An Introduction to Multi-Task Learning based Recommender Systems

Multi-task Learning (MTL) has been widely adopted in domains like Computer Vision, Natural Language Processing, etc. There has also been a significant interest in the recommender systems community to utilize the multi-task learning paradigm. MTL-based approaches model multiple aspects of user behavior to deliver more personalized and relevant recommendations. This article introduces the MTL paradigm in the context of recommender systems and provides a comprehensive review of the existing strategies to build more effective MTL-based recommender systems.
Introduction
Traditional recommender systems model a single task, such as predicting ratings, clicks, etc. These systems do not utilize the shared knowledge contained in related tasks and do not perform well when the training data for their target task is sparse. With Multi-task Learning (MTL) recommendation models can learn multiple related tasks in a unified model to effectively utilize their shared knowledge and achieve mutual improvement.
Why Should You Apply Multi-task Paradigm to Recommenders?
In real-world applications, users exhibit multiple and diverse types of behaviors towards behavior objects (or “items”). For example, on a video-sharing platform like YouTube, a user may engage with a video in different ways, such as clicking, viewing, liking, sharing, commenting, etc. The user may have different levels of propensity towards each of these actions for the given video. A recommender system that only models users’ click behavior may fail to capture true preferences. By adding additional tasks, such as likes, shares, and dwell time, the model can potentially predict user’s short-term intent and long-term interests and content’s engagement trajectory more accurately.
Using MTL techniques in the recommendation domain can lead to the following improvements1.
- Improve Performance: Modeling multiple related factors, for example, click-through rates, completion rates, shares, favorites, etc. gives a multi-faceted perspective of user interest. In an ideal setup, the tasks are also supposed to be mutually beneficial leading to enhanced recommendation performance.
- Promote Generalization: MTL strategies, like learning auxiliary tasks, can bring a regularization effect. This can help reduce overfitting and hence develop a model that is robust and generalizable in a variety of scenarios.
- Mitigate Bias: When learning multiple tasks together, the task with more training data can be instructive for the task with less data. In such cases, the data distribution gap between training and inference space can be reduced, which effectively reduces issues like sample selection bias.
- Handle Data Sparsity: Jointly training the recommender model with a main task and a few auxiliary tasks can also allow the model to capture more informative features and tackle the sparsity of user behavior data for the main task.
- Alleviate Cold Start: By leveraging data from related tasks or domains MTL techniques can alleviate the cold start problem. For example, if a new user does not have any purchase data in the main task, auxiliary tasks like click history, shares, or comments can help in understanding the user preferences.
- Cost-effectiveness: The MTL framework enables parameter sharing and unifying the data pipelines for the different tasks. Therefore, the maintenance cost and computing resources can be greatly reduced.
- Interpretability: Several researchers have also proposed to utilize the task proportions through learned weights of the different tasks to generate explanations for the recommendations.
Despite the above-listed advantages, MTL techniques may also face several challenges, such as complex task relationships, data sparsity, and sequential dependencies in user behavior.
Formal Definition
Assume a dataset $\mathcal{D}$ of $k$-tasks containing $N$ user-item interactions along with the corresponding feature vectors of observed impressions. The dataset can be represented as: $\mathcal{D} := { x_n, (y^{1}{n}, \ldots, y^{k}{n})}_{n=1}^N$. Here, $x_n$ is the concatenation of the $n$-th user-item ID pair and the feature vector. Each record has $y^1,\ldots,y^k$ i.e. $k$ labels corresponding to the $k$ tasks. Our goal is to learn an MTL model with task-specific parameters ${\theta^1,\ldots,\theta^k}$ and shared parameter $\theta^s$. The model outputs $k$ task-wise predictions with a loss function defined as the weighted sum of losses, such as Binary Cross Entropy (BCE).
The optimization problem can be written as2:
$$ \argmin\limits_{\{\theta^1, \ldots, \theta^K\}} \mathcal{L}(\theta^s, \theta^1, \ldots, \theta^K) = \argmin\limits_{\{\theta^1, \ldots, \theta^K\}} \sum_{k=1}^{K} \omega^k L^k(\theta^s, \theta^k) $$
where $\mathcal{L}(\theta^s,\theta^{k})$ is the loss function for $k$-th task with parameters $\theta^{s}, \theta^{k},$ and the $\omega^{k}$ loss weight for the $k$-th task. The objective function can be a linear scalarization of the $k$ losses, or the corresponding loss weights can be updatable and learned. The tasks are usually formulated as score predictions, hence the loss function $L^k(\theta^s, \theta^k)$ for the $k$-th task is generally the BCE loss.
Discovering Task Relations
As we are learning simultaneously from multiple tasks in one network, a strong correlation between multiple tasks will lead to better performance. However, if the tasks are weakly correlated or even irrelevant, it may lead to performance degradation (also called the ‘seesaw phenomenon’). A lot of earlier MTL research assumed the knowledge about the tasks being related. In the absence of such prior knowledge, several research works have proposed automatic task relationship discovery. Hence one way to categorize the existing research in MTL-based recommender systems is to consider how the task relations are modeled.
-
Parallel Task Relations: One MTL strategy is to independently model various tasks without considering the sequential dependency of their results. Such a model usually defines its objective function as the weighted sum of losses with constant loss weights. Some of the research work also uses attention mechanisms to extract general features that will be shared among the tasks. Representative research for this category includes Rank and Rate (RnR)3, Multi-Task Explainable Recommendation (MTER), Co-Attentive Multi-Task Learning (CAML), Deep Item Network for Online Promotions (DINOP), Deep User Perception Network (DUPN), Multiple Relational Attention Network (MRAN)4, Multiple-level Sparse Sharing Mode (MSSM).
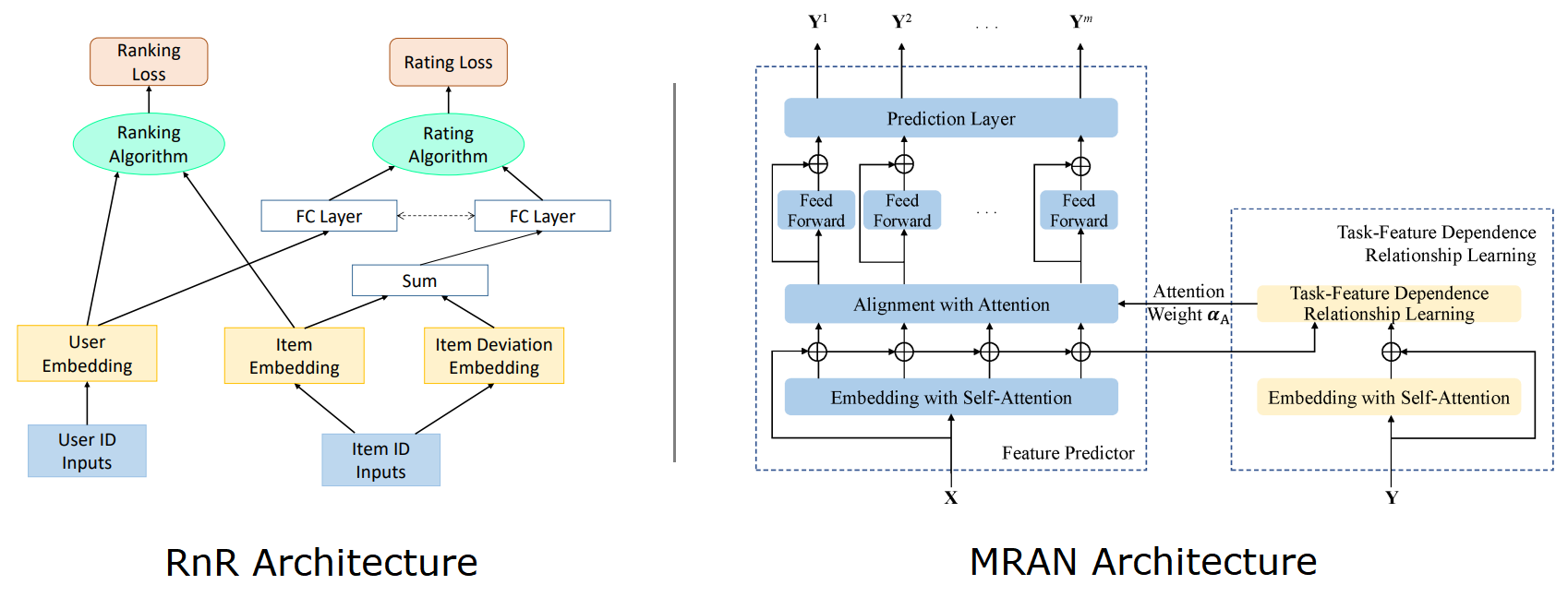
Parallel Task Relations: Example Architectures -
Cascaded Task Relations: Several MTL techniques model the sequential dependency between the tasks such that the computation of the current task depends on the previous one. These models have been adopted in e-commerce, advertising, and financial service domains, and they usually assume sequential patterns based on a behavior pattern, such as “impression $\rightarrow$ click $\rightarrow$ conversion”. Adaptive Pattern Extraction Multi-task (APEM)5, Adaptive Information Transfer Multi-task (AITM), and Entire Space Multi-task Model (ESMM) are some of the representative examples in this category.

Cascaded Task Relations: An example of a sequential dependency in financial domain -
Auxiliary Task Learning: In this MTL technique, one task is defined as the main task, while other associated auxiliary tasks help to improve its performance. During joint optimization of several tasks, it can be difficult to achieve a win-win situation for all tasks. Hence, several MTL techniques aim to enhance the performance of the main task, while sacrificing the performance of auxiliary tasks. Using the entire space with auxiliary tasks enables richer context when estimating the probability of the main task. Research work in this category includes Multi-gate Mixture-of-Experts (MMoE), Progressive Layered Extraction (PLE), Multi-task Inverse Propensity Weighting estimator (Multi-IPW), Multi-task Doubly Robust estimator (Multi-DR), Distillation based Multi-task Learning (DMTL), Multi-task framework for Recommendation over HIN (MTRec), Cross-Task Knowledge Distillation (Cross-Distill), and Contrastive Sharing Recommendation model in MTL learning (CSRec).
Model Architectures
Another way to categorize MTL techniques is to look at the network architectures and learning strategies that have been developed over the years. Next, we will review three categories of MTL research. Note that this is not a strict classification, so some models can be classified into more than one category.
Parameter Sharing
A common MTL strategy is to share parameters in the bottom or tower layers. We classify the parameter-sharing paradigm as shown below.
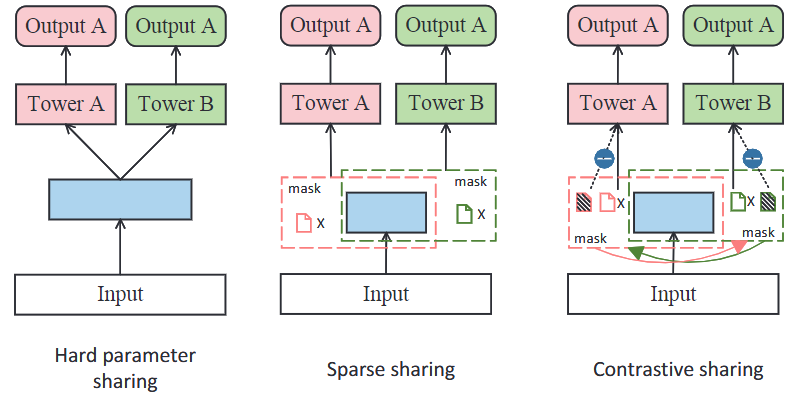
-
Hard Sharing: Hard parameter sharing refers to the shared bottom layers that extract the same information for different tasks. Task-specific layers are then used to extract different features for each task. These models are computationally efficient, can alleviate over-fitting, and tend to perform well when the tasks have strong dependencies. However, the limited sharing degrades performance when tasks are noisy or weakly related. Meta AI’s MetaBalance, Tencent’s Multi-Faceted Hierarchical MTL model (MFH), and Task-wise Adaptive Learning (AdaTask) belong to this category.
-
Sparse Sharing: Sparse parameter sharing is a special case of hard parameter sharing that handles computational and memory inefficiencies, and also flexibly handles the weakly related tasks. This technique connects sub-networks from the shared parameter space using independent parameter masks. With the help of network pruning techniques, each task can then extract the related knowledge for its own subnetwork and avoid the issue of having an excessive number of parameters. Ant Group’s Multiple-level Sparse Sharing Model (MSSM) is one example of this sparse sharing technique.
-
Contrastive Sharing: Sparse parameter sharing methods may still run into negative transfer issues where parameter sharing introduces noise leading to degraded performance for some tasks. A contrastive parameter sharing method, like the Contrastive Sharing Recommendation model (CSRec), has been proposed to address this by only updating the parameters that have more impact on specific tasks. Similar to sparse methods, it learns each task from the subnet using the independent parameter mask, but the contrastive mask is carefully designed to evaluate the contribution of the parameter to a specific task6.
Parameter Sharing Paradigms. Blue represents shared parameters, pink and green represent task-specific parameters. -
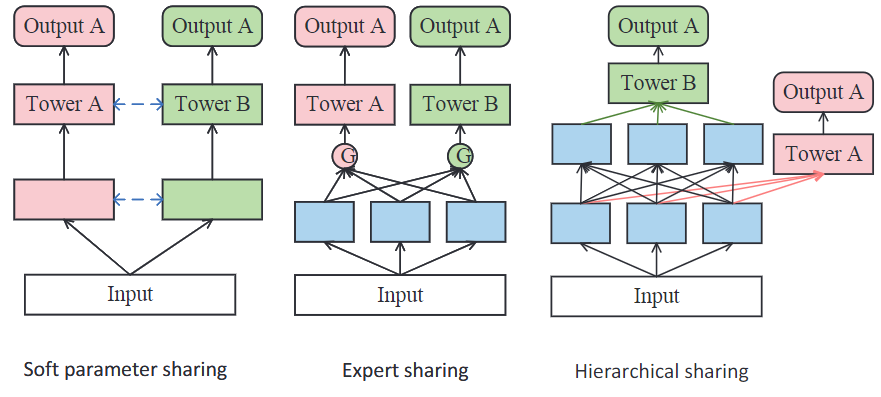
Soft Sharing: Soft parameter sharing methods model different tasks separately and share information between tasks through fusion using relevant weights or attention mechanisms. Compared with the hard sharing strategy, this model architecture offers higher flexibility in parameter sharing but also incurs higher computational costs. Examples of such architecture include Deep Item Network for Online Promotions (DINOP), Gating-enhanced Multi-task Neural Networks (GemNN), Co-Attentive Multi-Task Learning (CAML), Causal Feature Selection Mechanism for Multi-t ask Learning (CFS-MTL), and Multi-objective Risk-aware Route Recommendation (MARRS).
-
Expert Sharing: Expert parameter sharing architecture is a special case of soft sharing that fuses expert knowledge through task-specific weights. It utilizes several expert networks to extract knowledge from the shared bottom layer. Then the knowledge is fed into task-specific modules like gates to learn useful information. Finally, the assembled information is passed into task-specific towers. Multi-gate Mixture-of-Experts (MMoE), and Progressive Layered Extraction (PLE) are some of the popular methods with this architecture. Other examples include Distillation based Multi-task Learning (DMTL), Meta Hybrid Experts and Critics (MetaHeac), Prototype Feature Extraction (PFE), Mixture of Virtual-Kernel Experts (MVKE), Mixture of Sequential Experts (MoSE), Deep Multifaceted Transformers (DMT), and Elaborated Entire Space Supervised Multi-task Model (ESM$^2$).
-
Hierarchical Sharing: To deal with heterogeneous tasks, hierarchical parameter sharing architectures share parts of the network among tasks by putting different tasks in different layers. Designing an effective hierarchical sharing architecture can be time-consuming. Some of the representative research work in this category include the Multi-Faceted Hierarchical MTL model (MFH), and Hierarchical Multi-Task Graph Recurrent Network (HMT-GRN).
Other Architectures
The majority of MTL-based recommender systems follow the parameter-sharing architecture described above. However, there are also a few alternate architectures, such as adversarial learning. Models like CnGAN and CLOVER introduce Generative Adversarial Network (GAN) based recommender models that utilize MTL techniques. There are also a few Reinforcement Learning (RL) based MTL models, such as the Batch Reinforcement Learning based Multi-Task Fusion framework (BatchRL-MTF), that have been proposed to build recommender systems.
Negative Transfer
During joint optimization, transferring unrelated information among tasks can also result in performance degradation and a seesaw phenomenon. In such cases, the performance of a task or a subset of tasks gets improved at the cost of others’ results. A common materialization of negative transfer can be observed through Gradient Conflicts. Gradient conflict refers to a scenario where the gradient directions of different tasks form an angle greater than 90 degrees. Several gradient correction approaches, like Projecting Conflicting Gradients (PCGrad), and Conflict-Averse Gradient Descent (CAGrad) have been proposed to alleviate this problem. Models like Progressive Layered Extraction (PLE), and Contrastive Sharing Recommendation model in MTL learning (CSRec) also propose custom solutions. Gradient magnitudes of the different tasks may also vary significantly, which can lead to performance degradation. Methods like Gradient Normalization (GradNorm) and MetaBalance help in controlling the gradient magnitudes. Task-wise Adaptive Learning (AdaTask) model also proposed adaptive learning solutions.
Similar to negative transfer, another multi-objective problem is the tuning of loss weights. A common MTL strategy is to combine the loss values from multiple tasks by taking a weighted sum of the losses. The importance of a specific task, among all other tasks, can be tuned by changing the loss weight corresponding to the task. Designing an automated task-balancing mechanism to weigh task losses can be challenging.
Future Research Directions
In this section, we take a look at some of the newer research directions that are being explored for MTL-based recommender systems.
- Multi-task Fusion: Several researchers have proposed sophisticated methods to optimally combine the outputs of different tasks. Methods like Genetic Algorithms, Bayesian Optimization, and Reinforcement Learning have been investigated for multi-task fusion.
- Explainability: There have been several efforts to generate explanations to interpret the recommendations. Usually, the goal here is to improve transparency and user statisfaction. Explanation generation can be one of the multiple tasks learned alongside recommendation tasks. Alternatively, a knowledge graph can be employed to assist generative explanations.
- AutoML: Designing and tuning an MTL-based system can be exhausting. Several automated machine learning approaches, like Neural Architecture Search (NAS), have tried to automatically find flexible parameter-sharing architectures.
Other research directions include ensuring fairness, and scalability, and utilizing large pre-trained models.
Summary
Multi-task learning (MTL) has garnered significant interest in the recommender systems community. This article provided an overview and classification of the existing research works that build MTL-based recommenders. In a future article, we will go more in-depth and learn from MTL-based industrial-scale recommender system implementations that target specific applications.
References
-
Zhang, M., Yin, R., Yang, Z., Wang, Y., & Li, K. (2023). Advances and Challenges of Multi-task Learning Method in Recommender System: A Survey. ArXiv. /abs/2305.13843 ↩︎
-
Wang, Y., Lam, H. T., Wong, Y., Liu, Z., Zhao, X., Wang, Y., Chen, B., Guo, H., & Tang, R. (2023). Multi-Task Deep Recommender Systems: A Survey. ArXiv. /abs/2302.03525 ↩︎
-
Hadash, G., Shalom, O. S., & Osadchy, R. (2018). Rank and Rate: Multi-task Learning for Recommender Systems. ArXiv. https://doi.org/10.1145/3240323.3240406 ↩︎
-
Zhao, J., Du, B., Sun, L., Zhuang, F., Lv, W., & Xiong, H. (2019). Multiple Relational Attention Network for Multi-task Learning. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ↩︎
-
Tao, X., Ha, M., Guo, X., Ma, Q., Cheng, H., & Lin, W. (2023). Adaptive Pattern Extraction Multi-Task Learning for Multi-Step Conversion Estimations. ArXiv. /abs/2301.02494 ↩︎
-
Bai, T., Xiao, Y., Wu, B., Yang, G., Yu, H., & Nie, J. (2022). A Contrastive Sharing Model for Multi-Task Recommendation. Proceedings of the ACM Web Conference 2022. ↩︎
Related Content





Did you find this article helpful?