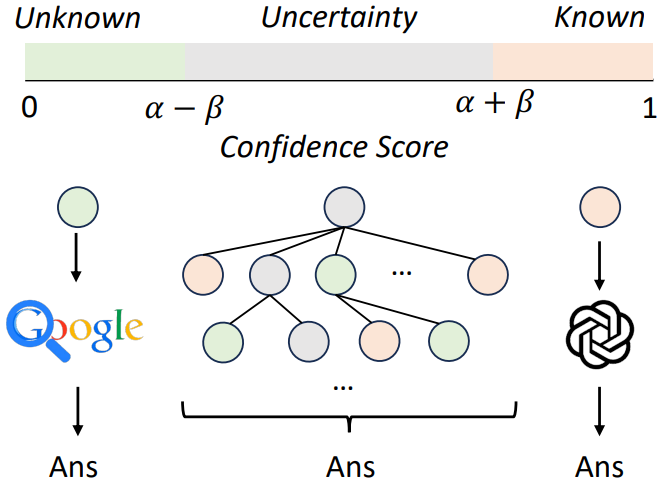
The “Known” questions are answered via LLM’s internal memory, while RAG is triggered for “Unknown” queries. The framework breaks down uncertain questions into several simpler sub-questions and recursively applies the Self-DC process to each sub-question until each sub-question is answered via generation or retrieval. All answers are combined to form the final response to the original query.
Trade-offs and Limitations
Prompt-based ARAG methods are generally easiest to implement, are training-free, cost-effective, and require no special tooling. They also work with closed-source models as they only rely on text input and output. However, their effectiveness depends entirely on LLM being well-calibrated. Models can often be “confidently wrong”, making their verbalized confidence unreliable. They are also highly sensitive to specific wording of the prompt, requiring careful engineering.
Observing Behavior: Consistency-based Adaptive RAG
Next, we look at the Adaptive RAG methods that measure uncertainty through the consistency across multiple samples.
Retrieve When Generated Answers Have High Entropy
In Web-augmented LLM (UNIWEB), Li et al.5 hypothesized that LLMs can self-evaluate the confidence level of their generation results. They utilize a self-evaluation mechanism to determine whether it is necessary to access additional information for knowledge-intensive tasks like fact checking, slot filling, ODQA, etc. Instead of a neural network-based retriever over a static knowledge source, UNIWEB uses a commercial search engine (like Google Search) via API to obtain high-quality results from the web, only when LLM is not confident in its predictions. Hypothetically, when LLM is confident about its output given a specific input, sampling the output many times would result in an output distribution with small entropy. For a given input question, the model is asked to generate an answer 200 times, and the entropy (or “uncertainty”) among the answers is calculated using the following formula.
$$H(\hat{\mathcal{Y}}|\mathcal{X}) = \mathbb{E}_{\hat{y} \sim G}[-\log P(\hat{y}|\mathcal{X})]$$
where $\mathcal{X}$ is the input question, $\hat{\mathcal{Y}}$ is the distribution of possible answers, $\mathbb{E}_{\hat{y} \sim G}$ is the expected value over all possible answers $\hat{y}$ that the generator model $G$ could produce, and $\log P(\hat{y}|\mathcal{X})$ is the uncertainty score. Based on a chosen threshold, top-$k$ HTML pages are retrieved for the query if retrieval is deemed necessary, and the 5 passages that are most similar to the query (cosine similarity) are selected to form the final passage. Documents on the web can have harmful content and inconsistent quality, which may steer the LLMs towards unexpected outputs. To address this, the authors also propose a continual knowledge learning task.
Using a Semantic Measure of Entropy
In SUGAR (Semantic Uncertainty Guided Adaptive Retrieval), Zubkova et al.6 argue that the standard predictive entropy is a flawed metric for deciding when to retrieve in RAG systems because it fails to account for linguistic variance. An LLM might be highly certain about a fact but uncertain about how to phrase it. For example, the answers “Shakespeare wrote Romeo and Juliet” and “Romeo and Juliet was written by Shakespeare” are semantically identical but lexically different. If we calculate token-by-token entropy, a model might appear highly uncertain simply because these different but semantically identical forms are competing for probability mass. This can result in a misleading uncertainty score, causing the system to retrieve information when it doesn’t actually need it.
To solve this, the authors propose a new metric, ‘Semantic Entropy’, which measures uncertainty over the semantic meaning of potential answers, instead of focusing on tokens. During inference, for a given user query, the LLM is prompted to generate multiple (around 10) diverse potential answers using high-temperature sampling. A bidirectional entailment model is then used to cluster these candidate answers into groups, based on their meaning. The system then calculates the entropy over the probability distribution of these semantic clusters, rather than the individual sequences. This entropy scores is calculated as: $SE(x) \approx -|C|^{-1} \sum_{i=1}^{|C|} \log p(C_i|x)$, where $SE(x)$ is the semantic entropy, $C$ is the set of semantic clusters, and $x$ is the given input query.
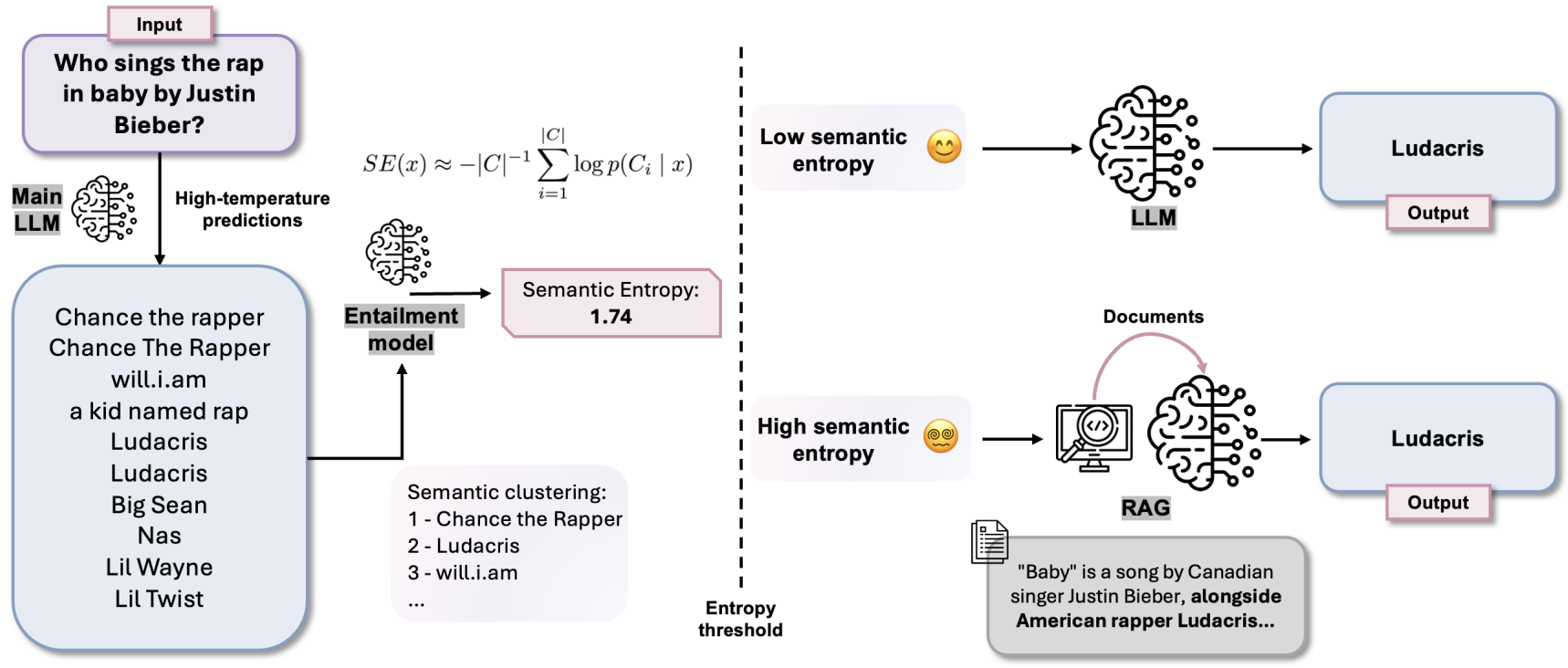
Finally, the entropy score is compared against predefined thresholds to determine the model’s level of uncertainty and perform one of the following three actions:
- Low entropy: This indicates the model is confident. The answer is generated directly from the LLM’s parametric memory without retrieval.
- Medium entropy: This shows the model is somewhat uncertain. The system performs one round of retrieval to augment the context.
- High entropy: This indicates the model is highly uncertain or confused. The system performs multiple rounds of retrieval to provide more comprehensive context.
As it is necessary to compute the semantic entropy, the inference time for SUGAR takes considerably longer than other ARAG methods for single-hop questions.
Gauging Model Uncertainty With Graph Metrics
In Dhole et al.7, researchers build upon the prior ARAG methods and explore which Uncertainty Detection (UD) metrics are more effective to gauge uncertainty for dynamically triggering retrieval. The authors specifically focus on a family of black-box, sequence-level UD metrics and test their viability as a trigger within long-form, multi-hop QA.
They adapted the FLARE framework from Jiang et al.8, where given a query, the system first generates a temporary future sentence without retrieval. However, instead of checking token probabilities, a sequence-level uncertainty score is calculated over this temporary sentence. If this score exceeds a pre-defined threshold, the system concludes that the model lacks knowledge. It then prompts the model to generate a specific subquery to find the missing information, use that subquery to retrieve relevant documents, and regenerates the sentence given the new context.
For computing uncertainty, the authors generated multiple candidate responses and evaluated each of the following 5 UD metrics that compute pairwise similarity scores among these answers.
- Semantic Sets: Based on prior research work, this metric clusters the generated responses into groups based on semantic equivalence using an NLI classifier. The number of resulting clusters serves as the uncertainty score.
- Eigen Value Laplacian: This metric uses spectral clustering on a graph where nodes are responses and the edge weights are pairwise similarities. Eigenvalues far different from one indicate weaker clustering and thus higher uncertainty.
- Degree Matrix (Jaccard Index): The similarity between two responses is computed by the size of the intersection of their word sets divided by the size of their union. This score is then used to build a degree matrix for uncertainty calculation.
- Degree Matrix (NLI): This metric is similar to the Jaccard Index version, but the similarity is computed by an NLI classifier’s entailment predictions.
- Eccentricity: This graph-based metric also uses the degree matrix.
They found that the Eccentricity and the Degree Matrix (Jaccard) were able to reduce the number of retrieval calls by nearly half, with minimal performance drop compared to an “Always Retrieve” baseline. Comparatively, Eccentricity offered the best overall performance and efficiency, while Degree Matrix (Jaccard) required the fewest retrieval operations. The authors note that computing some of these UD metrics can be computationally more expensive than simple retrieval methods, which may outweigh the benefit of skipping retrieval.
Cross-examine Model’s Consistency on Perturbed Questions
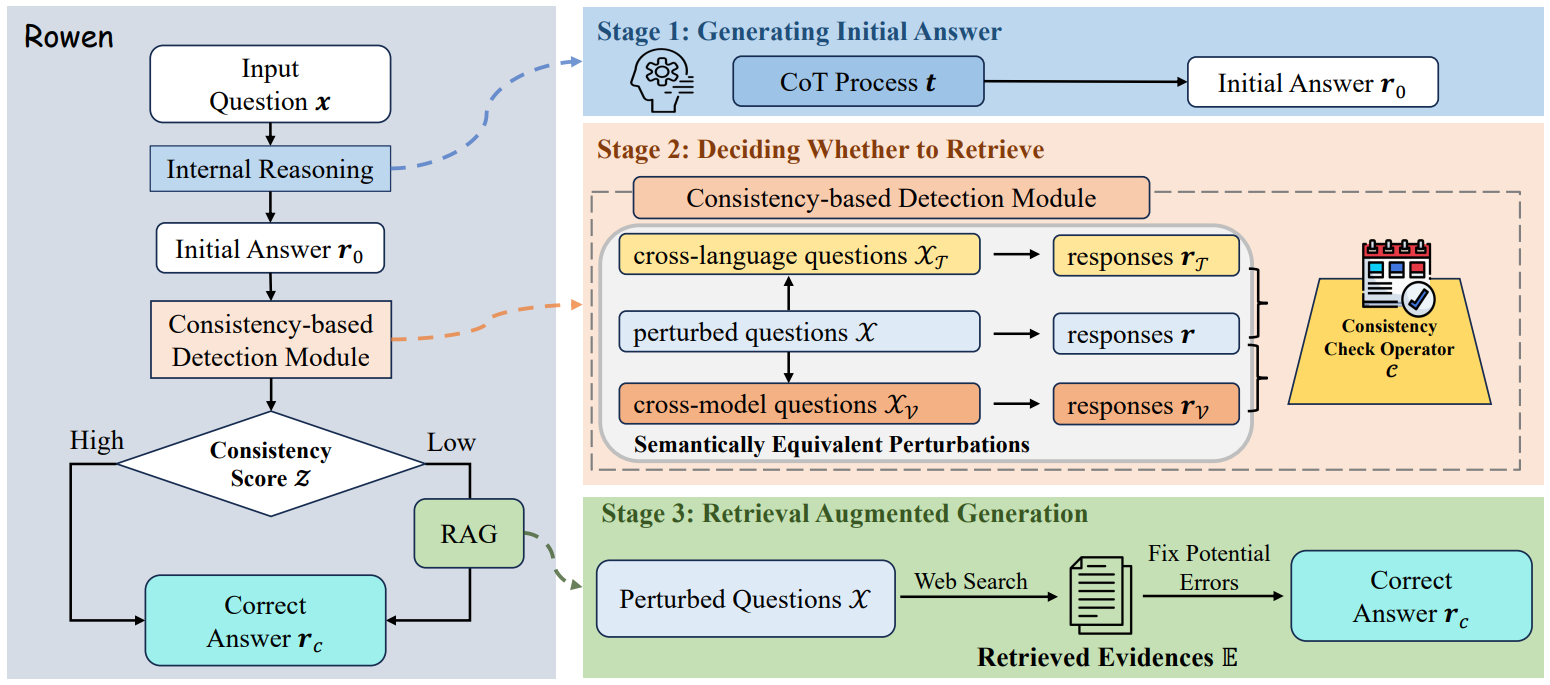
In Rowen (Retrieve only when it needs), Ding et al.9 hypothesized that if an LLM is truly confident about a fact, it should provide a consistent answer even when the question is phrased differently, asked in another language, or posed to a different model. As shown in the figure below, the authors first prompt an LLM to generate a preliminary answer using its own internal knowledge, often guided by a Chain-of-Thought process to elicit its reasoning.
Next, a consistency-based detection module generates several semantically equivalent versions of the original question to measure the model’s uncertainty. The model is asked the same question in different languages (e.g., English and Chinese). Optionally, an additional “verifier” LLM can also be used to answer the same set of questions. A checking operator then determines if the different answers are semantically consistent by producing a consistency score. If the score is high, it indicates that the original answer is reliable and can be returned to the user; otherwise, a retrieval-augmented generation procedure is triggered. The code for Rowen is available on GitHub.
Answer A in English and answer B in Chinese. Your task is to determine if the content and meaning of A and B are equivalent in the context of answering Q. Consider linguistic nuances, cultural variations, and the overall conveyance of information. Respond with a binary classification. If A and B are equivalent, output ’True.’, otherwise output ’False’.
Dual Generation as a Retrieval Gate
In PAIRS (Parametric-verified Adaptive Information Retrieval and Selection), Chen et al.10 propose a training-free framework aimed at fully leveraging LLM’s own parametric knowledge to decide whether external retrieval is necessary. The goal is to improve efficiency without sacrificing accuracy, especially for the simple queries that the LLM can already answer. Given a query, the LLM is prompted to generate two answers in parallel:
- A direct answer, using only the model’s parametric knowledge.
- A context-augmented answer, which is based on a self-generated pseudo-context. The pseudo-context is created by the LLM to simply mimic the retrieved information..
Prompt for generating pseudo-contextYour task is to write a detailed passage to answer the given question. Question: {q}
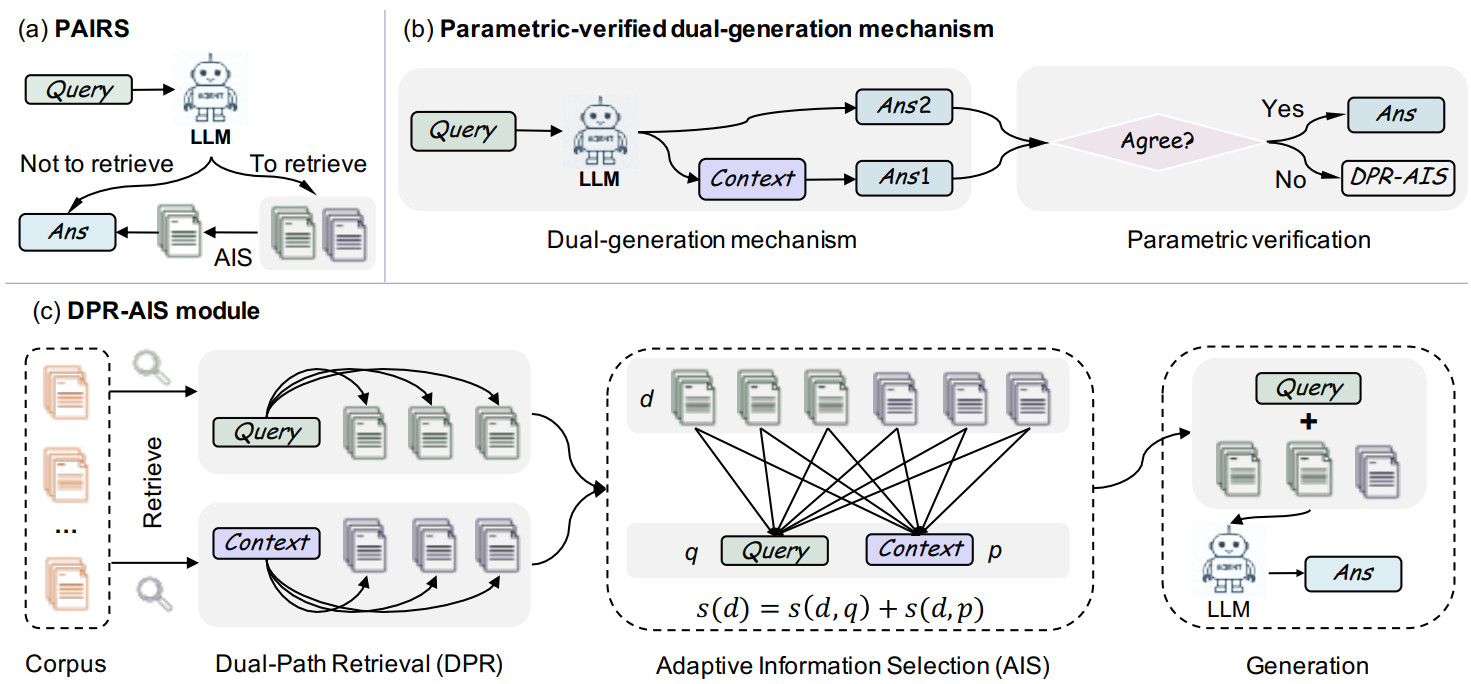
Next, the system checks if the two answers converge or are semantically consistent. If the answers agree, PAIRS concludes that the LLM is confident. It then skips the external retrieval entirely and returns the final answer. However, if the answers differ, suggesting uncertainty in the model’s parametric knowledge, the system activates its Dual Path Retrieval and Adaptive Information Selection (DPR-AIS) module. First, DPR executes two parallel retrieval operations, one using the original query and the other using a self-generated pseudo-context. The results are merged, and the AIS module then scores each candidate document based on its joint relevance to both sources. This dual-source approach makes retrieval more robust against sparse queries.
Trade-offs and Limitations
To sum up, consistency-based ARAG methods are generally more robust, as they compare multiple outputs to capture true semantic uncertainty and are less susceptible to a single, anomalous generation. Like prompting, these methods also work with any black-box model. However, generating 10, 20, or even more responses for a single query dramatically increases inference cost and response time. Additionally, they may not detect systematic knowledge gaps that produce consistent but wrong answers.
Probing the Model’s Mind: Internal State-based Adaptive RAG
Finally, we switch our attention to the set of Adaptive RAG methods that bypass the text output entirely to analyze the model’s internal activations and representations.
Retrieve When LLM Generates Low Confidence Tokens
In FLARE (Forward-Looking Active REtrieval), Jiang et al.8 hypothesize that in a RAG system, retrieval queries should reflect the intents of future generations. They propose anticipating the future by generating a temporary sentence, using it as the retrieval query if it contains low-confidence tokens, and then regenerating the next sentence conditioning on the retrieved document. This iterative framework continues until the next sentence generation reaches the end. The code and data for FLARE are available on Github.

The authors proposed 2 variants of FLARE that differ in their retrieval triggering mechanism. Broadly, these methods either encourage LLMs to generate special search tokens or use the confidence for tokens in the next sentence.
- FLARE with Retrieval Instructions ($\text{FLARE}_{instruct}$): Inspired by Toolformer, this method instructs the LM to generate a retrieval query
[Search(query)]when additional information is needed. Though not as reliable as a fine-tuned model, black-box models can elicit this behavior through few-shot prompting. When LM generates a retrieval query, generation is stopped, and the query term is used to retrieve relevant documents, which are prepended to the user input to aid future generation.Prompt: retrieval instructionsSkill 1. An instruction to guide LMs to generate search queries. Several search-related exemplars. Skill 2. An instruction to guide LMs to perform a specific downstream task (e.g., multihop QA). Several task-related exemplars. An instruction to guide LMs to combine skills 1 and 2 for the test case. The input of the test case. - Direct FLARE ($\text{FLARE}_{direct}$): This method directly uses the LM’s generation as search queries. Retrieval can be triggered if any token of the temporary next sentence has a probability lower than a threshold $\theta$ ($\theta=0$ means never retrieve and $\theta=1$ means always retrieve). Alternatively, the temporary next sentence can be directly used as the query. In the latter approach, there’s a risk of perpetuating errors when the temporary sentence is incorrect. To avoid such errors, the authors propose either masking out low-confidence tokens or using the following prompt to generate questions for the low-confidence span.
Prompt: zero-shot question generation
User input x. Generated output so far y ≤ t. Given the above passage, ask a question to which the answer is the term/entity/phrase “z”.
FLARE is applicable to any existing LM at inference time without additional training. However, interleaving retrieval and generation increases the overhead and cost of generation. Its query formulation strategy hinges on the assumption that LMs are well-calibrated, and a low probability/confidence of each token indicates a lack of knowledge. Many tokens are functional words (such as ‘am’, ’to’, ‘in’, etc.), lacking semantic importance or influence. Confidence scores for these tokens may not capture the real retrieval needs 11. LLMs are also prone to self-bias, so relying on the knowledge sufficiency of LLMs solely based on their outputs can become problematic 12. Some studies found FLARE’s performance to vary significantly among different datasets 13, and subpar with self-aware scenarios 9. Its efficacy also depends on the meticulously crafted few-shot prompts and manual rules.
Improving FLARE’s Understanding of LLM’s Information Needs During Generation
In DRAGIN (Dynamic RAG based on Information Needs of LLMs), Su et al.13 argue that dynamic RAG methods like FLARE (discussed above) can be a bit one-dimensional since relying solely on a single metric, like token generation probability, to decide when to retrieve is not enough. A model may be uncertain about an unimportant word or confident about a factually incorrect word, leading to a suboptimal retrieval decision. The authors propose a method called RIND (Real-time Information Needs Detection) that decides to activate retrieval if a $S_{\text{RIND}}$ score value exceeds a predefined threshold. This score is calculated per-token as the product of three factors:
- Uncertainty: The entropy of the token’s probability distribution. A high entropy score signals that the model is uncertain about which token to generate next.
- Influence: The impact a token has on subsequent tokens, computed by tracking its maximum self-attention value from all the following tokens in the sequence. This helps in identifying words that are critical for shaping the rest of the output.
- Semantic Value: A simple binary filter that removes common stopwords, so that the retrieval decision is based only on tokens with significant meaning.
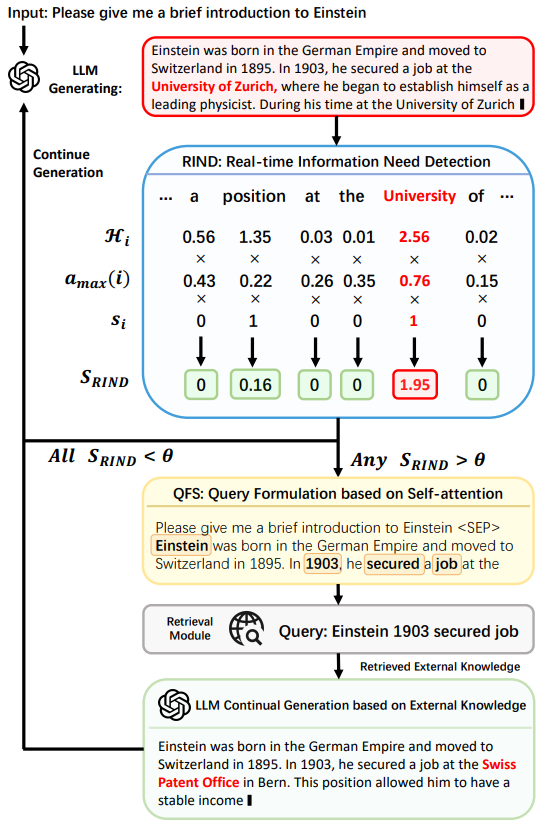
The DRAGIN Framework
DRAGIN can be integrated into any transformer-based LMs without requiring fine-tuning or prompt engineering. However, its application is limited to open-source models since it accesses the self-attention scores from the last Transformer layer of the LLM. The corresponding code and data for this project are available on GitHub.
Detect Entity-level Hallucinations
In DRAD (Dynamic Retrieval Augmentation based on hallucination Detection), Su et al.11 argue that the uncertainty in a model’s output is not spread evenly across all words. Instead, hallucinations that stem from a model’s knowledge gaps are most likely to occur when the model is generating a fact-based entity like a person, place, or date that it doesn’t actually know. As an example, given the input “Bill Clinton was born and raised in __”, LLM can confidently assign a high probability to the token “Arkansas” to complete the sentence, since it has likely seen extensive information about Bill Clinton during the pre-training phase. The authors propose a Real-time Hallucination Detection (RHD) module that performs real-time Named Entity Recognition (NER) during text generation, on the LLM’s output stream. When an entity is detected, RHD assesses the model’s confidence by calculating the following two metrics from the model’s internal state:
- Entity-level Probability: This is the joint probability across all tokens that make up the detected entity (e.g., “King Demetrius II”). A low probability indicates that the model is not confident about the entity.
- Entity-level Entropy: This is the uncertainty in the model’s output distribution for each token in the entity. A high entropy value indicates the model may have faced a flat probability distribution and may have selected a random entity.
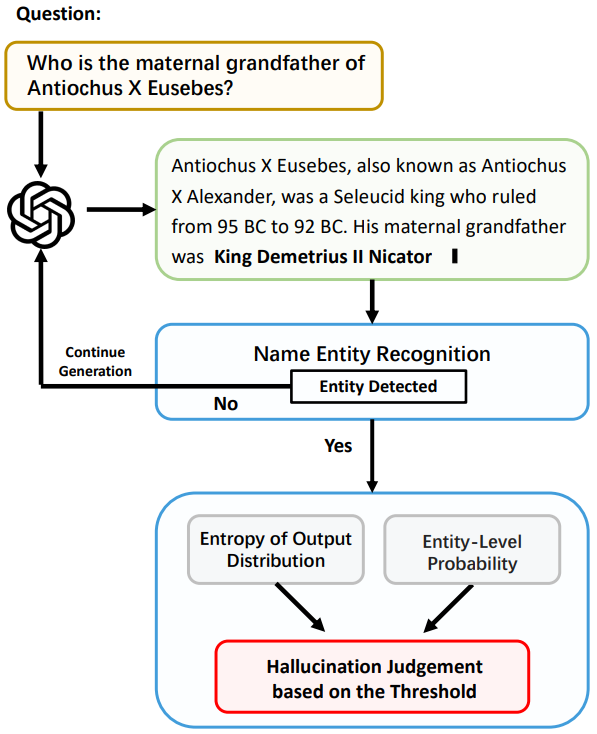
Real-time Hallucination Detection (RHD) module of the DRAD framework
The two metrics are compared against their respective preset thresholds. A hallucination is flagged if the entity probability score is lower than its threshold or the entropy score is higher than its threshold. Finally, retrieval-augmentation is initiated if RHD detects hallucination. The code and data for this project are available on GitHub.
Deciding When to Retrieve by Steering for Honesty
In Control-based Adaptive RAG (CTRLA), Liu et al.14 argue that many existing Adaptive RAG approaches that rely on statistical uncertainty, such as output probability or token entropy, have two fundamental problems. First, LLMs are not always “honest”, i.e., they might generate plausible but incorrect responses, instead of admitting lack of knowledge, meaning that the output tokens may not truly reflect the model’s knowledge limitations. Second, low uncertainty doesn’t always mean high confidence. For example, a model can be highly certain that it doesn’t know something. The authors propose a framework to infer the model’s knowledge gaps from a representation perspective, using the model’s own internal states to guide retrieval.
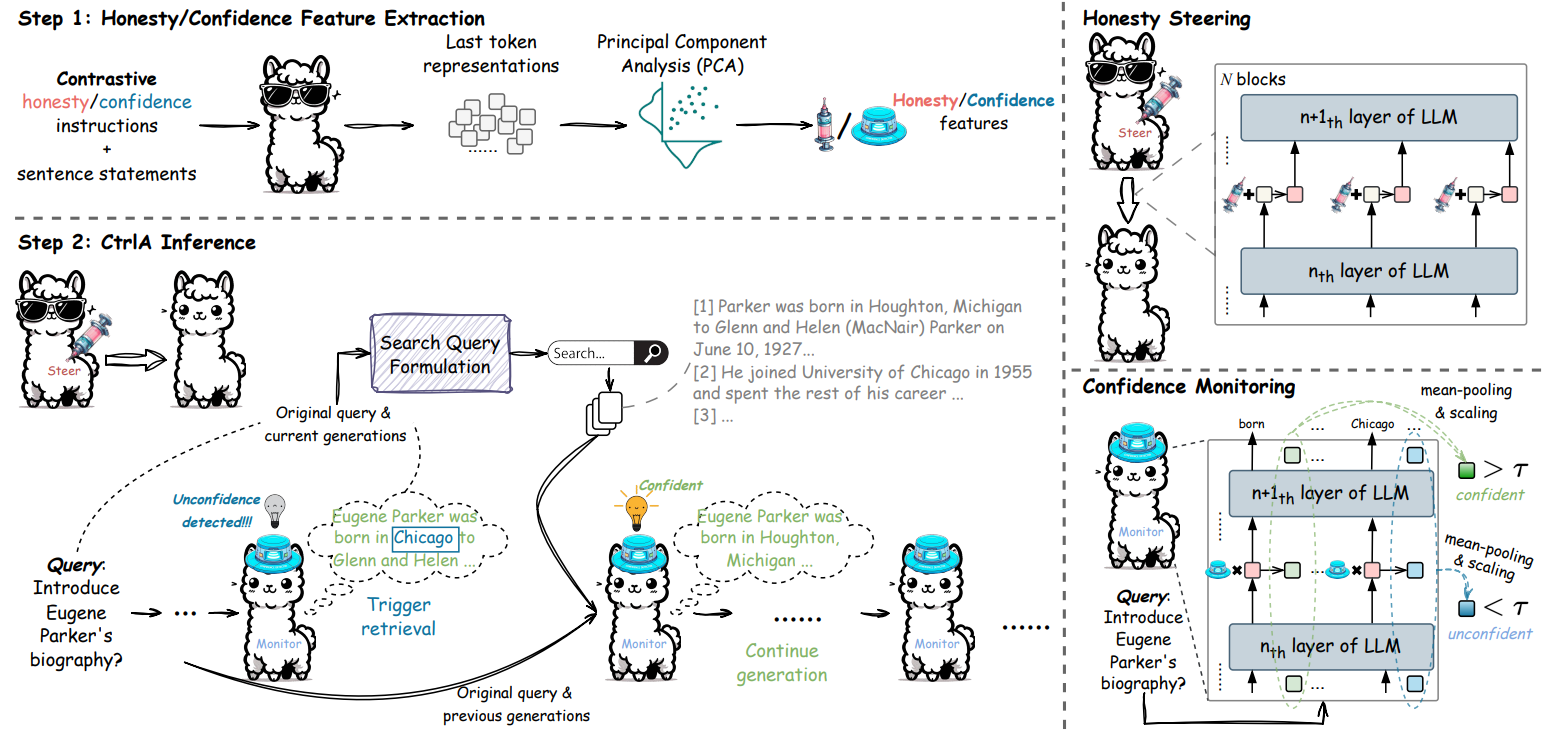
- Honesty and Confidence Feature Extraction: The CTRLA framework begins by extracting directional vectors for honesty and confidence from LLM’s internal layers. This is done using contrastive instructions, where pairs of positive “Pretend you’re an honest/confident person” and negative “Pretend you’re a dishonest/unconfident person” instructions, along with a statement, are fed into the LLM to get token representations for each case. For each token and each layer, a contrastive vector is calculated by subtracting the negative representation from the positive one. This vector effectively points in the direction of the desired trait (honesty or confidence). Principal Component Analysis is applied to these vectors at each layer to find the first principal component, which serves as the general directional feature. This one-time, offline process results in honesty and confidence vectors that are used to control LLM behavior and guide retrieval timing.
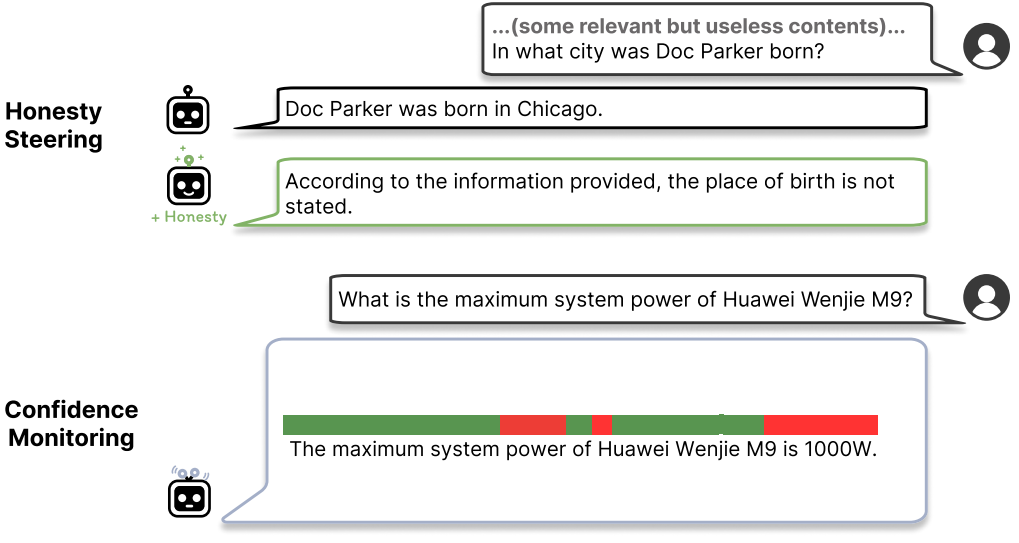
Examples of honesty steering (top) and confidence monitoring (bottom), unconfident tokens are marked in red. - Honesty Steering and Confidence Monitoring: During inference, when the LLM generates each token, its internal representation is modified at each layer by adding the pre-computed honesty feature vector, nudging the model to be more truthful. Simultaneously, a confidence score is computed for each token by measuring the alignment of its representation with the confidence feature vector (using dot-product followed by mean-pooling across layers and scaling). Finally, the confidence score is monitored for tokens that are not stopwords and not present in the original query or previous generations. Retrieval is triggered if this confidence falls below a certain threshold.
The official implementation for CtrlA is available on GitHub.
Looking for Signs of Uncertainty in LLMs’ Internal States
In SeaKR (SElf-Aware Knowledge Retrieval for RAG), Yao et al.12 also argue that relying on observing LLM’s output to decide when to retrieve is insufficient, as models can be prone to self-bias. The authors hypothesize that LLMs possess a form of self-awareness about their uncertainty, which can be measured by observing the consistency of their internal states. They propose calculating a Self-aware Uncertainty Estimate U(c) by measuring the statistical consistency of the model’s internal states, via the Gram determinant of their hidden state vectors, across multiple parallel pseudo-generations.
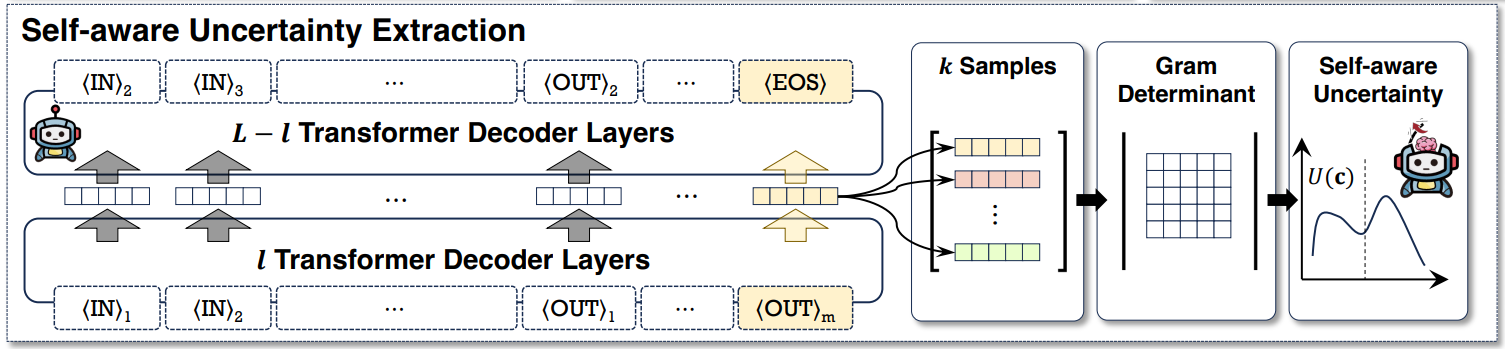
<EOS> (end-of-sequence) token from one of the model’s middle layers. This <EOS> representation is treated as the compressed representation of the entire generation process. The authors then compute consistency among these k hidden state vectors by computing their Gram determinant. A large determinant value implies that the vectors are more scattered and diverse, indicating LLM’s higher uncertainty about the task. If this uncertainty score is higher than a pre-defined threshold, SeaKR concludes that LLM lacks sufficient internal knowledge to answer the question and triggers retrieval.
As SeaKR requires access to the internal state of LLMs, its use is limited to open-source models. Conducting k parallel pseudo-generations is also computationally expensive. The code for SeaKR is available on GitHub.
Using LLM Confidence Shift as a Retrieval Gate
In CBDR (Confidence-based Dynamic Retrieval), Jin et al.15 propose an ARAG method that uses LLM confidence to not only decide when to retrieve, but also to optimize what gets retrieved. The authors hypothesize that LLM’s internal hidden state reflected confidence serves as a strong indicator of its confidence. More importantly, the confidence shift observed when LLM processes different retrieved contexts for the same question reveals its intrinsic preference among those contexts. This intrinsic preference signal can guide a reranker model to filter and optimize contexts post-retrieval to boost the RAG system’s efficacy.
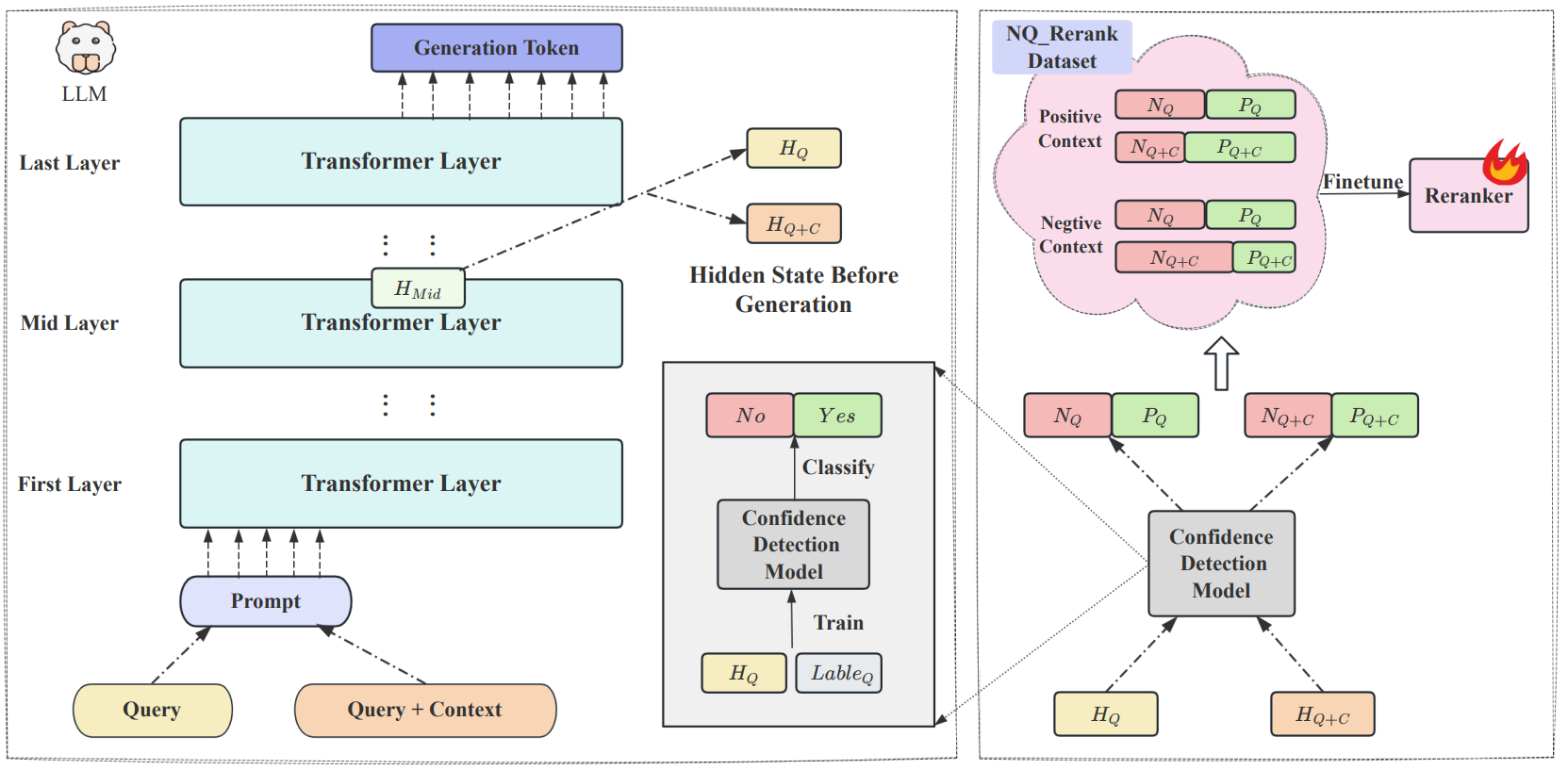
Their framework operates in two phases:
Phase 1: Offline Reranker Alignment
-
Confidence Detection Model Training: First, a binary classifier is trained to act as a “Confidence Detection Model”. This model takes the LLM’s middle-layer hidden state, captured just before the first answer token is generated, and predicts whether the LLM will answer the query correctly. The output of the model is a confidence score ($\text{Conf}(H_M,Q)$), which represents the probability of a correct answer.
-
Preference Dataset Creation: This confidence model is then used to measure how much a given context $C_i$ helps the LLM. This is calculated as a “confidence shift” or increase: $$ \text{Inc}(Q, C_i) = \text{Conf}(H_{M,Q+C_i}) - \text{Conf}(H_{M,Q}) $$ Contexts that increase confidence ($\text{Inc} \gt 0$) are labeled as positive preferences, while those that decrease it are labeled as negative. This process builds a preference dataset (called NQ_Rerank) based on the LLM’s actual internal state changes.
-
Reranker Fine-tuning: Finally, a standard reranker is fine-tuned on the NQ_Rerank dataset. This teaches the reranker to prioritize documents that will produce the largest positive confidence shift in downstream LLM, creating a powerful alignment between the two components instead of relying on simply semantic similarity.)
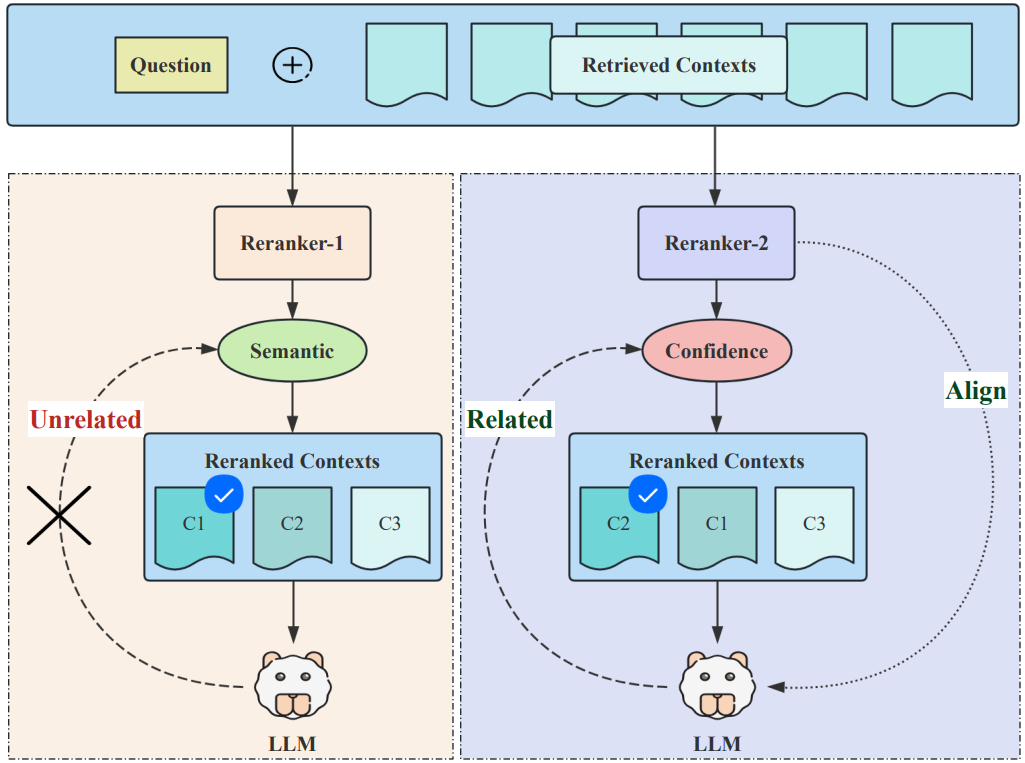
Phase 2: Online Dynamic Retrieval
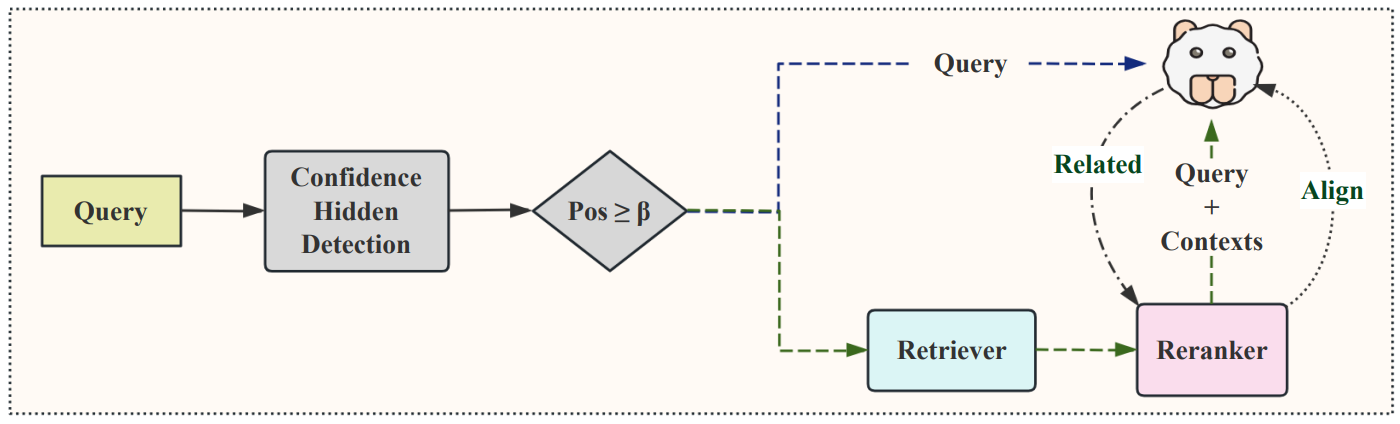
During inference, the system uses the trained confidence model to gate the retrieval process efficiently. For any incoming query, the system first calculates the LLM’s initial confidence, $\text{Conf}(H_{M,Q})$. This score is then compared against a predefined threshold $\beta$. If $\text{Conf}(H_{M,Q}) \gt \beta$, retrieval is skipped entirely and the LLM generates the answer using only parametric knowledge. Otherwise, the full retrieval-reranking pipeline is activated.
Trade-offs and Limitations
Internal state-based ARAG approaches provide the most direct and potentially the most accurate measure of the model’s internal uncertainty. Once the initial setup is complete, monitoring the hidden states during a single generation pass is also computationally efficient compared to approaches that generate multiple full responses. However, their biggest limitation is that they require white-box access to model weights and internal states, making them incompatible with closed-source APIs. They also require an understanding of model architecture, may not generalize across different model families, and are significantly more complex than simple text-based methods.
Summary
This post dived deep into the confidence-based selective retrieval paradigm. It introduced three categories of approaches for deciding whether an LLM needs external help by detecting the model’s knowledge boundary. We started with simple prompt-based methods that rely on LLM self-reflection, then look at consistency-based approaches that infer uncertainty from behavioral patterns, and finally, the sophisticated internal state analysis that directly probes the model’s hidden representations. We established that there is no universal best approach and each category presents a unique set of trade-offs between accuracy, cost, latency, and implementation complexity. In the next post of this Adaptive RAG series, we will shift focus to training-based approaches for treat adaptive retrieval as a learned skill.
References
-
Ni, S., Bi, K., Guo, J., & Cheng, X. (2024). When Do LLMs Need Retrieval Augmentation? Mitigating LLMs’ Overconfidence Helps Retrieval Augmentation. ArXiv. ↩︎
-
Zhang, Z., Fang, M., & Chen, L. (2024). RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering. ArXiv. ↩︎
-
Wang, X., Sen, P., Li, R., & Yilmaz, E. (2024). Adaptive Retrieval-Augmented Generation for Conversational Systems. ArXiv. ↩︎
-
Wang, H., Xue, B., Zhou, B., Zhang, T., Wang, C., Wang, H., Chen, G., & Wong, K. (2024). Self-DC: When to Reason and When to Act? Self Divide-and-Conquer for Compositional Unknown Questions. ArXiv. ↩︎
-
Li, J., Tang, T., Zhao, W. X., Wang, J., Nie, J., & Wen, J. (2023). The Web Can Be Your Oyster for Improving Large Language Models. ArXiv. ↩︎
-
Zubkova, H., Park, J., & Lee, S. (2025). SUGAR: Leveraging Contextual Confidence for Smarter Retrieval. ArXiv. ↩︎
-
Dhole, K. D. (2025). To Retrieve or Not to Retrieve? Uncertainty Detection for Dynamic Retrieval Augmented Generation. ArXiv. ↩︎
-
Jiang, Z., Xu, F. F., Gao, L., Sun, Z., Liu, Q., Yang, Y., Callan, J., & Neubig, G. (2023). Active Retrieval Augmented Generation. ArXiv. ↩︎ ↩︎
-
Cheng, Q., Li, X., Li, S., Zhu, Q., Yin, Z., Shao, Y., Li, L., Sun, T., Yan, H., & Qiu, X. (2024). Unified Active Retrieval for Retrieval Augmented Generation. ArXiv. ↩︎ ↩︎
-
Chen, W., Qi, G., Li, W., Li, Y., Xia, D., & Huang, J. (2025). PAIRS: Parametric-Verified Adaptive Information Retrieval and Selection for Efficient RAG. ArXiv. ↩︎
-
Su, W., Tang, Y., Ai, Q., Wang, C., Wu, Z., & Liu, Y. (2024). Mitigating Entity-Level Hallucination in Large Language Models. ArXiv. ↩︎ ↩︎
-
Yao, Z., Qi, W., Pan, L., Cao, S., Hu, L., Liu, W., Hou, L., & Li, J. (2024). SeaKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation. ArXiv. ↩︎ ↩︎
-
Su, W., Tang, Y., Ai, Q., Wu, Z., & Liu, Y. (2024). DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models. ArXiv. ↩︎ ↩︎
-
Liu, H., Zhang, H., Guo, Z., Wang, J., Dong, K., Li, X., Lee, Y. Q., Zhang, C., & Liu, Y. (2024). CtrlA: Adaptive Retrieval-Augmented Generation via Inherent Control. ArXiv. ↩︎
-
Jin, H., Li, R., Lu, Z., & Miao, Q. (2025). Rethinking LLM Parametric Knowledge as Post-retrieval Confidence for Dynamic Retrieval and Reranking. ArXiv. ↩︎
Related Content





Did you find this article helpful?