Deciding When Not to Retrieve: Adaptive RAG, Part 2

In the previous post, we established that retrieval isn’t always beneficial. While Retrieval-Augmented Generation (RAG) improves LLM performance on knowledge-intensive tasks, the naive “retrieve-then-read” paradigm has several limitations. Indiscriminate retrieval can introduce noise and degrade performance on questions about popular entities, increase computational costs, and even harm response quality when the LLM’s parametric knowledge would suffice.
So how can we build RAG systems that intelligently decide when to retrieve? This post introduces Selective Retrieval techniques that dynamically determine the necessity of external knowledge for each query. We will look at foundational frameworks for these adaptive systems and explore the methods that make retrieval decisions based purely on input characteristics.
Adaptive RAG
Adaptive Retrieval-Augmented Generation (ARAG) refers to the broad field of research that is focused on creating more dynamic, configurable, instance-specific RAG strategies. This paradigm usually includes the following techniques:
-
Active Retrieval: Dynamically refining or re-issuing queries if the initial results are insufficient.
-
Query Decomposition: Breaking down complex queries into subqueries that are handled with iterative retrieval.
-
Knowledge Critiquing: Revising or filtering the retrieved knowledge after it’s been fetched but before generation
The focus of this series is specifically on an ARAG technique called Selective Retrieval, i.e., the task of deciding whether to skip the retrieval step entirely. Several research works cited in this series also incorporate more than one ARAG technique to achieve their goal. Therefore, they use Selective Retrieval and Adaptive RAG terms interchangeably, sometimes also calling it dynamic RAG. But it is useful to distinguish terminology before we dive deep into specific techniques, and understand that the main focus will be on selective retrieval, even if the specific methods are being referred to as Adaptive Retrieval techniques.
Selective Retrieval
To address the challenges listed in the previous section, it is necessary to investigate whether or not LLMs can correctly answer questions without using external evidence 1. Indiscriminately retrieving for every query is inefficient and can introduce noise. For example, an LLM’s parametric knowledge is sufficient for simple factual questions like ‘What is the capital of France?’ or ‘How many days are in a week?’.
Several researchers have proposed Selective Retrieval methods to dynamically determine the necessity of retrieval. Unlike traditional models that either always incorporate context or never consider it, or retrieve context based on a heuristic (retrieve after every n tokens/sentences/turns, etc.), selective retrieval allows the model to selectively retrieve context based on the specific requirements of each question 2. This way, the model can strike a balance between utilizing context and parametric memory.
Selective Retrieval vs Uncertainty Estimation Techniques
How to Evaluate Adaptive RAG
Before diving into different ways to build an Adaptive RAG system, let’s establish how we can fairly compare them. One way to achieve this is by understanding the tradeoffs between Selective Retrieval systems and existing approaches that operate on different principles. Moskvoretskii et al.3 provided a framework to compare classic Uncertainty Estimation (UE) methods against ARAG. Note that the authors of this paper use the term Adaptive RAG to describe the complex, purpose-built pipelines for selective retrieval.
UE methods treat the retrieval decision as a separate, one-time gating task. For a given user question, the model first generates an answer using only its internal knowledge. A specific UE metric is then applied to this generated answer (or to the generation process) to produce a single uncertainty score. The scoring methods generally fall into two categories:
-
Logit-based: These methods require only one generation and look at the token probabilities from the model’s single, initial generation pass. For example, Mean Token Entropy calculates the average entropy for every token in the sequence to assess if the model was consistently unsure.
-
Consistency-based: These methods require LLMs to generate multiple different answers (e.g., 10-20 samples) to the same question. Then, they measure the diversity of this set of answers. For example, Lexical Similarity computes the average similarity score for all pairs of responses to assess uncertainty. This approach is usually effective, but has a large overhead due to the need for multiple calls to the LM.
While UE methods make a single, upfront decision on whether retrieval is necessary for a given question, ARAG methods dynamically interleave the generation and decision-making. They often integrate the uncertainty check within an iterative generation loop and make a retrieval decision at multiple points during the generation process.
Moskvoretskii et al. conducted a large-scale study that compared 8 recent ARAG models, like DRAGIN, SeaKR, (will be covered in next post), and 27 UE techniques across 6 QA datasets, and proposed a 3-part evaluation framework:
-
QA Performance: Standard metrics like accuracy, F1-score etc.
-
Efficiency: Measured by both the number of retriever calls (RC) and the number of LLM calls (LMC). The authors argue that while many recent ARAG methods narrowly focus on reducing RC, they ignore the potential higher cost of LMC required by their method to make their retrieval decisions.
-
Self-knowledge: This dimension uses metrics like ROC-AUC to measure a method’s ability to identify the model’s knowledge gaps, separately from its final QA score. This metric sees how well a method’s uncertainty score correlates with the model’s actual correctness. It highlights that a system can get the answer right without being good at knowing when it truly needs help.
The study advocates for more prudence when designing a retrieval strategy. It found that the simple, general UE methods often outperformed the complex, purpose-built ARAG pipelines, while being significantly more compute-efficient, often requiring several times fewer RC and LMC. They also found that there’s often a disconnect between performance and self-awareness. For example, methods like DRAGIN showed strong downstream QA performance while being poor at the self-knowledge task. Trainable ARAG methods were found to be the most effective at self-knowledge tasks for complex, multi-hop questions. As simple UE methods can be surprisingly effective, especially for straightforward tasks, the study suggests carefully evaluating ARAG methods to ensure their added complexity has a worthwhile return on investment.
With this framework in mind, let’s examine a few methods that are arguably the most efficient ARAG approaches, as they decide to retrieve before the LLM even begins to generate an answer.
Retrieval Decision-Making Without Generation
In this section, we take a look at ARAG methods that avoid the computational overhead of LLM-based uncertainty estimation by making retrieval decisions based purely on the characteristics of the input question.
Retrieve for Long-Tail Factual Knowledge
Mallen et al.4 conducted a large-scale knowledge probing of LMs on factual knowledge memorization. The researchers found that language models struggle with less popular factual knowledge, and retrieval-augmentation helps significantly in these cases. The authors hypothesized and empirically proved that factual knowledge that is frequently discussed is easily memorized by LMs. For less common subject entities (long-tail questions), they require retrieving external non-parametric memories. However, as shown in the figure below, retrieval augmentation can also hurt performance on questions about popular entities when the retrieved context is noisy or misleading. Also, scaling the model helps to some degree, but fails to appreciably improve memorization of factual knowledge in the long tail.
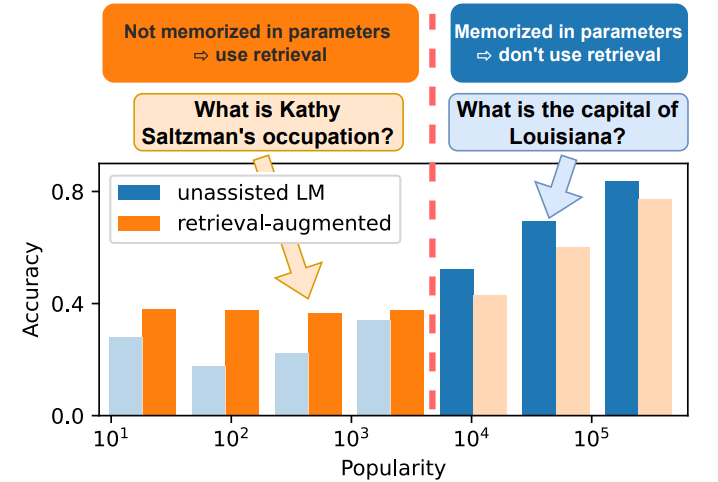
The authors proposed a solution that adaptively combines parametric and non-parametric memories based on popularity. Using a development set, they chose a popularity threshold such that retrieval is only triggered for questions whose subject entities’ popularity is lower than the threshold. This simple strategy showed improved performance for large models, achieving 15% cost reduction for GPT-3 while maintaining equivalent performance. However, smaller models did not realize the same benefits; for example, Llama-2 7B had a 99.86% retrieval usage rate, essentially retrieving for almost every question due to its less reliable parametric memory.
Notably, this method struggles when questions lack explicit entities, and if the definition of popularity (such as frequency or hyperlink counts of entities on Wikipedia) does not accurately reflect. For open-domain question answering, determining a popularity score from available datasets is not a generalizable approach. Also, this method’s effectiveness depends on the quality of popularity metrics; simple approaches like Wikipedia page views may not accurately reflect entity familiarity across different domains or time periods. The code for this research work is available on Github.
Using External Features Derived From the Question
Marina et al.5 argue that the conventional ARAG methods are inefficient because, to decide if an LLM needs help, they usually have to ask the LLM itself. Typically, this involves measuring the model’s internal uncertainty, such as token probability, output consistency, etc. The computationally expensive nature of this approach can offset the efficiency gains that adaptive retrieval aims to achieve. The authors propose lightweight, efficient, LLM-independent methods that rely solely on the external information derived from the question itself. These lightweight, pre-computed “external features” can predict the need for retrieval just as effectively as LLM-based methods, but at a fraction of the computational cost.
The researchers proposed and evaluated 27 distinct external features, organized into the following 7 analytical groups.
-
Graph Features: Entities within the question are linked to a knowledge graph (e.g., Wikipedia). Features include the minimum, maximum, and mean number of connections (triplets) the entities have as subjects or objects, which can indicate their prominence or the density of available information.
-
Popularity Features: These features capture how well-known an entity is by measuring the minimum, maximum, and mean number of Wikipedia page views per entity in question over the last year.
-
Frequency Features: Measures minimum, maximum, and mean frequencies of entities appearing in a reference text collection, and the frequency of the least common n-gram in the question.
-
Knowledgeability Features: An LLM (e.g., LLaMA 3.1-8B-Instruct) is prompted offline to self-assess and provide a numerical score (0-100) of its confidence in knowing about various entities. These scores are precomputed for entities, allowing the system to look up the model’s likely knowledge level at inference time.
Prompt: KnowledgeabilityAnswer the following question based on your internal knowledge with one or few words.
If you are sure the answer is accurate and correct, please say ‘100’. If you are not confident with the answer, please range your knowledgability from 0 to 100, say just number. For example, ‘40’.
Question: {question}. Answer: -
Question Type Features: A BERT-based classifier is trained to predict the probability that a question belongs to one of nine categories, such as
ordinal,count,superlative, andmultihop. -
Question-Complexity Features: A DistilBERT model is trained to classify a question’s reasoning complexity as either simple (
One-hop) or complex (Multi-hop). -
Context Relevance Features: For RAG systems that perform an initial retrieval, this group uses a cross-encoder to score the probability that a retrieved document is relevant to the question.
These features are precomputed and serve as inputs to a simple classification model that acts as a ‘gatekeeper’. In the training data, each question is represented by its feature vector. In their experiments, the authors found a scikit-learn VotingClassifier ensemble of CatBoost and Random Forest to work quite well. During inference, the question is passed through the same pipeline, and the trained classifier makes a binary retrieve or do not retrieve prediction. This way, the expensive generation process is efficiently kept separate from the retrieval decision-making step.
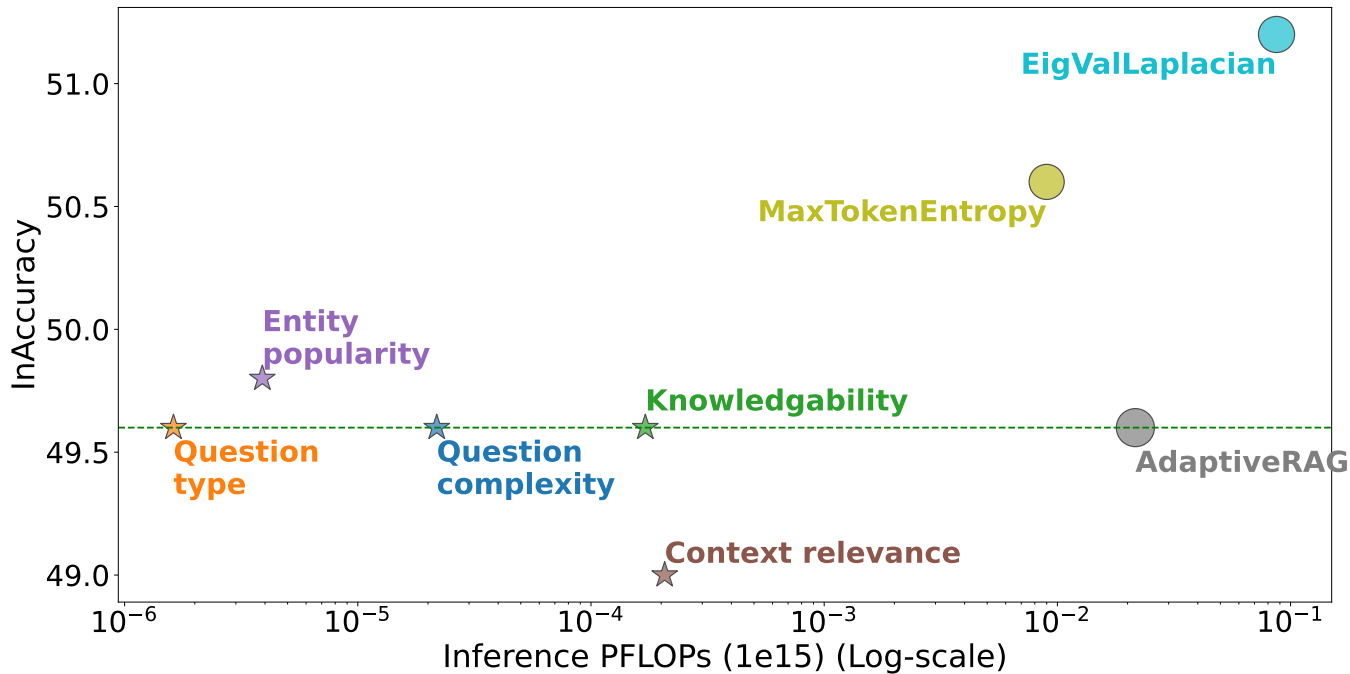
The authors demonstrate that their approach is exceptionally efficient. For many of the external features, the decision-making process was computationally negligible, accounting for less than 1% of the total FLOPS required for the final answer generation, while achieving comparable QA performance. They also found that for complex, multi-hop questions, external features like Question Type and Context Relevance were more predictive of retrieval needs than the LLM’s own uncertainty signals. Their analysis also found that external features are often more “substitutive than complementary”, exhibiting strong correlations despite their differences.
Summary
This post established the foundation for intelligent retrieval decision-making in RAG systems. It introduced Adaptive RAG (ARAG) as a broad framework incorporating dynamic retrieval strategies, with Selective Retrieval as the primary focus for deciding whether to skip retrieval entirely. We looked at a three-dimensional framework that provides metrics for comparing ARAG methods. Finally, the post described two pre-generation retrieval decision methods (popularity-based retrieval triggers and LLM-independent feature engineering).
The evidence suggests that simpler, pre-generation decision methods can often outperform complex purpose-built ARAG pipelines, especially for single-hop questions, while requiring significantly fewer computational resources. In Part 3, we will explore more sophisticated selective retrieval methods that estimate the LLM’s own confidence and knowledge boundaries to offer more nuanced decision-making, particularly in complex reasoning scenarios.
References
-
Li, J., Tang, T., Zhao, W. X., Wang, J., Nie, J., & Wen, J. (2023). The Web Can Be Your Oyster for Improving Large Language Models. ArXiv. ↩︎
-
Labruna, T., Campos, J. A., & Azkune, G. (2024). When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively. ArXiv. ↩︎
-
Moskvoretskii, V., Lysyuk, M., Salnikov, M., Ivanov, N., Pletenev, S., Galimzianova, D., Krayko, N., Konovalov, V., Nikishina, I., & Panchenko, A. (2025). Adaptive Retrieval Without Self-Knowledge? Bringing Uncertainty Back Home. ArXiv. ↩︎
-
Mallen, A., Asai, A., Zhong, V., Das, R., Khashabi, D., & Hajishirzi, H. (2022). When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. ArXiv. ↩︎
-
Marina, M., Ivanov, N., Pletenev, S., Salnikov, M., Galimzianova, D., Krayko, N., Konovalov, V., Panchenko, A., & Moskvoretskii, V. (2025). LLM-Independent Adaptive RAG: Let the Question Speak for Itself. ArXiv. ↩︎
Related Content





Did you find this article helpful?