The Evolution of Multi-task Learning Based Video Recommender Systems - Part 1

Multi-task learning (MTL) has been widely adopted to solve real-world problems across a broad range of domains, such as Natural Language Processing, Computer Vision, Speech Recognition, etc. MTL has also been successfully applied to large-scale real-world recommendation applications. This post highlights how the MTL paradigm-based modern recommender systems have evolved, specifically looking at the industrial-scale video recommenders.
Why Should One Use Multi-task Learning?
MTL allows modeling multiple tasks while utilizing shared model architectures and low-level representations. Such cooperative learning, at least theoretically, can help improve the accuracy of related tasks. Jointly learning commonalities and differences between different tasks can save computation costs and help build a more generalizable model. The efficient shared parameters structure also helps build low-latency large-scale machine learning systems.
Recommender systems model user preferences and satisfaction by predicting users’ future feedback. The goal of the system is to provide a ranked feed of recommended videos that maximize user satisfaction and involvement with the application. However, learning users’ true satisfaction is a hard and high-dimensional problem. True user utility may not be independently reflected in the activity logs. For building recommenders, we assume that solving a surrogate problem will allow us to transfer the result to a particular context. For example, we assume that accurately predicting moving ratings will lead to more effective movie recommendations1. Hence, for simplicity we assume that the user behavior or feedback, i.e. the subtle factors that can be directly learned, more or less indicate user preferences2. For example, a high playing finishing rate and long average playback time could be considered indicators of user satisfaction.
For video-based applications, such as Instagram Reels, TikTok, and YouTube Shorts, such feedback comes in the form of various user behaviors, such as likes, comments, shares, completion ratios, dismissals, bookmarks, etc. A movie recommender system, for example, may want to predict the probability of a user clicking on the video, as well as watching it to completion. With MTL, these specific behaviors can be jointly predicted, which is usually followed by a fusion process that finally characterizes user satisfaction based on the multiple output values of the MTL model.
General Setup
A large-scale item recommender faces some unique challenges. Covington et al.1 list the following factors that make recommending YouTube videos a hard task.
- Scale: Complex, non-distributed algorithms that work well on small problems, may fail to operate at the scale of billions of users and items. Efficiency directly affects serving costs as well as user experience. Previous studies have shown that even a 100 ms delay can cause a measurable impact on revenue3.
- Freshness: Platforms like TikTok get tens of millions of new videos uploaded every single day. The recommendation pipeline has to be responsive enough to model the new content and user interaction logs. Surfacing new content also requires a decent exploration/exploitation strategy.
- Noise: Owing to the large corpus, the interaction data is generally extremely sparse. And, the model is tasked with modeling noisy implicit feedback signals (due to a multitude of external factors, such as accidental clicks) as we rarely observe the ground truth of user satisfaction.
Recommender Pipeline
Industrial recommender systems usually follow a cascading pipeline mainly consisting of two stages: candidate generation (also called, “matching” or “recall” step) and ranking. At the candidate generation step, multiple retrieval strategies (such as user-to-item, item-to-item, topic-based matching, etc.) are used to retrieve a few hundreds or thousands of candidates from the large corpus. The level of personalization at this stage is usually broad and achieved via collaborative filtering. Next, a ranking step scores each candidate to generate the final ranked list of recommended items.
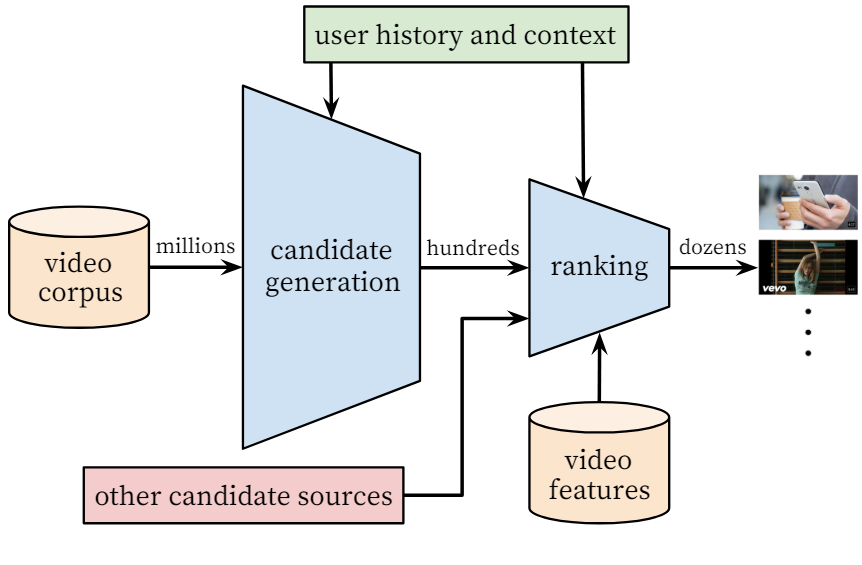
As we have a substantially lesser number of candidates at the ranking step, we can afford to apply a sophisticated and large-capacity neural network model and access more features that describe users, videos, and their relationships. Such a ranking stage is also useful for merging results from different candidate sources whose scores may not be directly comparable. Multi-task learning techniques are commonly applied at the ranking stage with ranking objectives corresponding to different types of user feedback.
Input Data
For preparing the training inputs, we sample the last $n$ days of data from user behavior logs. Usually, 7-10 consecutive days’ data is used for training and the next 1-3 days’ data is used for testing purposes. Although we can directly use explicit feedback from users, such as in-product surveys, etc. In reality, such signals are extremely sparse and costly to obtain, and hence their quantity does not scale up well. Therefore, we commonly rely on implicit feedback such as clicks, comments, watching a video to completion, etc as positive samples, while feedback such as skipping or hiding a video as negative samples. Some systems also like to categorize their user feedback into various categories. For example, YouTube defined two types: engagement behaviors, such as clicks and watches, and satisfaction behaviors, such as likes and dismissals.
Note that it is expected to have some level of noise and sparsity in the training data. Sparse features tend to follow power-law distributions that have high variances in user feedback1. For example, a user may not click a recommended item with the same query given a slightly different context such as location, time of the day, a different thumbnail, or even some external factor that cannot be captured in our system. Using implicit feedback allows us to produce recommendations for long-tail items for which the explicit engagements might be extremely sparse in the impression logs.
Some heuristic rules are commonly used to filter the training data. For example, we may use the following rules to filter out some data:
- users with less than five interactions
- videos with less than five seconds in length or more than three hours
- videos with less than five impressions
- impressions with abnormally long watch time
Each positive or negative sample is annotated with the corresponding target value. For example, for the watch time task, positive items are annotated with the amount of time the user spends watching the video. Similarly, for the click task, each item is annotated based on whether the item was clicked upon impression.
The ranking model is commonly implemented in a pointwise fashion. Pairwise or listwise approaches can be used to improve the recommendation diversity, but pointwise approaches tend to scale better under serving considerations. Given each candidate, our ranking system uses features of the user query, candidate item, and context (such as time of the day, and device type) as input, and learns to predict multiple user behaviors. The user query is usually represented through the user’s watch history.
Feature Engineering
Features used by the recommender can be categorized based on whether they describe properties of the item (“impression”) or properties of the user/context (“query”). User-side features are computed once per request while item-side features are computed once per item.
Users’ watch history contains variable-length sequences of sparse video IDs, which are mapped to dense vector representations via embeddings. If user search history is available, it is treated similarly, by tokenizing and embedding the past queries. These dense watch and search histories can be concatenated or summarized by taking an average (or sumpool/maxpool etc) of the respective sequence of embeddings. These ID sequences are usually truncated to a fixed length with default padding wherever applicable. Embedding dimensions increase approximately proportional to the logarithm of the number of unique values. Note that the categorical features in the same ID space also share embeddings. This helps improve generalization, speeding up training and reducing memory requirements1.
Supplying user demographic features, such as geographical location gender, and age can help with handling new users more effectively. Sparse categorical features are mapped to dense representations using embeddings. Binary (e.g. whether the user is logged in) and continuous features are normalized to the [0, 1] range. Some continuous features that generalize well describe past user actions, such as how many videos has the user watched from this channel, when was the last time the user watched a video on this topic, etc.
On the item side, we have features like titles, tags, duration, video cover, content, category, etc. Video metadata and content signals are used to generate representations for videos. Embeddings for categorical features can be extracted from pre-trained encoder models. Features related to video cover can help in better prediction for click-through rates, and content embeddings can help more with watch time prediction. In reality, the associated video metadata is poorly structured and does not have a well-defined ontology because video producers cannot be forced to provide full details about the videos they publish. Computing multi-modal features is also quite expensive in terms of time and resources. Due to these acquisition challenges, some teams may choose to only use the interaction data.
Training Labels
Users may have different types of behaviors towards recommended items. The multi-task ranking model predicts these behaviors that relate to user utility. Objectives like click and watch time measure engagement, while liking and rating measure satisfaction. Cross-entropy loss is computed for binary classification tasks (like clicks, 80% watch completion), and regression tasks (like video watch time) usually use squared loss.
Let’s take a look at some examples of such labels used in real-world video recommenders.
-
Tencent’s WeSee: In Liu et al.4, Tencent describes jointly predicting explicit feedback such as Like, Follow, Comment, Share, Read Comment, and Read Homepage, along with 3 “play” tasks (2 positive, 1 negative) related to implicit watch time feedback.
- Play Completion Ratio: A regression task $\frac{\text{watch time}}{\text{video length}}$ that predicts the completion ratio. Due to re-watches, the watch time may exceed the video length, so the range $[0,\infty]$ of values is usually truncated to a max threshold.
- Play Finish: A binary classification task that predicts the probability of watching a video to the end (i.e. $\text{watch time} \ge \text{video length}$).
- Skip: A binary classification that predicts the probability of quickly skipping a video within a short time (i.e. $\text{watch time}\lt\text{c seconds}$).
-
Tencent News: Similarly, in Tang et al.5, Tencent used the View Completion Ratio task for modeling view count and View Through Rate for modeling watch time metric. They also employed Share, and Comment for modeling more traditional user feedback actions.
-
Baidu Haokan Videos: In Li et al.6, Baidu used Click-through Rate (CTR), Continuous CTR, Continuous Play Length, etc.
Combining Task Predictions
For each candidate video, the predictions for all tasks and combined using a combination function, such as a weighted multiplication, to generate a final score. These weights can be learned or hand-tuned based on business needs to achieve the best performance. Liu et al.4 proposed a Reinforcement Learning-based approach to learn a proxy function that calculates the final fusion score. Xin et al.7 also recommend upweighting the loss of the more sparse tasks. The candidate set is sorted based on the combined score to get the ranked recommendations list.
For offline experiments, binary classification tasks are trained with cross-entropy loss and evaluated with AUC, while regression tasks are trained with MSE loss and evaluated with MSE. Ground truth data for evaluation is extracted from user behavior logs and the loss is defined as the difference between actual user actions and the prediction actions. Multiple other metrics like precision, recall, and NDCG are also used to guide the iterative development of the full pipeline. The final assessment of the effectiveness of the model is done via A/B experiments in the live production system. This live testing allows us to measure multiple engagement and satisfaction metrics like click-through rate, watch time, dismissal rates, survey responses, etc. Metrics indicating serving costs, such as the number of queries per second, are also extremely important for large-scale systems. It is not uncommon for the A/B results to not be correlated with offline experiments1.
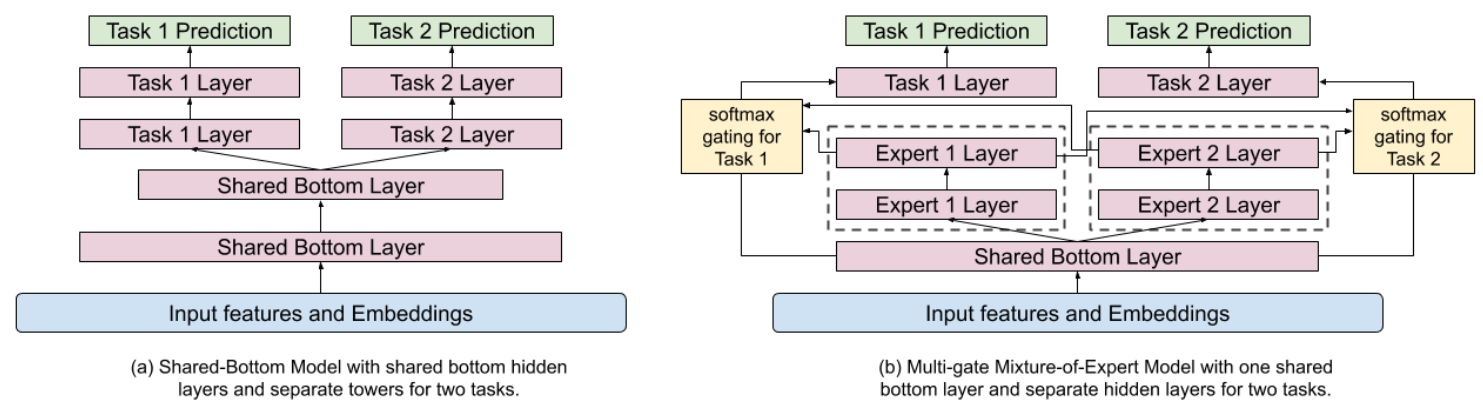
Shared-Bottom Model and Its Shortcomings
The widely-used multi-task ranking architecture follows a shared bottom structure as shown in the following figure8.
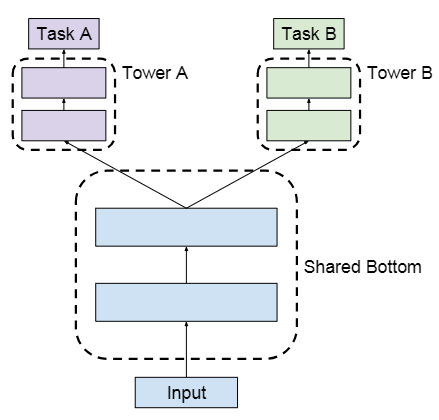
This architecture consists of low-level layers that are shared by all tasks and some task-specific high-level layers on top of the shared bottom. The shared component helps with learning a joint representation for many related tasks, avoiding overfitting, and also saves computation costs due to parameter sharing. This sharing of hidden layers is also referred to as hard parameter sharing.
Theoretically, hard parameter sharing can help by learning shared knowledge among different tasks and improving generalizability. However, several studies have shown that the MTL paradigm is sensitive to relationships among tasks, such that tasks that have weak or complex correlations, may lead to performance degradation. The inductive bias introduced by the shared layer is in conflict when tasks are unrelated. This phenomenon is referred to as negative transfer. Tang et al.5 also discovered a seesaw pattern among complex correlated tasks, where improvement in the performance of one task comes at the cost of hurting the performance of some other task. Meaning that multiple tasks could not be improved simultaneously, compared to single-task models. Also, Liu et al.4 empirically showed that addressing more than 3-5 tasks with flat sharing doesn’t bring any substantial gains.
In real-world recommender systems, tasks are often loosely correlated or even conflicted. Tasks like Click-through Rate and View Completion Ratio aim to model different user actions, so the correlation between them is simpler. But there are often different and conflicting objectives that we want to optimize for. For example, we may want to optimize skip rate minimization and watch time maximization at the same time9. Similarly, optimizing a high play finishing rate might make the model recommend shorter videos, while simultaneously optimizing for long average playback time may have it recommend longer duration videos10. Due to this diversity of task combinations, video recommender MTL objectives are often in conflict11.
Towards Flexible & Efficient Parameter Sharing
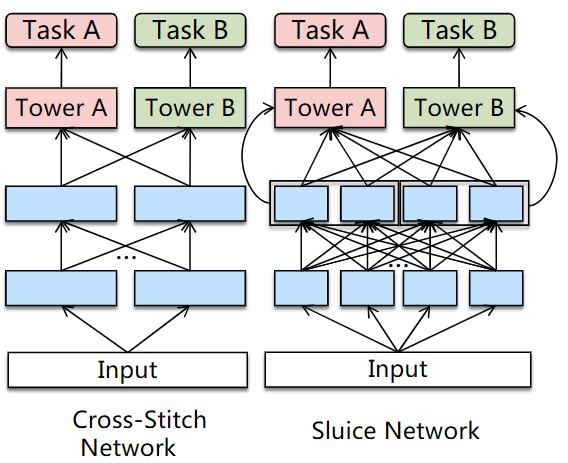
A naive solution to the task conflict is to use multi-task models for related tasks and single-task models for unrelated tasks. However, there is no good way to ascertain which tasks are related. Another solution is to tune the network architecture to allow flexible parameter sharing. To deal with task conflicts some have tried learning weights of linear combinations of representations from different tasks. However, they learn static weights, and incur a large number of additional parameters, leading them to very limited success in large-scale settings. The following figure shows two such proposals.
Gating Structures
A popular and scalable way to address the conflict problem is to design gating structures and attention mechanisms that fuse knowledge based on input. Mixture-of-Experts (MoE) first proposed to share some experts at the bottom and combine experts through a gating network. Multi-gate Mixture-of-Experts (MMoE) extended this concept to obtain different fusing weights. Please refer to the following article to read more about the origin of the MoE paradigm and its usage in recommender systems:

Mixture-of-Experts based Recommender Systems
This article gives an introduction to Mixture-of-Experts and some of the most important enhancements made to the original MoE proposal. Then we look at how MoEs have been adapted to compute recommendations by looking at examples of such systems in production.
Read more...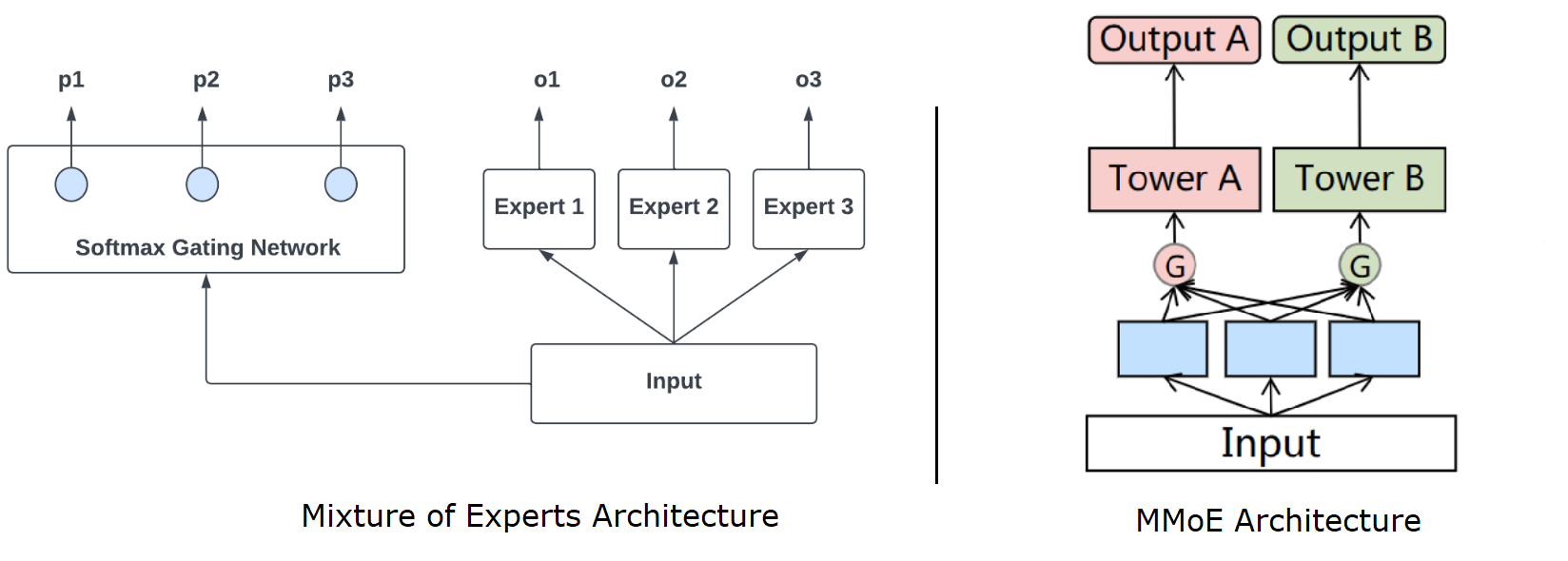
MMoE splits the shared low-level layers into sub-networks, called experts, and uses task-specific gating networks to utilize different subnetworks. MMoE explicitly learns to model task differences and relationships from data.
YouTube’s Ranker
In “Recommending what video to watch next: a multitask ranking system”12 Google describes using soft-parameter sharing via MMoE to bring significant improvements to the ranking component for YouTube’s recommender system. Experts help in improving the representation learned from complicated feature space generated from multiple modalities, without requiring significantly more parameters compared to the shared-bottom model. Due to task-specific gates, each task now has customized fusion, i.e. it may or may not choose to share experts.
Google’s Automatic Sub-network Routing
Google also proposed a Neural Architecture Search (NAS) based method to automatically learn a more flexible parameter-sharing architecture. Ma et al.8 proposed a framework called Sub-Network Routing (SNR) that controls sparse connections among subnetworks with learnable latent variables while maintaining the computational advantage of the shared-bottom model.
Their approach follows a NAS strategy that learns the architecture and model parameters together. The architecture space is constrained by coding variables, which are latent binary random variables from parameterized distributions. The goal of the training process is to learn the distribution parameters and model parameters simultaneously. Although it makes the MMoE approach more flexible by generalizing it, there are certain simplified assumptions and the learning cost is expensive and not scalable.
Tencent’s Progressive Separation Routing
In MMoE, experts and attention modules are shared among all tasks, meaning that it neglects the differentiation and interaction between experts. In Tang et al.5, Tencent proposed an MTL model called Customized Gate Control (CGC) that separates task-common and task-specific experts to improve MMoE and mitigate the seesaw phenomenon. The authors further extend CGC to improve information routing and propose a novel progressive separation routing scheme called Progressive Layered Extraction (PLE).
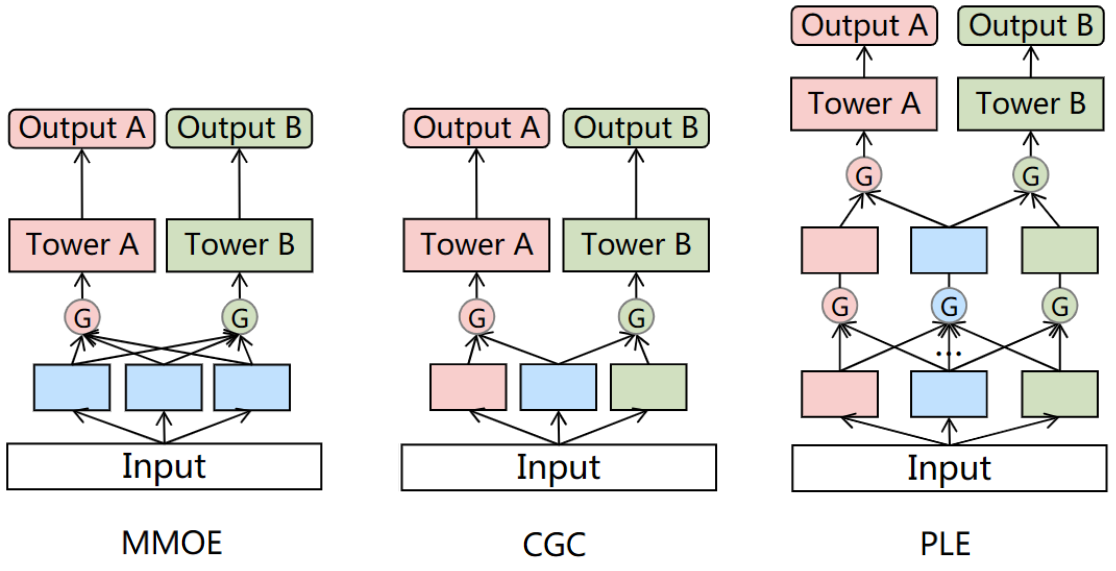
CGC also removes the connection between a task’s tower network and task-specific experts of other tasks. Task-specific experts focus on learning distinct knowledge free of harmful parameter interference, receiving input from their expert network and the shared expert network through a gating network for dynamic fusion. CGC explicitly separates task-specific and shared components. However, the authors hypothesize that learning needs to shape deeper and deeper semantic representations gradually, and it’s not always clear whether the intermediate representations should be treated as shared or task-specific. Hence, they generalize CGC to PLE with multi-level gating networks and separate task parameters in upper layers. PLE stacks CGC expert networks and creates extraction networks. Extraction networks receive fused outputs from lower-level networks, gradually learning deeper semantic representations and extracting higher-level shared information.
Let’s take a look at some formal definitions. The original MoE model can be formulated as:
$$y = \sum_{i=1}^{n} g(x)_{i} f_i(x)$$
where $n$ is the number of experts, $g_{i}(x)$ indicates the probability or weight for expert $f_{i}$ and $\sum_{i=1}^{n} g(x)_{i}=1$, $f(x)$ are $n$ expert networks and $g(x)$ is a gating network that ensembles results from all experts.
MMoE improves MoE by adding a gating network $g^{k}$ for each task $k$. We define $q^{k}$ as the network of the $k$-th task. The output of task $k$ is:
$$y_{k}=q^{k}(f^{k}(x))$$
where $f(x)^{k}= \sum_{i=1}^{n} g(x)^{k}_{i} f(x)_i$
and $f(x)_{i}$ is the output of the $i-$th expert.
The weighting function calculates the weight vector of task $k$ through linear transformation and a softmax layer as:
$$g^{k}(x)=softmax(W^{k}_{g}x)$$
where $W^{k}_{g} \in \mathbb{R}^{n \times d}$ , and $n$ indicates the number of experts and $d$ indicates the feature dimension.
PLE improves MMoE by separating experts into shared experts and task-specific experts. As a results the parameter matrix becomes $W_k^g \in \mathbb{R}^{(M_k + M_s) \times d}$ . Here $M_s$ is the number of shared experts and $M_k$ is the number of task $k$’s specific experts.
Tencent’s Multi-Faceted Hierarchical Learning
In Liu et al.4, Tencent argues that MTL models do not scale well beyond 2-6 tasks, leading to an industrial practice of employing 2 or even 3 MTL models in the ranking service. To address this, they propose a universal learning framework, called the Multi-Faceted Hierarchical multi-task learning model (MFH), that exploits semantic correlation among a large number of correlated tasks. MFH uses a nested hierarchical tree structure to improve MTL efficiency and scalability from a macro perspective of task sharing.
The underlying hypothesis is that in recommender systems, it is common to have different value ranges of certain properties or features, such as new users, low-activity users, and new content, exhibit very different correlation patterns with the predicted label. Directly fitting the model on this data leads to overfitting in certain feature regions. This local overfitting problem worsens when we have imbalanced or insufficient data samples for these regions. To improve the model accuracy on these regions, a simple approach is to create an independent task corresponding to each region. This means that we create separate tasks to differentiate new users and new items from old ones, leading to a cartesian product style increase in the number of tasks, which quickly becomes intractable.
At the micro-level, MFH uses the concept of a switcher. A switcher is a neural architecture that takes one input and branches out to 2 or more latent outputs. The input can be any set of features, embeddings, or intermediate representations, and the outputs are some latent representations usually fed into upper-level networks. A switcher can be an MTL structure, like a shared-bottom, MMoE, or a PLE model.
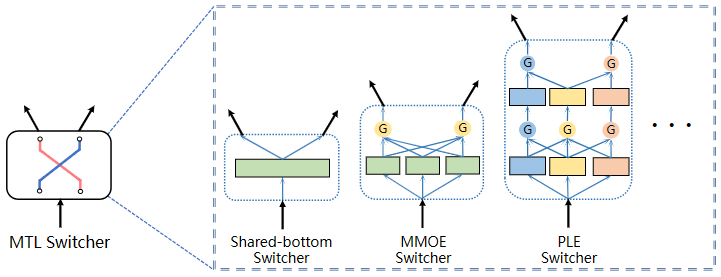
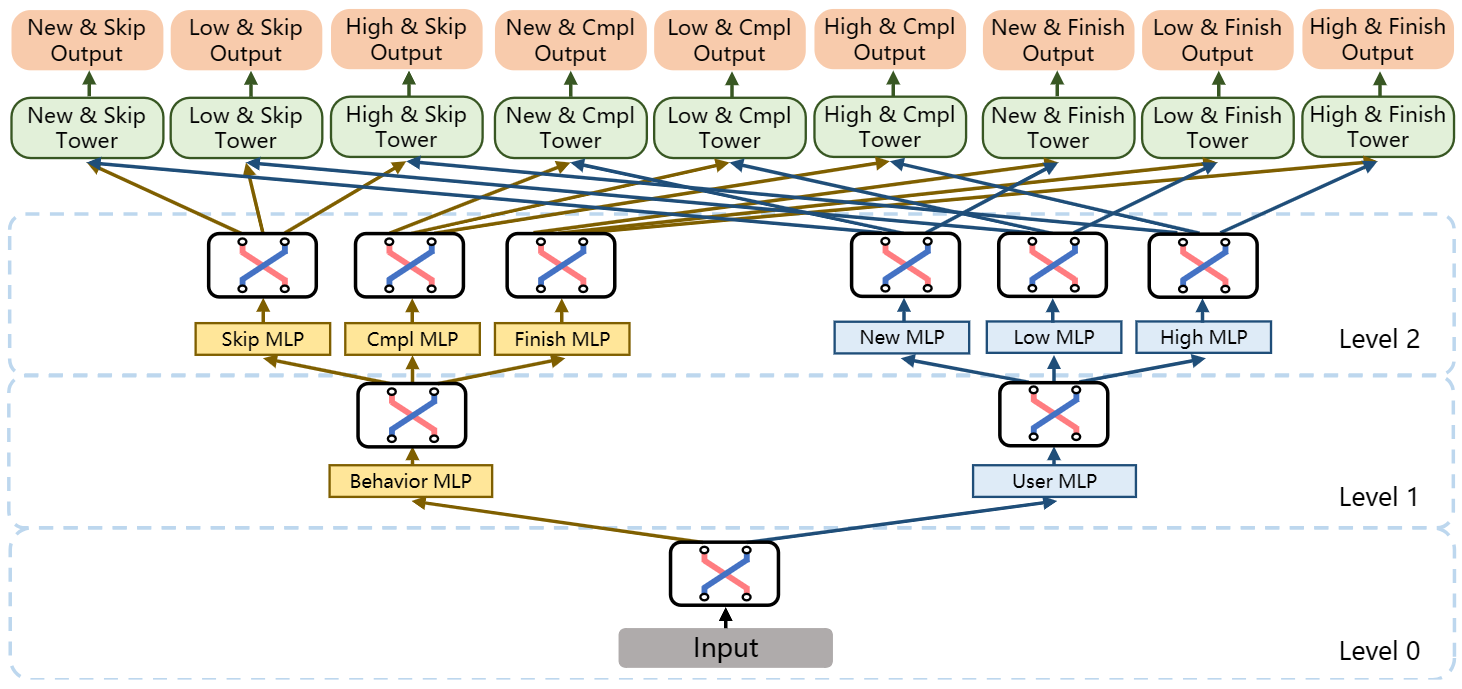
Let’s say we have 3 tasks, Play Completion Ratio (Cmpl), Play Finish Rate (Finish), and Play Skip Rate (Skip) defined in the “Training Labels” section earlier. If we split each task for new users (New), low-activity users (Low), and high-activity users (High), the number of tasks shoots up to 9. The authors also introduce a concept of facets to divide tasks into groups. Facets are orthogonal dimensions that every task has. For example, in this 9-task setup, each task simultaneously has 2 facets, a user-behavior facet {Cmpl, Finish, Skip} and a user group facet {New, Low, High}, with each facet containing 3 partitions.
The following figure shows a two-level hierarchical tree structure, Hierarchical MTL (H-MTL), to model such task relationship. At level 0, a switcher learns task relationships in the user behavior facet based on input features and connects to three MLPs at level 1. Each MLP outputs a hidden representation to feed a switcher which learns task relationships for user group facets conditioned on the user behavior.
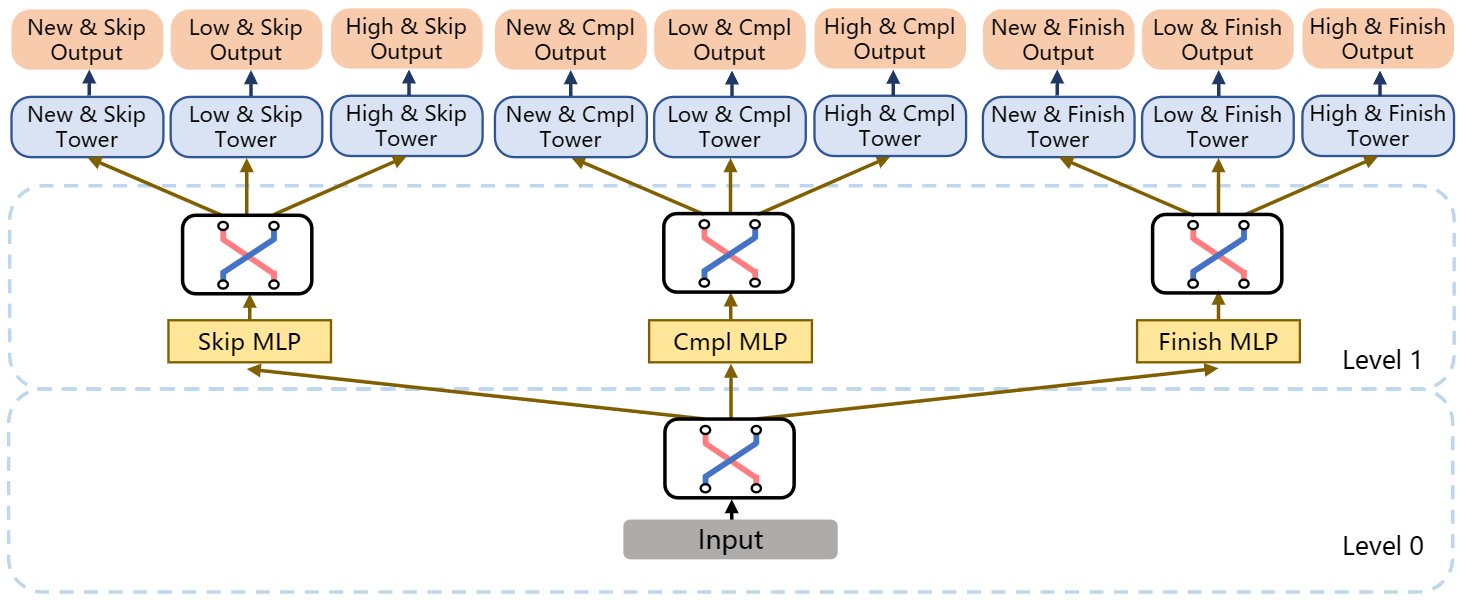
To improve efficiency, MFH nests multiple H-MTL trees together. As shown below, at level 0, the switcher learns the inter-facet relationship between the two facets and branches out to two MLPs at level 1. The upper-level structure is the combination of two variants of the H-MTL model.
Conclusion
This article presented a deep dive into a general setup for an MTL-based large-scale industrial video recommender system. Multi-task learning paradigm of modeling multiple related tasks fits quite well for the video recommender system use case which requires predicting diverse objectives. MTL also saves computation costs by sharing model parameters. However, the classic flat parameter sharing methods tend to struggle with negative transfer and seesaw phenomenon when the tasks are less related. Flexible soft parameter-sharing methods help alleviate these challenges to some extent. The article highlighted several solutions from real-world state-of-the-art recommender systems deployed at various organizations. This is the first article in a 2-part series on this topic, the next part will continue exploring some of the most important solutions from the industry, and share several learnings, and tips for practitioners. The second article is available at this link.
References
-
Covington, P., Adams, J.K., & Sargin, E. (2016). Deep Neural Networks for YouTube Recommendations. Proceedings of the 10th ACM Conference on Recommender Systems. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Zhuo, W., Liu, K., Xue, T., Jin, B., Li, B., Dong, X., Chen, H., Pan, W., Zhang, X., & Zhou, S. (2021). A Behavior-aware Graph Convolution Network Model for Video Recommendation. ArXiv. /abs/2106.15402 ↩︎
-
Kohavi, Ron & Deng, Alex & Frasca, Brian & Walker, Toby & Xu, Ya & Pohlman, Nils. (2013). Online Controlled Experiments at Large Scale. 10.1145/2487575.2488217. ↩︎
-
Liu, J., Xia, Z., Lei, Y., Li, X., & Wang, X. (2021). Multi-Faceted Hierarchical Multi-Task Learning for a Large Number of Tasks with Multi-dimensional Relations. ArXiv, abs/2110.13365. ↩︎ ↩︎ ↩︎ ↩︎
-
Tang, H., Liu, J., Zhao, M., & Gong, X. (2020). Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. Proceedings of the 14th ACM Conference on Recommender Systems. ↩︎ ↩︎ ↩︎
-
Li, D., Li, X., Wang, J., & Li, P. (2020). Video Recommendation with Multi-gate Mixture of Experts Soft Actor Critic. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. ↩︎
-
Xin, S., Jiao, Y., Long, C., Wang, Y., Wang, X., Yang, S., Liu, J., & Zhang, J. (2022). Prototype Feature Extraction for Multi-task Learning. Proceedings of the ACM Web Conference 2022. ↩︎
-
Ma, J., Zhao, Z., Chen, J., Li, A., Hong, L., & Chi, E.H. (2019). SNR: Sub-Network Routing for Flexible Parameter Sharing in Multi-Task Learning. AAAI Conference on Artificial Intelligence. ↩︎ ↩︎
-
Pan, Y., Li, N., Gao, C., Chang, J., Niu, Y., Song, Y., Jin, D., & Li, Y. (2023). Learning and Optimization of Implicit Negative Feedback for Industrial Short-video Recommender System. ArXiv. https://doi.org/10.1145/3583780.3615482 ↩︎
-
Song, J., Jin, B., Yu, Y., Li, B., Dong, X., Zhuo, W., & Zhou, S. (2022). MARS: A Multi-task Ranking Model for Recommending Micro-videos. APWeb/WAIM. ↩︎
-
Lubos, S., Felfernig, A., & Tautschnig, M. (2023). An overview of video recommender systems: state-of-the-art and research issues. Frontiers in Big Data, 6. ↩︎
-
Zhao, Z., Hong, L., Wei, L., Chen, J., Nath, A., Andrews, S., Kumthekar, A., Sathiamoorthy, M., Yi, X., & Chi, E.H. (2019). Recommending what video to watch next: a multitask ranking system. Proceedings of the 13th ACM Conference on Recommender Systems. ↩︎
Related Content





Did you find this article helpful?